
La référence visuelle des backs de foin! – Le blog de recherche de l’intelligence artificielle de Berkeley
- Intelligence Artificielle
 Noesis News
Noesis News- 0
- 21 minutes de lecture

Les humains excellent dans le traitement de vastes tableaux d’informations visuelles, une compétence cruciale pour réaliser l’intelligence générale artificielle (AGI). Au fil des décennies, les chercheurs d’IA ont développé des systèmes de réponse aux questions visuelles (VQA) pour interpréter des scènes dans des images uniques et répondre aux questions liées. Alors que les progrès récents dans les modèles de fondation ont considérablement réduit l’écart entre le traitement visuel humain et la machine, le VQA conventionnel a été limité à la raison célibataire images à la fois plutôt que des collections entières de données visuelles.
Cette limitation pose des défis dans des scénarios plus complexes. Prenons, par exemple, les défis des modèles de discernement dans les collections d’images médicales, la surveillance de la déforestation via l’imagerie satellite, la cartographie des changements urbains en utilisant des données de navigation autonomes, l’analyse des éléments thématiques à travers de grandes collections d’art ou la compréhension du comportement des consommateurs à partir de séquences de surveillance de la vente au détail. Chacun de ces scénarios implique non seulement un traitement visuel sur des centaines ou des milliers d’images, mais nécessite également un traitement croisé de ces résultats. Pour combler cet écart, ce projet se concentre sur la tâche de «réponse aux questions multi-images» (MIQA), qui dépasse la portée des systèmes VQA traditionnels.
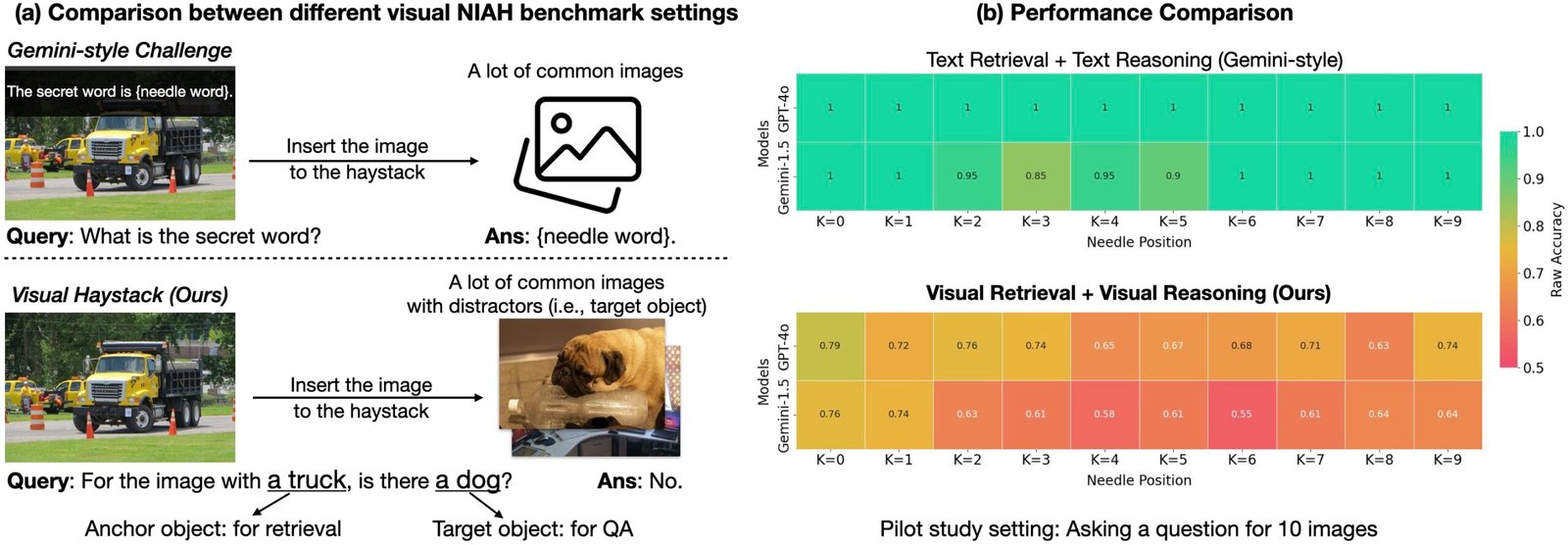
Backs de foin visuels: La première référence à l’aiguille « visuelle » visuelle « (NIAH) conçue pour évaluer rigoureusement les grands modèles multimodaux (LMM) dans le traitement des informations visuelles en contexte à long contexte.
Comment comparer les modèles VQA sur MIQA?
Le défi «aiguille dans un haystack» (NIAH) est récemment devenu l’un des paradigmes les plus populaires pour la capacité de Benchmarking LLM à traiter les entrées contenant des «contextes longs», de grands ensembles de données d’entrée (telles que des documents longs, des vidéos ou des centaines d’images). Dans cette tâche, des informations essentielles («l’aiguille»), qui contient la réponse à une question spécifique, est intégrée dans une grande quantité de données («la botte de foin»). Le système doit ensuite récupérer les informations pertinentes et répondre correctement à la question.
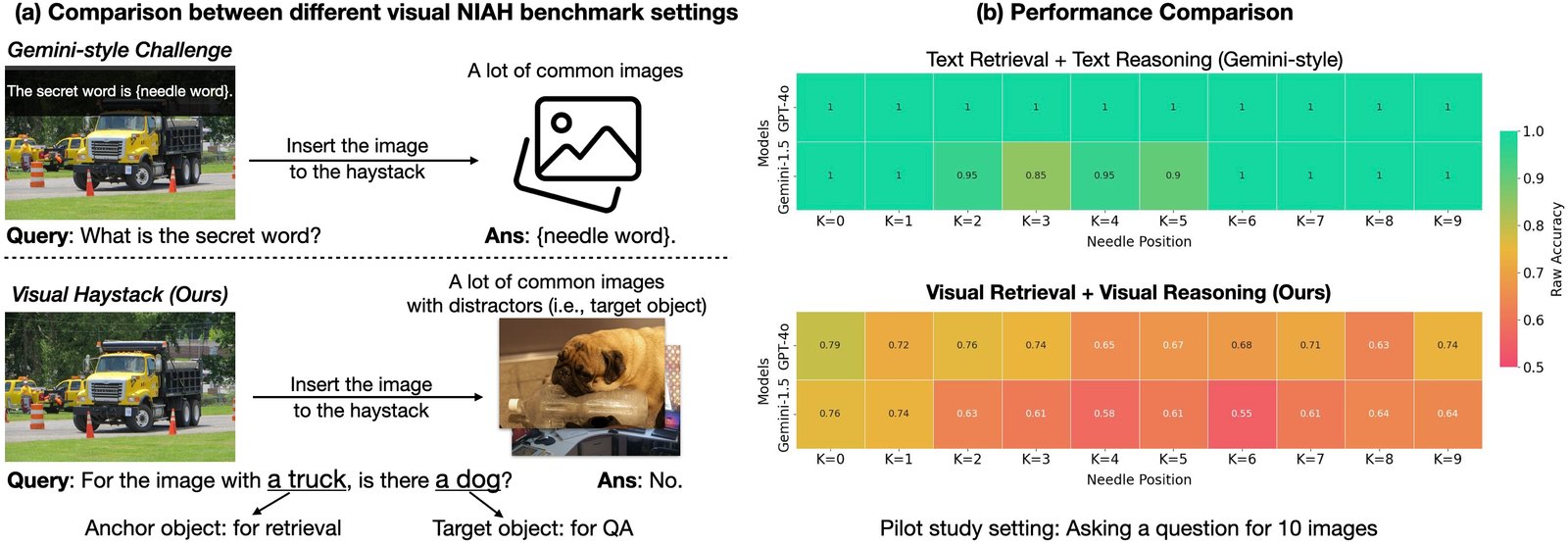
La première référence Niah pour le raisonnement visuel a été introduite par Google dans le gemini-v1.5 rapport technique. Dans ce rapport, ils ont demandé à leurs modèles de récupérer du texte superposé sur une seule image dans une grande vidéo. Il s’avère que les modèles existants fonctionnent assez bien sur cette tâche, principalement en raison de leurs fortes capacités de récupération de l’OCR. Mais que se passe-t-il si nous posons plus de questions visuelles? Les modèles fonctionnent-ils aussi?
Qu’est-ce que la référence Visual Haystacks (VHS)?
Dans la poursuite de l’évaluation des capacités de raisonnement à long contexte «visuelles», nous introduisons la référence «Visual Haystacks (VHS)». Cette nouvelle référence est conçue pour évaluer les grands modèles multimodaux (LMMS) dans Visual récupération et raisonnement à travers de grands ensembles d’images non corrélés. VHS dispose d’environ 1k paires de questions binaires de 1K, chaque ensemble contenant des images de 1 à 10 km. Contrairement aux repères précédents qui se sont concentrés sur la récupération et le raisonnement textuel, les questions VHS se concentrent sur l’identification de la présence de contenu visuel spécifique, tels que des objets, l’utilisation d’images et d’annotations de l’ensemble de données CoCo.
La référence VHS est divisée en deux défis principaux, chacun conçu pour tester la capacité du modèle à localiser et analyser avec précision les images pertinentes avant de répondre aux requêtes. Nous avons soigneusement conçu l’ensemble de données pour nous assurer que deviner ou s’appuyer sur le raisonnement de bon sens sans afficher l’image n’obtiendra aucun avantage (c’est-à-dire, ce qui entraîne un taux de précision de 50% sur une tâche de QA binaire).
-
Défi unique: Une seule image d’aiguille existe dans la botte de foin des images. La question est encadrée comme: «Pour l’image avec l’objet d’ancrage, y a-t-il un objet cible?»
-
Défi à plusieurs reprises: Deux à cinq images d’aiguille existent dans la botte de foin des images. La question est encadrée comme «pour toutes les images avec l’objet d’ancrage, elles contiennent toutes l’objet cible?» ou « Pour toutes les images avec l’objet d’ancrage, l’un d’eux contiennent-ils l’objet cible? »
Trois résultats importants de VHS
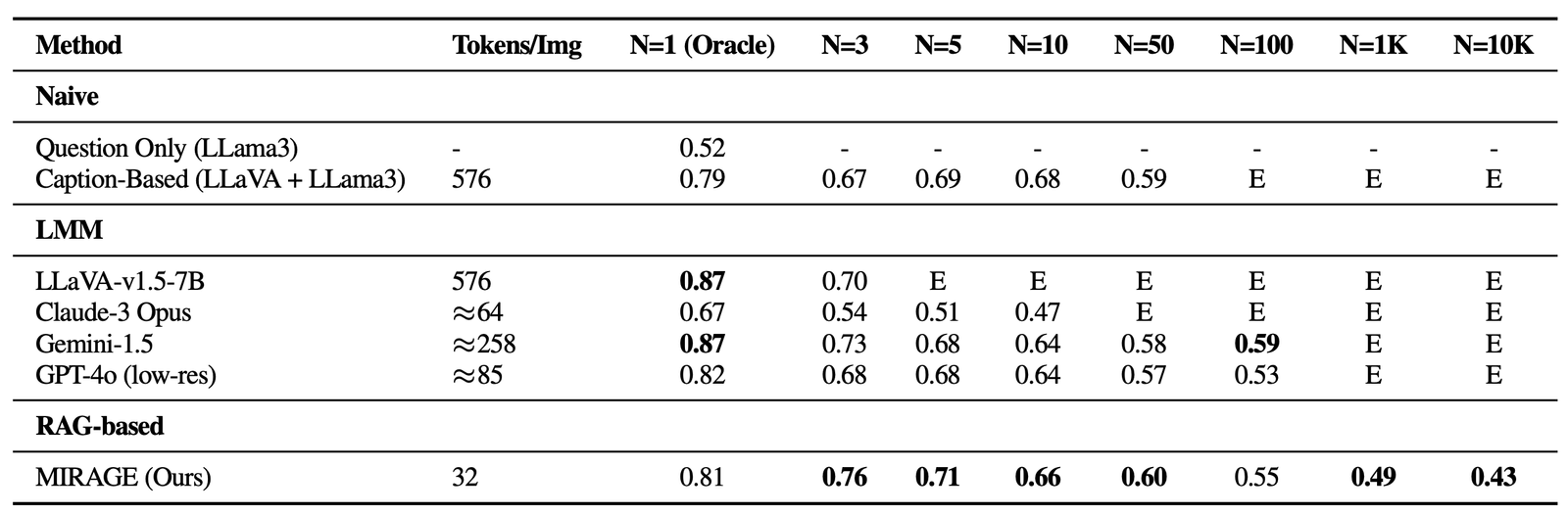
La référence Visual Haystacks (VHS) révèle des défis importants auxquels sont confrontés les grands modèles multimodaux actuels (LMM) lors du traitement des entrées visuelles étendues. Dans nos expériences Dans les modes simples et multi-finaux, nous avons évalué plusieurs méthodes open source et propriétaires, notamment Llava-v1.5, GPT-4O, Claude-3 Opuset Gemini-v1.5-pro. De plus, nous incluons une ligne de base «sous-titrante», en utilisant une approche en deux étapes où les images sont initialement sous-titrées à l’aide de Llava, suivie en répondant à la question en utilisant le contenu texte des légendes avec Lama3. Vous trouverez ci-dessous trois idées charnières:
-
Lutte avec les distracteurs visuels
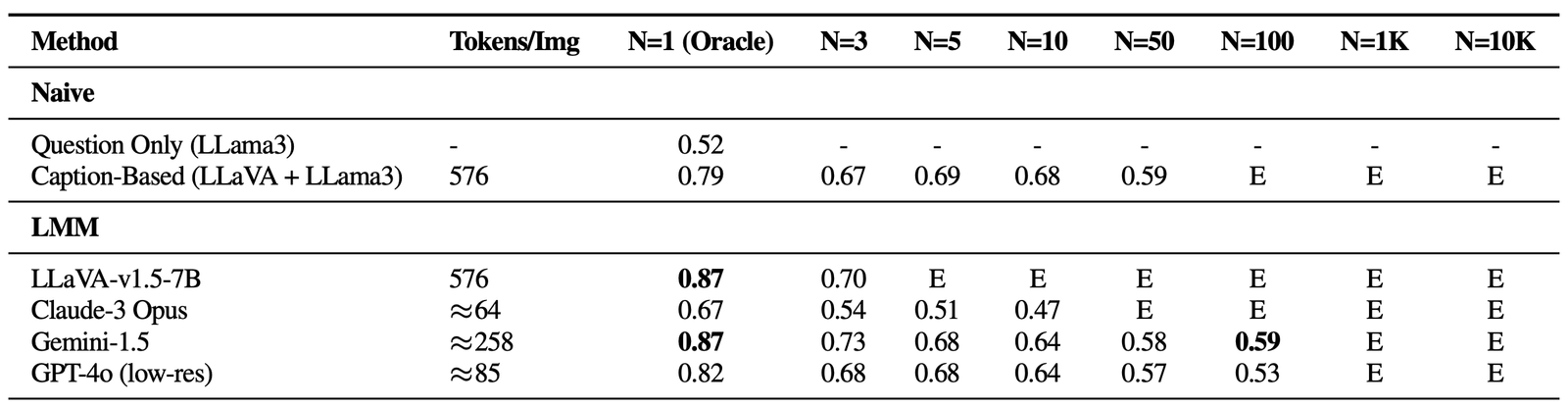
Dans les paramètres d’une seule aiguille, une baisse notable des performances a été observée à mesure que le nombre d’images a augmenté, malgré le maintien d’une précision d’oracle élevée – un scénario absent dans les références de style gemini-basé sur le texte. Cela montre que les modèles existants peuvent principalement lutter contre la récupération visuelle, en particulier en présence de distracteurs visuels difficiles. En outre, il est crucial de mettre en évidence les contraintes sur les LMM open source comme Llava, qui ne peuvent gérer que jusqu’à trois images en raison d’une limite de longueur de contexte 2K. D’un autre côté, des modèles propriétaires tels que GEMINI-V1.5 et GPT-4O, malgré leurs revendications de capacités de contexte étendues, ne parviennent souvent pas à gérer les demandes lorsque le nombre d’images dépasse 1k, en raison des limites de taille de charge utile lors de l’utilisation de l’appel API.
Performance sur VHS pour les questions d’une seule aiguille. Tous les modèles connaissent des retombées significatives à mesure que la taille de la botte de foin (N) augmente, ce qui suggère qu’aucun d’entre eux n’est robuste contre les distracteurs visuels. E: dépasse la longueur du contexte. -
Raisonnement de difficulté sur plusieurs images
Fait intéressant, toutes les méthodes basées sur LMM ont montré des performances faibles avec plus de 5 images dans un QA à image unique et tous les paramètres à plusieurs aiguilles par rapport à une approche de base tracant un modèle de sous-titrage (LLAVA) avec un agrégateur LLM (LLAMA3). Cet écart suggère que si les LLM sont capables d’intégrer efficacement les légendes à long contexte, les solutions basées sur LMM existantes sont inadéquates pour traiter et intégrer des informations sur plusieurs images. Notamment, les performances se détériorent énormément dans les scénarios multi-images, avec Claude-3 Opus montrant des résultats faibles avec uniquement des images Oracle, et Gemini-1.5 / GPT-4O tombant à 50% de précision (tout comme une supposition aléatoire) avec des ensembles plus importants de 50 images.
Résultats sur VHS pour les questions à plusieurs redevances. Tous les modèles visuellement consacrés à des performances visuelles, ce qui indique que les modèles trouvent difficile d’intégrer implicitement des informations visuelles. -
Phénomènes dans le domaine visuel
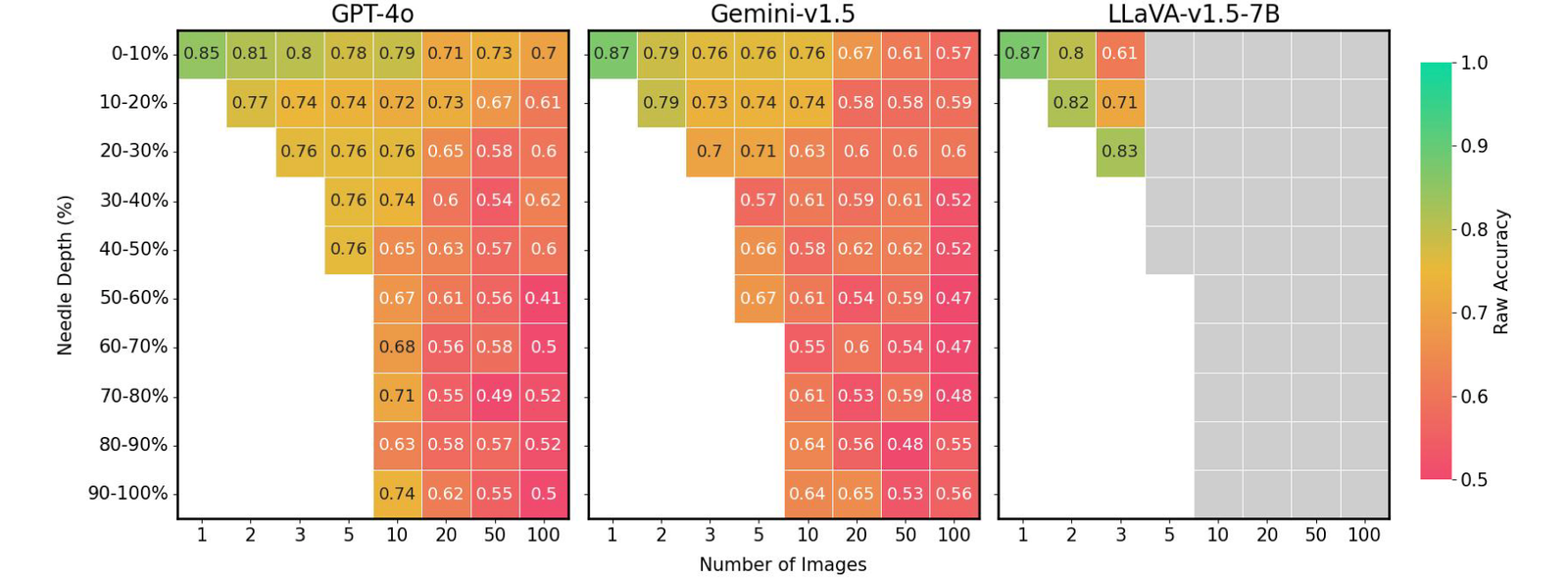
Enfin, nous avons constaté que la précision des LMM est extrêmement affectée par la position de l’image de l’aiguille dans la séquence d’entrée. Par exemple, Llava montre de meilleures performances lorsque l’image de l’aiguille est placée immédiatement avant la question, souffrant d’une baisse de 26,5% autrement. En revanche, les modèles propriétaires fonctionnent généralement mieux lorsque l’image est positionnée au début, connaissant jusqu’à une diminution jusqu’à une diminution de 28,5% du cas. Ce modèle fait écho au « Perdu dans le milieu » Le phénomène observé dans le domaine du traitement du langage naturel (PNL), où des informations cruciales positionnées au début ou à la fin du contexte influencent la performance du modèle. Cette question n’était pas évidente dans l’évaluation précédente de la NIAH de style gemini, qui ne nécessitait que la récupération et le raisonnement de texte, soulignant les défis uniques posés par notre référence VHS.
Position de l’aiguille par rapport aux performances sur VHS pour divers paramètres d’image. Les LMM existants apparaissent jusqu’à 41% de performances lorsque l’aiguille n’est pas idéalement placée. Boîtes grises: dépasse la longueur du contexte.
Mirage: une solution basée sur des chiffons pour améliorer les performances VHS
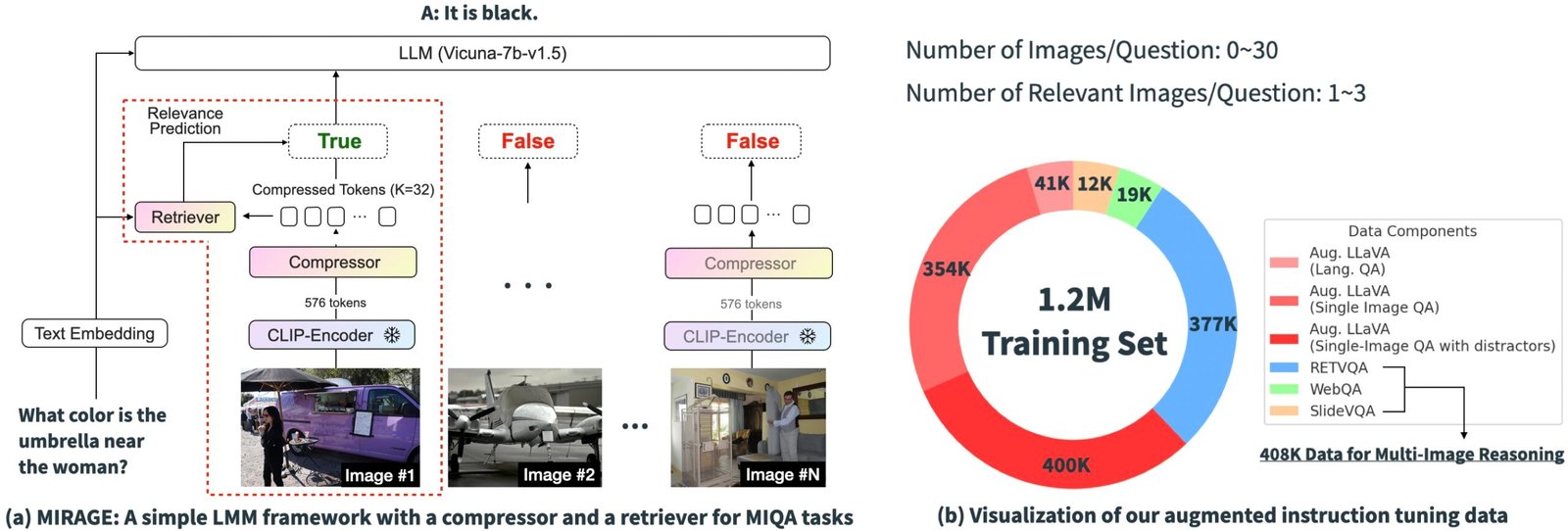
Sur la base des résultats expérimentaux ci-dessus, il est clair que les défis principaux des solutions existantes dans la MIQA se trouvent dans la capacité de (1) avec précision récupérer Images pertinentes à partir d’un vaste bassin d’images potentiellement non liées sans biais de position et (2) intégrer Informations visuelles pertinentes de ces images pour répondre correctement à la question. Pour résoudre ces problèmes, nous introduisons un paradigme de formation à une source ouverte et simple, «Mirage» (génération augmentée de récupération multi-images), qui étend le Llave Modèle pour gérer les tâches MIQA. L’image ci-dessous montre notre architecture de modèle.
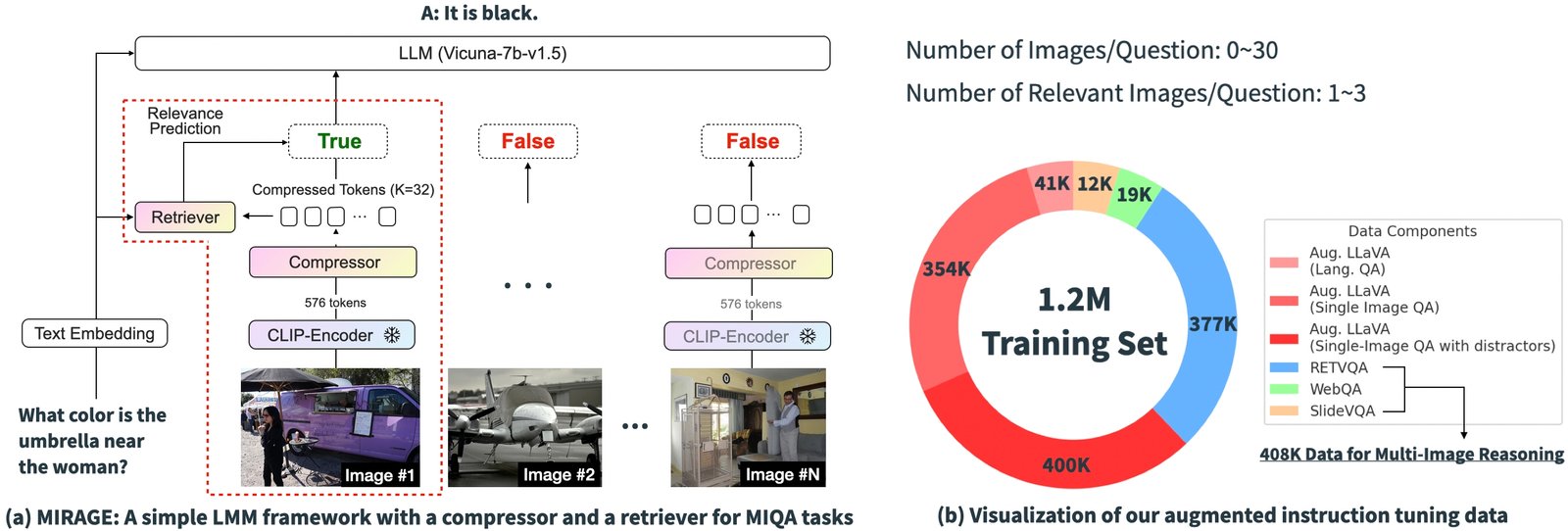
Notre paradigme proposé se compose de plusieurs composants, chacun conçu pour atténuer les problèmes clés de la tâche MIQA:
-
Comprimer les encodages existants: Le paradigme Mirage exploite un modèle de compression de la requête pour réduire les jetons d’encodeur visuels à un sous-ensemble plus petit (10x plus petit), permettant plus d’images dans la même longueur de contexte.
-
Employer Retriever pour filtrer le message non pertinent: MIRAGE utilise un retriever formé en ligne avec le réglage fin LLM, pour prédire si une image sera pertinente et déposera dynamiquement des images non pertinentes.
-
Données de formation multi-images: MIRAGE augmente les données d’exécution existantes de réglage des instructions à image unique avec des données de raisonnement multi-images et des données de raisonnement multi-image synthétiques.
Résultats
Nous revisitons la référence VHS avec Mirage. En plus d’être capable de gérer des images 1K ou 10K, Mirage atteint des performances de pointe sur la plupart des tâches à aiguille unique, malgré une colonne vertébrale AQ à l’image unique plus faible avec seulement 32 jetons par image!
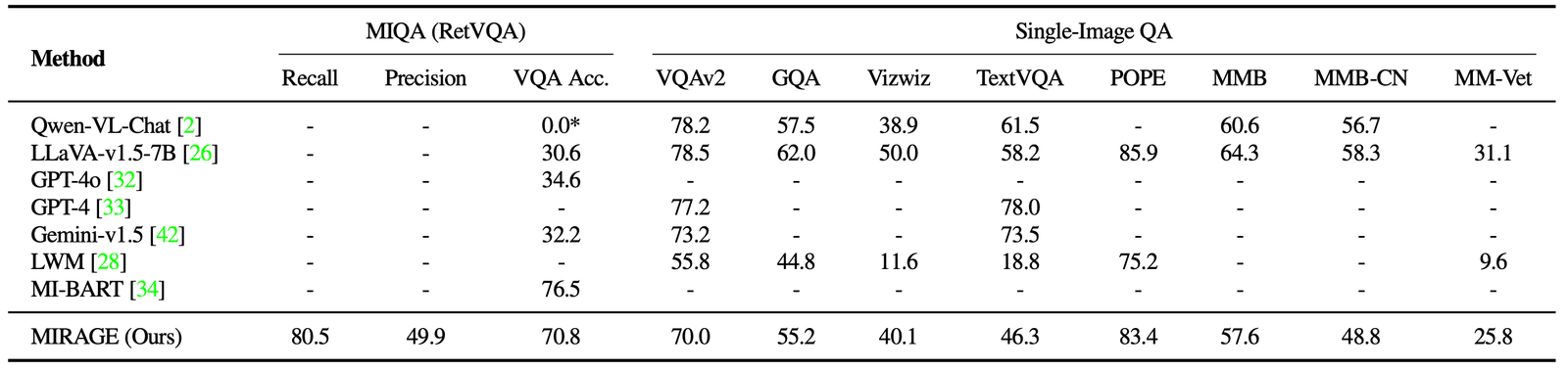
Nous analysons également le mirage et d’autres modèles basés sur LMM sur une variété de tâches VQA. Sur les tâches multi-images, Mirage démontre de fortes capacités de rappel et de précision, surpassant considérablement de forts concurrents comme GPT-4, GEMINI-V1.5 et le Modèle du grand monde (LWM). De plus, il montre des performances de QA à image unique compétitives.
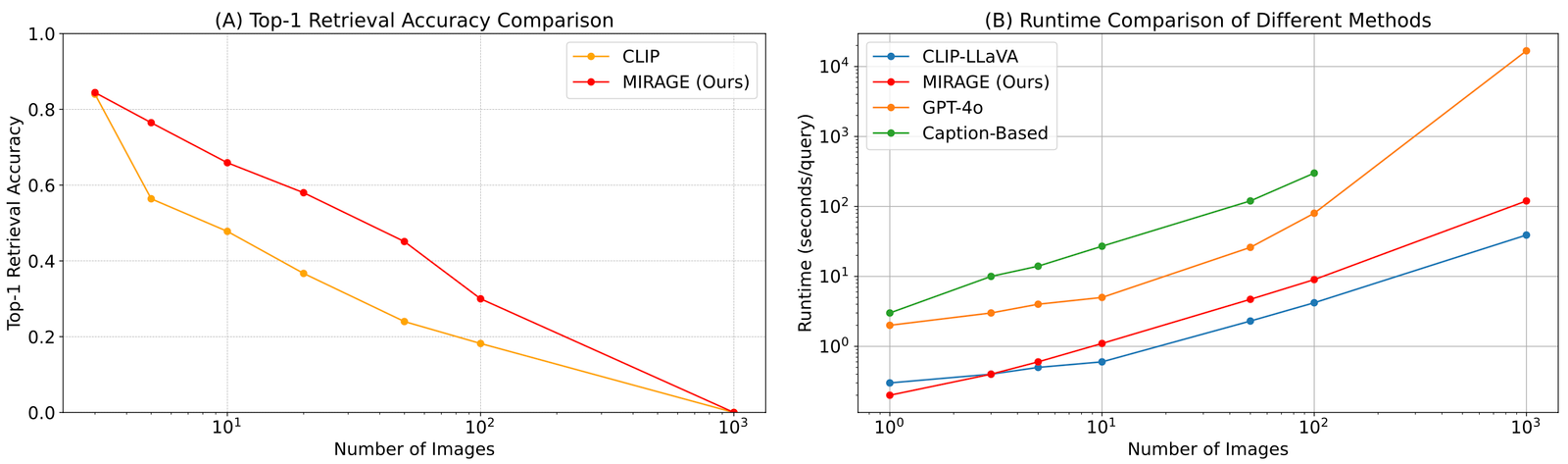
Enfin, nous comparons le Retriever co-entraîné de Mirage avec AGRAFE. Notre Retriever fonctionne beaucoup mieux que le clip sans perdre de l’efficacité. Cela montre que même si les modèles de clip peuvent être de bons retrievers pour la récupération d’images ouverts, ils peuvent ne pas fonctionner bien lorsqu’ils traitent des textes de question!
Dans ce travail, nous développons la référence Visual Haystacks (VHS) et identifions trois lacunes répandues dans les grands modèles multimodaux (LMM) existants:
-
Lutte avec les distracteurs visuels: Dans les tâches d’une seule aiguille, le LMMS présente une forte baisse des performances à mesure que le nombre d’images augmente, indiquant un défi important dans le filtrage des informations visuelles non pertinentes.
-
Raisonnement de difficulté sur plusieurs images: Dans les paramètres multi-aiguilles, des approches simplistes telles que le sous-titrage suivie de la QA basée sur le langage surpassent tous les LMM existants, mettant en évidence la capacité inadéquate de LMMS à traiter les informations sur plusieurs images.
-
Phénomènes dans le domaine visuel: Les modèles propriétaires et open source affichent une sensibilité à la position des informations d’aiguille dans les séquences d’image, présentant un phénomène «perte dans le milieu» dans le domaine visuel.
En réponse, nous proposons Mirage, un framework générateur (Rag) pionnier du Retriever Visual Retriever. Mirage relève ces défis avec un compresseur de jeton visuel innovant, un retriever formé et des données de réglage d’instructions multi-images augmentées.
Après avoir exploré ce billet de blog, nous encourageons tous les futurs projets LMM à comparer leurs modèles en utilisant le cadre de backs de foin visuel pour identifier et rectifier des carences potentielles avant le déploiement. Nous exhortons également la communauté à explorer la réponse à des questions multi-images comme un moyen de faire avancer les frontières de la véritable intelligence générale artificielle (AGI).
Enfin et surtout, veuillez consulter notre page du projetet papier arxivet cliquez sur le bouton étoile de notre GitHub Repo!
@article{wu2024visual,
title={Visual Haystacks: Answering Harder Questions About Sets of Images},
author={Wu, Tsung-Han and Biamby, Giscard and and Quenum, Jerome and Gupta, Ritwik and Gonzalez, Joseph E and Darrell, Trevor and Chan, David M},
journal={arXiv preprint arXiv:2407.13766},
year={2024}
}
Source link



