
Mobilediffusion: génération rapide de texte à l’image sur les appareils
- Intelligence Artificielle
 Noesis News
Noesis News- 0
- 25 minutes de lecture




Texte à l’image modèles de diffusion ont montré des capacités exceptionnelles dans la génération d’images de haute qualité à partir d’invites de texte. Cependant, les modèles principaux comportent des milliards de paramètres et sont donc coûteux à exécuter, nécessitant de puissants ordinateurs de bureau ou serveurs (par exemple, Diffusion stable, Dall · eet Image). Tandis que les progrès récents dans les solutions d’inférence sur Androïde via medipipe et ios Via Core ML a été fabriqué au cours de la dernière année, la génération rapide (sous-seconde) de texte à l’image sur les appareils mobiles est restée hors de portée.
À cette fin, dans «Mobilediffusion: Génération de texte à l’image sur seconde sur les appareils mobiles», Nous introduisons une nouvelle approche avec le potentiel de génération rapide de la génération de texte à l’image. Mobilediffusion est un modèle de diffusion latent efficace spécialement conçu pour les appareils mobiles. Nous adoptons également Diffusion. Pour obtenir un échantillonnage en une étape pendant l’inférence, qui affine un modèle de diffusion pré-formé tout en tirant parti d’un GaN pour modéliser l’étape de débraillage. Nous avons testé Mobilediffusion sur les appareils IOS et Android Premium, et il peut fonctionner en une demi-seconde pour générer une image de haute qualité 512×512. Sa taille de modèle relativement petite de seulement 520 m de paramètres le rend particulièrement adapté au déploiement mobile.
 |
 |
| Génération rapide du texte à l’image sur les appareils. |
Arrière-plan
L’inefficacité relative des modèles de diffusion de texte à l’image provient de deux défis principaux. Premièrement, la conception inhérente des modèles de diffusion nécessite débraillé itératif Pour générer des images, nécessitant plusieurs évaluations du modèle. Deuxièmement, la complexité de l’architecture du réseau dans les modèles de diffusion de texte à l’image implique un nombre important de paramètres, atteignant régulièrement les milliards et entraînant des évaluations coûteuses par calcul. En conséquence, malgré les avantages potentiels du déploiement de modèles génératifs sur les appareils mobiles, tels que l’amélioration de l’expérience utilisateur et la lutte contre les problèmes de confidentialité émergents, il reste relativement inexploré dans la littérature actuelle.
L’optimisation de l’efficacité d’inférence dans les modèles de diffusion de texte à l’image a été un domaine de recherche actif. Des études antérieures se concentrent principalement sur la relevée du premier défi, cherchant à réduire le nombre d’évaluations de fonction (NFES). Tirant parti des résolveurs numériques avancés (par exemple, DPM) ou techniques de distillation (par exemple, distillation progressive, distillation de cohérence), le nombre d’étapes d’échantillonnage nécessaires a considérablement réduit de plusieurs centaines à un seul chiffre. Quelques techniques récentes, comme Diffusion. et Distillation de diffusion adversairemême réduire à une seule étape nécessaire.
Cependant, sur les appareils mobiles, même un petit nombre d’étapes d’évaluation peut être lente en raison de la complexité de l’architecture du modèle. Jusqu’à présent, l’efficacité architecturale des modèles de diffusion de texte à l’image a reçu relativement moins d’attention. Une poignée de travaux antérieurs abordent brièvement cette question, impliquant la suppression des blocs de réseau de neurones redondants (par exemple, Snapfusion). Cependant, ces efforts n’ont pas d’analyse complète de chaque composant au sein de l’architecture du modèle, ne répondant pas à un guide holistique pour concevoir des architectures très efficaces.
Mobilediffusion
Surmonter efficacement les défis imposés par la puissance de calcul limitée des appareils mobiles nécessite une exploration approfondie et holistique de l’efficacité architecturale du modèle. Dans la poursuite de cet objectif, notre recherche entreprend un examen détaillé de chaque constituant et opération de calcul au sein de la diffusion stable Architecture de l’ONE. Nous présentons un guide complet pour l’élaboration de modèles de diffusion de texte à l’image très efficaces qui aboutissaient à la mobilediffusion.
La conception de Mobilediffusion suit celle de Modèles de diffusion latente. Il contient trois composants: un encodeur de texte, une diffusion Unet et un décodeur d’image. Pour l’encodeur de texte, nous utilisons Clip-Vit / L14qui est un petit modèle (paramètres 125 m) adapté au mobile. Nous tournons ensuite notre attention vers la diffusion Unet et le décodeur d’images.
Diffusion Unet
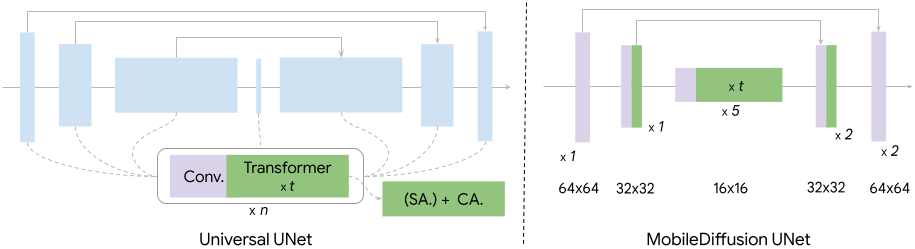
Comme illustré dans la figure ci-dessous, la diffusion UnEts délasse généralement les blocs de transformateurs et les blocs de convolution. Nous mettons une enquête approfondie sur ces deux blocs de construction fondamentaux. Tout au long de l’étude, nous contrôlons le pipeline d’entraînement (par exemple, les données, Optimiseur) pour étudier les effets de différentes architectures.
Dans les modèles classiques de diffusion de texte à image, un bloc de transformateur se compose d’une couche d’auto-agencement (SA) pour modéliser les dépendances à longue portée entre les caractéristiques visuelles, une couche transversale (CA) pour capturer les interactions entre le conditionnement du texte et les caractéristiques visuelles, et une couche d’alimentation (FF) pour post-transformation de la sortie des couches d’attention. Ces blocs de transformateurs détiennent un rôle pivot dans les modèles de diffusion de texte à l’image, servant de composants principaux responsables de la compréhension du texte. Cependant, ils posent également un défi d’efficacité significatif, étant donné les dépenses de calcul de l’opération d’attention, qui est quadratique à la longueur de séquence. Nous suivons l’idée de Uvit Architecture, qui place plus de blocs de transformateurs au goulot d’étranglement de l’UNET. Ce choix de conception est motivé par le fait que le calcul de l’attention est moins à forte intensité de ressources au niveau du goulot d’étranglement en raison de sa dimensionnalité plus faible.
 |
| Notre architecture UNE intègre plus de transformateurs au milieu et saute les couches d’auto-atténuer (SA) à des résolutions plus élevées. |
Blocs de convolution, en particulier Resnet Les blocs sont déployés à chaque niveau de l’UNET. Bien que ces blocs soient déterminants pour l’extraction des caractéristiques et le flux d’informations, les coûts de calcul associés, en particulier à des niveaux à haute résolution, peuvent être substantiels. Une approche éprouvée dans ce contexte est Convolution séparable. Nous avons observé que le remplacement des couches de convolution régulières par des couches de convolution séparables légères dans les segments plus profonds de l’UNED donne des performances similaires.
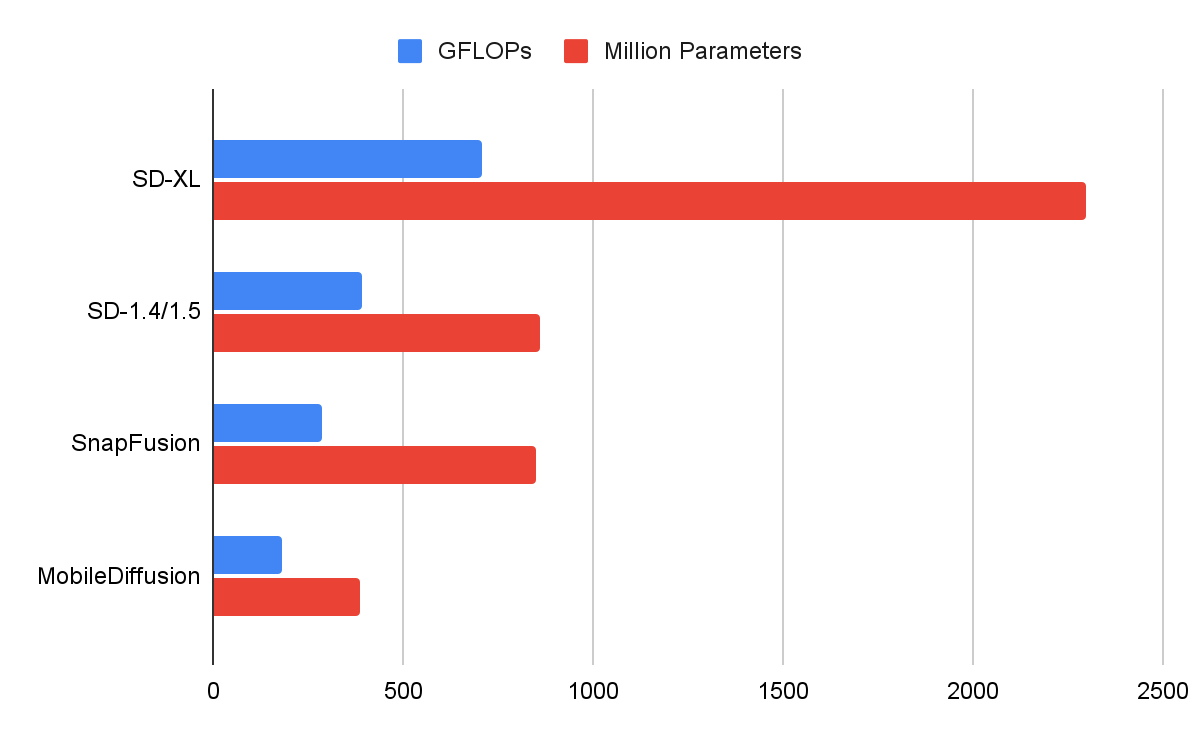
Dans la figure ci-dessous, nous comparons les MNU de plusieurs modèles de diffusion. Notre mobilediffusion présente une efficacité supérieure en termes de Flops (opérations à virgule flottante) et le nombre de paramètres.
 |
| Comparaison de certaines diffusion non. |
Décodeur d’image
En plus de l’ONU, nous avons également optimisé le décodeur d’image. Nous avons formé un autoencodeur variationnel (Vae) pour coder un RVB Image d’une variable latente à 8 canaux, avec une taille spatiale 8 × plus petite de l’image. Une variable latente peut être décodée sur une image et obtient 8 × plus grande. Pour améliorer encore l’efficacité, nous concevons une architecture de décodeur légère en élaguant la largeur et la profondeur de l’original. Le décodeur léger qui en résulte entraîne une augmentation significative des performances, avec une amélioration de près de 50% de latence et une meilleure qualité. Pour plus de détails, veuillez consulter notre papier.
 |
| Reconstruction VAE. Nos décodeurs VAE ont une meilleure qualité visuelle que SD (diffusion stable). |
| Décodeur | #Params (M) | PSNR ↑ | Ssim ↑ | LPIPS ↓ |
| SD | 49.5 | 26.7 | 0,76 | 0,037 |
| La nôtre | 39.3 | 30.0 | 0,83 | 0,032 |
| Nôtre-lite | 9.8 | 30.2 | 0,84 | 0,032 |
Échantillonnage en une étape
En plus d’optimiser l’architecture du modèle, nous adoptons un Hybride de diffusion pour obtenir un échantillonnage en une étape. Formation Modèles hybrides de diffusion pour la génération de texte à l’image rencontre plusieurs subtilités. Notamment, le discriminateur, un classificateur distinguant les données réelles et les données générées, doit porter des jugements basés sur la texture et la sémantique. De plus, le coût de la formation des modèles de texte à l’image peut être extrêmement élevé, en particulier dans le cas des modèles GAN, où le discriminateur introduit des paramètres supplémentaires. Modèles de texte à l’image purement basés sur Gan (par exemple, Stylegan-t, Gigagan) confronter des complexités similaires, entraînant une formation très complexe et coûteuse.
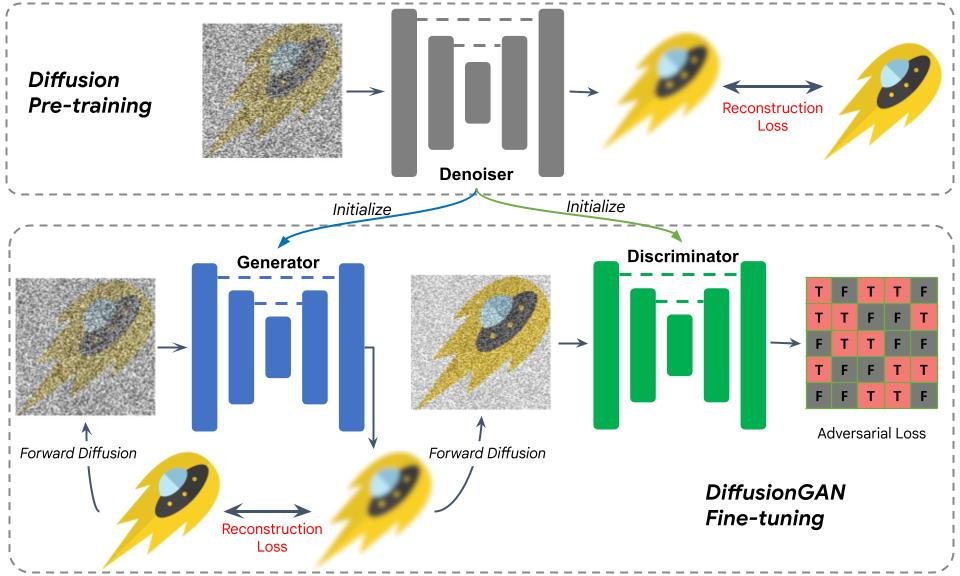
Pour surmonter ces défis, nous utilisons une diffusion pré-formée UnET pour initialiser le générateur et le discriminateur. Cette conception permet une initialisation transparente avec le modèle de diffusion pré-formé. Nous postulons que les caractéristiques internes du modèle de diffusion contiennent des informations riches de l’interaction complexe entre les données textuelles et visuelles. Cette stratégie d’initialisation rationalise considérablement la formation.
La figure ci-dessous illustre la procédure de formation. Après initialisation, une image bruyante est envoyée au générateur pour une diffusion en une étape. Le résultat est évalué contre la vérité du sol avec une perte de reconstruction, similaire à la formation du modèle de diffusion. Nous ajoutons ensuite du bruit à la sortie et l’envoyons au discriminateur, dont le résultat est évalué avec une perte de GaN, adoptant efficacement le GAn pour modéliser une étape de débrassement. En utilisant des poids pré-formés pour initialiser le générateur et le discriminateur, la formation devient un processus de réglage fin, qui converge en moins de 10 000 itérations.
 |
| Illustration du réglage fin de diffusion. |
Résultats
Ci-dessous, nous montrons des exemples d’images générées par notre mobilediffusion avec un échantillonnage en une étape de diffusion. Avec un modèle aussi compact (paramètres de 520 m au total), Mobilediffusion peut générer des images diverses de haute qualité pour divers domaines.
 |
| Images générées par notre mobilediffusion |
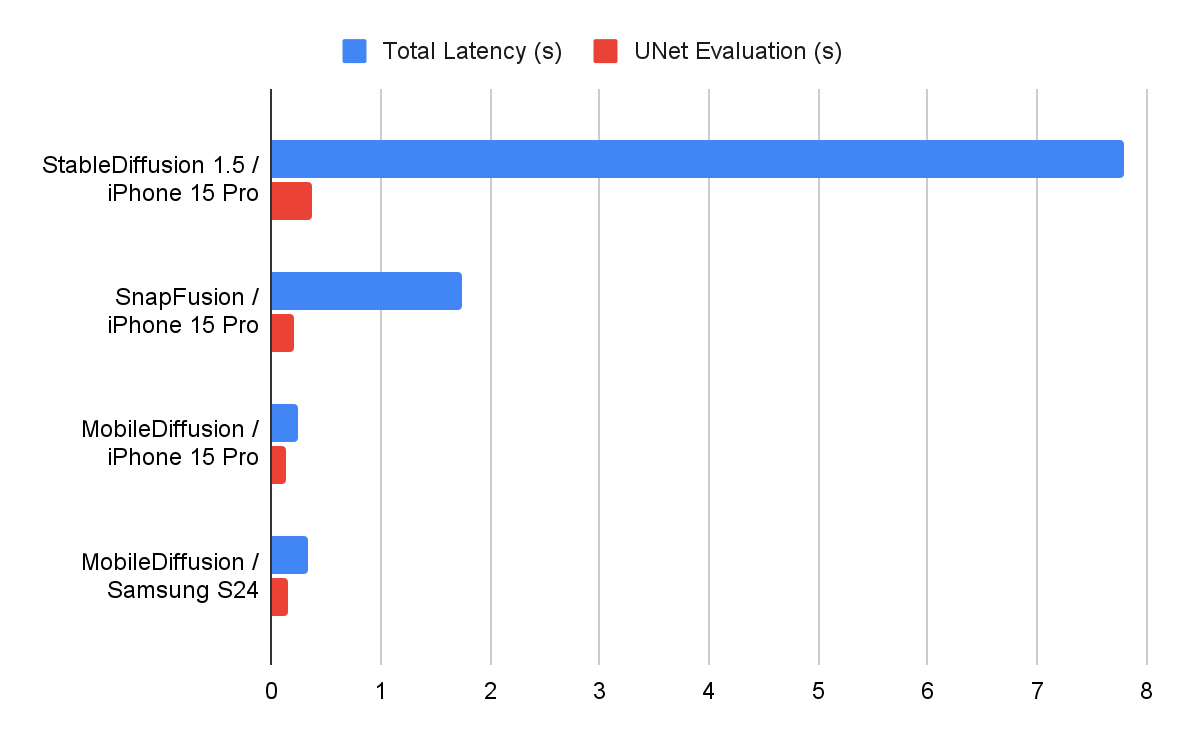
Nous avons mesuré les performances de notre mobilediffusion sur les appareils iOS et Android, en utilisant différents optimisateurs d’exécution. Les numéros de latence sont signalés ci-dessous. Nous voyons que Mobilediffusion est très efficace et peut fonctionner dans une demi-seconde pour générer une image 512×512. Cette vitesse de foudre permet potentiellement de nombreux cas d’utilisation intéressants sur les appareils mobiles.
 |
| Mesures de latence (s) sur les appareils mobiles. |
Conclusion
Avec une efficacité supérieure en termes de latence et de taille, Mobilediffusion a le potentiel d’être une option très conviviale pour les déploiements mobiles étant donné sa capacité à permettre une expérience rapide de génération d’images tout en tapant des invites de texte. Et nous nous assurerons que toute application de cette technologie sera en ligne avec Google Pratiques d’IA responsables.
Remerciements
Nous aimons remercier nos collaborateurs et contributeurs qui ont contribué à mettre le mobilediffusion à périphérique: Zhisheng Xiao, Yanwu Xu, Jiuqiang Tang, Haolin Jia, Lutz Justen, Daniel Fenner, Ronald Wotzlaw, Jianing Wei, Raman Sarokin, Muyun Lee, Andrei Kulik, Chuo -ling Chang.
Source link



