
Volga – calcul à la demande dans AI / ml en temps réel – Aperçu et architecture
- Intelligence Artificielle
 Noesis News
Noesis News- 0
- 29 minutes de lecture
Auteur (s): Andrey Novitskiy
Publié à l’origine sur Vers l’IA.
Tl; dr Volga est un moteur de traitement des données / calcul des fonctionnalités en temps réel adapté à une AI moderne /Ml. Il est conçu pour prendre en charge divers types de fonctionnalités, y compris le streaming (en ligne), le lot (hors ligne) et les fonctionnalités à la demande, via une architecture hybride Push + Pull: une personnalité Moteur de streaming (pour en ligne + hors ligne) et une couche de calcul à la demande (pour la demande). Dans cet article, nous plongerons profondément dans la couche de calcul à la demande, les fonctionnalités à la demande, les cas d’utilisation et l’architecture.
Contenu:
- Ce que c’est et ce que c’est pour
- Exemples
- Architecture
- Aperçu de l’API
- Une partie manquante de l’écosystème des rayons
- Comment le streaming et la demande fonctionnent ensemble
- Étapes suivantes
Ce que c’est et ce que c’est pour
La plupart des systèmes en temps réel fonctionnent sur des flux d’événements (par exemple, clics / achats d’utilisateurs, demandes de conduite, transactions par carte de crédit, etc.) et représentent un Système entièrement motivé: Toutes les transformations de données / logique personnalisée peuvent être en quelque sorte liées à un événement qui l’a déclenché, et c’est vrai pour toute partie du système. Ces types de systèmes peuvent être gérés par un moteur de traitement de flux seul.
Ml Les charges de travail sont un peu différentes: elles appartiennent à une classe de Systèmes basés sur les demandes (Dans notre cas, nous parlons des demandes d’inférence du modèle). Cette classe de systèmes comprend la plupart des applications Web modernes, dont l’architecture est basée sur le modèle de demande-réponse et construite en utilisant la notion de serveur (ou un service Web).
De manière générale, le modèle de demande-réponse peut également être transformé en un système purement motivé par des événements où chaque demande est un événement distinct (il s’agit d’une bonne direction de conception à explorer). Cependant, dans la pratique, les systèmes basés sur les demandes sont généralement apatrides et ont des exigences différentes pour l’évolutivité, la latence, le débit, la disponibilité des données et la tolérance aux défauts, ce qui donne des exigences de pile d’infrastructure différentes par rapport à ce qu’un moteur de streaming offre.
En conséquence, dans le contexte du traitement des données en temps réel et de la génération de fonctionnalités, la plupart des systèmes basés sur la ML nécessitent une couche qui serait en mesure de traiter les demandes entrantes avec une latence minimisée, d’effectuer une logique de calcul arbitraire et de servir les résultats dès que possible afin qu’il puisse être utilisé dans d’autres parties du système (par exemple, le service du modèle) ou directement par l’utilisateur – c’est ce que nous appelons le Système du système (par exemple, le modèle de modèle) ou directement par l’utilisateur – c’est ce que nous appelons les parties Couche de calcul à la demande.
Exemples
Certains exemples de systèmes ML en temps réel qui nécessitent des calculs à temps de demande à la demande et ne peuvent pas compter uniquement sur un moteur de streaming seul peut inclure:
- Un système de personnalisation de recherche qui repose sur les coordonnées GPS d’un utilisateur: les données sont disponibles uniquement au moment de la demande et doivent être gérées immédiatement pour les résultats pertinents.
- UN système de recommandationoù les réponses reposent sur un calcul coûteux (par exemple, l’intégration du produit DOT, GPU– Opérations basées sur, etc.) et / ou la communication avec les services tiers (par exemple, interroger un autre modèle) – Le gérer dans un moteur de streaming créerait un goulot d’étranglement et nécessiterait une conception très prudente.
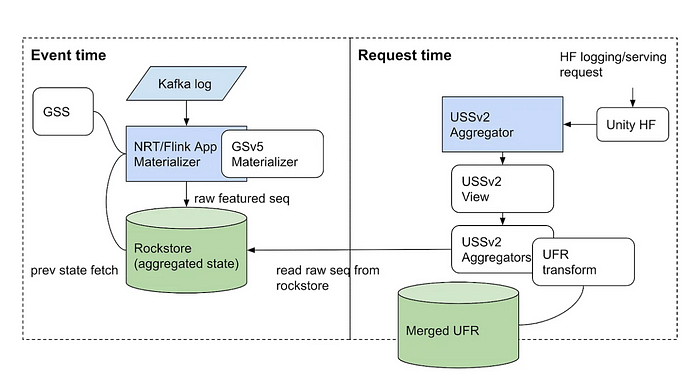
C’est la partie que de nombreux moteurs de streaming «prêts pour l’AI / ML» manquent: le traitement du temps d’événement n’est pas suffisant pour couvrir tous les besoins en temps réel / ml en temps réel. Pour cette raison, Volga sépare son architecture dans le Faire pousseroù le moteur de streaming est le roi et présente également le Tirer partigéré par la couche de calcul à la demande, où le calcul de la demande est effectué.
La plupart des plates-formes de fonctionnalités / données ML modernes adoptent une architecture similaire (Caractéristiques à la demande dans tecton, Caractéristiques des extracteurs en fenouil, Resolvers à la craie).
Un autre bon exemple est Le pipeline de fonctionnalités du système de recommandation de Homefeed de Homerestqui a également une séparation entre le calcul du temps d’événement, géré par un moteur de streaming (Flink), et le calcul de la demande, géré par un service personnalisé.
Architecture
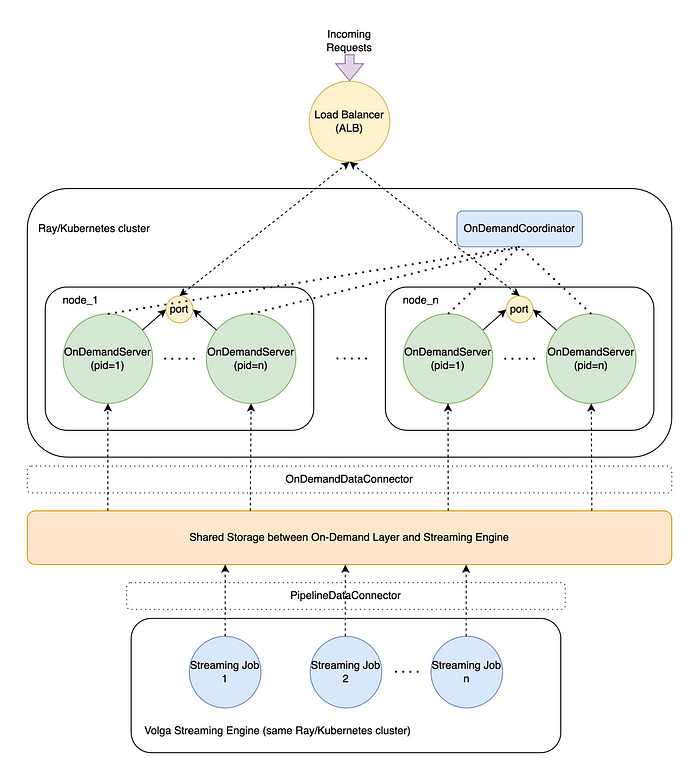
En résumé, dans Volga, la couche de calcul à la demande est un pool de travailleurs utilisés pour exécuter une logique arbitraire définie par l’utilisateur (ce que nous appelons un fonctionnalité à la demande) À l’heure de la demande / inférence et de le remettre à l’utilisateur. Il est conçu pour être interopérable avec le moteur de streaming de Volga, de sorte que l’ensemble du système peut exécuter des Dags de calcul arbitraires qui incluent l’exécution à la fois aux heures d’événement et de demande. Jetons un coup d’œil aux parties de travail du système et au cycle de vie de la demande.
C’est le premier composant qui entre en jeu. Le OnDemandCoordinator est un acteur responsable de l’orchestration et du suivi OnDemandServers—Acteurs de travailleurs (plus ci-dessous). Le OnDemandCoordinator gère l’isolement logique des travailleurs (configurer qui dispose de chaque travailleur responsable), la mise à l’échelle de haut en bas, les contrôles de santé et les redémarrages si nécessaire.
Le composant extérieur qui gère les demandes entrantes et les distribue entre les nœuds de cluster. Il s’agit généralement d’une ressource basée sur le cloud (pour nos repères, nous avons utilisé AWS Application Load Balancer), mais en pratique, il peut s’agir de toute autre configuration (par exemple, nginx / métallb). Notez que l’équilibreur de charge ne fait pas partie de Volga et représente un modèle de déploiement le plus probable.
Un travailleur Python qui effectue une logique décrite dans les fonctionnalités à la demande. Le processus de travailleur exécute une instance d’un Serveur de starlette Pour gérer les demandes entrantes, chacune écoutant un port fixe sur un nœud hôte. De cette façon, le Round-Robins du système d’exploitation (Linux uniquement) toutes les demandes aux travailleurs de ce nœud, en gardant la charge équilibrée.
Chaque travailleur est initié avec une liste de définitions de fonctionnalités qu’elle est censée gérer (l’initiation est gérée par le OnDemandCoordinator). Lorsqu’une demande arrive, le OnDemandServer Parses qui ciblent les fonctionnalités qu’il est censé exécuter et compile un Dag de toutes les fonctionnalités dépendantes. N’oubliez pas que Volga prend en charge deux types de fonctionnalités: on_demand (géré par la couche à la demande) et pipeline (géré par le moteur de streaming).
Étant donné que l’aspect le plus puissant de Volga est qu’il prend en charge à la fois l’événement et les demandes de calcul du temps, on_demand Les fonctionnalités peuvent dépendre des deux autres on_demand fonctionnalités ainsi que pipeline caractéristiques. Ce fait crée un flux d’exécution spécial: les fonctionnalités DAG sont triées topologiquement et exécutées dans l’ordre; on_demand Les fonctionnalités sont exécutées à l’aide des résultats de leurs personnes à charge comme entrées. Dans l’environnement à la demande, pipeline Les fonctionnalités sont traitées simplement comme des lectures au stockage: le flux de bout en bout de Volga est que l’exécution réelle de pipeline Les fonctionnalités sont gérées par le moteur de streaming, qui écrit les résultats de l’exécution du pipeline pour partager le stockage de manière asynchrone. Le travailleur à la demande lit simplement les résultats de la fonctionnalité du pipeline correspondant (la façon dont il le lit est également configurable dans OnDemandDataConnectorplus à ce sujet ci-dessous) et l’utilise comme entrée pour la logique à la demande.
Le stockage est une abstraction partagée entre les pièces de poussée et de traction: streaming emplois Les résultats des pipelines matérialisés dans le stockage, les travailleurs à la demande effectuent des calculs asynchrones sur la base de données matérialisées et servent des résultats. Notez que dans l’environnement à la demande, le stockage est en lecture seule (on_demand Les fonctionnalités n’ont rien besoin de stocker quoi que ce soit).
Le stockage est une interface configurable, qui peut utiliser un backend arbitraire (via la mise en œuvre PipelineDataConnector et OnDemandDataConnector). Notez que puisque nous pouvons exécuter Volga dans les modes en ligne et hors ligne, chaque mode a des exigences de stockage différentes, par exemple en ligne nécessite de minimiser la latence de lecture / écriture (redis / scylla), hors ligne est pour la boutique optimisée par capacité (HDF, lacs): c’est quelque chose à considérer par l’utilisateur.
Aperçu de l’API
Les fonctionnalités à la demande sont créées en utilisant le on_demand décorateur et peut dépendre des caractéristiques du pipeline ou d’autres on_demand caractéristiques.
from volga.api.source import source
from volga.api.on_demand import on_demand# mock simple pipeline feature via streaming source
@source(TestEntity)
def test_feature() -> Connector:
return MockOnlineConnector.with_periodic_items(
items=(...)
period_s=1
)
# on-demand features
@on_demand(dependencies=(('test_feature', 'latest'))
def simple_feature(
dep: TestEntity,
multiplier: float = 1.0
) -> TestEntity:
"""Simple on-demand feature that multiplies the value"""
return TestEntity(
id=dep.id,
value=dep.value * multiplier,
timestamp=datetime.now()
)
Le dependencies Le paramètre décrit les caractéristiques dépendantes; L’ordre doit correspondre aux arguments correspondants dans la fonction. Notez que la dépendance est un 2-Tuple: la première valeur est le nom de la fonction dépendante, et le second est le query_name défini dans OnDemandDataConnector (MockDataConnector dans notre cas): il définit comment nous récupérons les valeurs pour test_feature - Dans ce cas, nous allons simplement récupérer les derniers (en savoir plus sur les requêtes de connecteur de données ci-dessous).
Démarrez les travailleurs et enregistrez les fonctionnalités pour servir:
# start coordinator first
coordinator = create_on_demand_coordinator(OnDemandConfig(
num_servers_per_node=2,
server_port=DEFAULT_ON_DEMAND_SERVER_PORT,
data_connector=OnDemandDataConnectorConfig(
connector_class=MockOnDemandDataConnector,
connector_args={}
)
))
ray.get(coordinator.start.remote())# register 'simple_feature'
ray.get(coordinator.register_features.remote(
FeatureRepository.get_features_with_deps(('simple_feature'))
))
Composez une demande en utilisant les clés requises et les fonctionnalités de requête en temps réel:
request = OnDemandRequest(
target_features=('simple_feature'),
feature_keys={
'simple_feature': (
{'id': 'test-id'},
{'id': 'test-id-1'},
{'id': 'test-id-2'}
)
},
udf_args={
'simple_feature': {'multiplier': 2.0}
}
)client = OnDemandClient(DEFAULT_ON_DEMAND_CLIENT_URL)
response = self.loop.run_until_complete(client.request(request))
pprint(response.results)
...
OnDemandResponse(results={'simple_feature': (
({'id': 'test-id', 'value': 4.0, 'timestamp': '2025-04-06T16:30:24.324526'}),
({'id': 'test-id-1', 'value': 6.0, 'timestamp': '2025-04-06T16:30:24.324536'}),
({'id': 'test-id-2', 'value': 8.0, 'timestamp': '2025-04-06T16:30:24.324541'})
)}, server_id=11)
Une partie manquante de l’écosystème des rayons
Un lecteur attentif peut noter que l’architecture à la demande ressemble quelque peu à celle de Rayon de rayon (Infrastructure de service modèle utilisé par Ray). En effet, les deux systèmes sont basés sur des demandes et sont complémentaires les uns des autres, car les deux systèmes représentent des parties vitales du flux d’inférence du modèle de bout en bout: obtenir des fonctionnalités d’abord, puis les utiliser pour une inférence réelle.
Alors que Ray fournit la pièce de service du modèle, la portion / calcul des fonctionnalités est manquante, obligeant les utilisateurs à s’appuyer sur des couches de service de données personnalisées, ce qui augmente considérablement la complexité et les coûts opérationnels de l’exécution de la ML en temps réel.
La couche à la demande est conçue pour combler ce spot et, ainsi que la portion modèle, pour devenir la frontière initiale orientée utilisateur pour les systèmes modernes basés sur ML. Cela aidera à évoluer vers une conception de système plus homogène, en supprimant les dépendances extérieures et, avec le moteur de streaming de Volga, unificant le traitement des données en temps réel au-dessus de Ray.
Comment le streaming et la demande fonctionnent ensemble
Cette section traite du stockage partagé entre le moteur de streaming (push) et les pièces à la demande (pull) et comment la couche à la demande interface avec elle. Tout le on_demand les caractéristiques dépendent directement ou indirectement de pipeline Les résultats des fonctionnalités, qui existent dans le stockage partagé (cela inclut simplement le service pipeline caractéristiques). Pour simplifier l’API de définition des fonctionnalités et masquer le contrôle de la couche de données de l’utilisateur, la décision a été prise pour abstraction de toutes les données de données liées au stockage de la logique de fonctionnalité réelle dans une classe distincte qui peut être réutilisée sur différentes fonctionnalités: OnDemandDataConnector (Voir le diagramme d’architecture ci-dessus).
Depuis pipeline Les emplois peuvent produire des résultats sémantiquement différents, la façon dont nous récupérons les données pour on_demand Les fonctionnalités doivent également être configurables pour refléter cette sémantique, par exemple, certaines fonctionnalités ont besoin des valeurs les plus récentes, certaines ont besoin de fenêtres des données jusqu’à une certaine période, certaines doivent effectuer des requêtes plus complexes comme la recherche la plus proche de l’Eightbor (RAGS). Jetons un coup d’œil à InMemoryActorOnDemandDataConnector utilisé dans l’environnement de développement local (représente une interface avec InMemoryCacheActor):
class InMemoryActorOnDemandDataConnector(OnDemandDataConnector):def __init__(self):
self.cache_actor = None
async def init(self):
self.cache_actor = get_or_create_in_memory_cache_actor()
def query_dict(self) -> Dict(str, Callable):
return {
'latest': self.fetch_latest,
'range': self.fetch_range,
}
async def fetch_latest(
self,
feature_name: str,
keys: List(Dict(str, Any))
) -> List(List(Any)):
return await self.cache_actor.get_latest.remote(feature_name, keys)
async def fetch_range(
self,
feature_name: str,
keys: List(Dict(str, Any)),
start: Optional(Decimal),
end: Optional(Decimal)
) -> List(List(Any)):
return await self.cache_actor.get_range.remote(
feature_name, keys, start, end
)
async def close(self):
pass
La méthode de base que l’utilisateur doit définir est query_dict: Il mappe une fonction de récupération arbitraire à un nom simple que nous passons au on_demand décorateur lors de la création de fonctionnalités (rappelez-vous latest param dans le sample_feature Exemple ci-dessus). Les arguments transmis à ces fonctions sont analysés à partir de l’objet de demande en utilisant les mêmes noms ARG que les clés.
Cette séparation de la récupération des données de la logique des fonctionnalités permet un code beaucoup plus propre et réutilisable, ainsi qu’un accès sûr, contrôlé et optimisé à la couche de données – le code défini par l’utilisateur ne pourra pas marteler le stockage ou faire quoi que ce soit indécent.
Étapes suivantes
- Les fonctionnalités à la demande ne fonctionnent actuellement qu’en mode en ligne; Volga ne prend pas en charge le calcul des fonctionnalités à la demande sur les données historiques. Il s’agit d’un problème d’ingénierie intéressant qui nécessite de transformer les systèmes basés sur la demande de demande en un flux d’événements (adapté au mode hors ligne) et de construire un pipeline de streaming pour s’exécuter entièrement sur le moteur de streaming.
- Comme vous l’avez peut-être remarqué, les fonctionnalités à la demande obtiennent des paramètres généraux et des paramètres de connecteur de données à partir de la demande de l’utilisateur. Et si nous voulons obtenir ceux de la fonction dépendante? Cela nécessitera de créer un
arg_mappingpour mapper les arguments aux fonctions et mettre à jour la logique de commande de l’exécuteur exécuteur. - Certaines fonctionnalités à la demande peuvent nécessiter un état local (par exemple, l’initialisation d’un client pour un service tiers).
- La tolérance aux pannes avec les contrôles de santé et les redémarrages doit être mise en œuvre.
- L’exécution actuelle est sur une boucle Asyncio; Un pool de fils et un pool de processus / acteurs sont nécessaires.
Si vous êtes intéressé à les aider et à devenir un contributeur, consultez le Feuille de route Et n’hésitez pas à tendre la main!
Dans le prochain article, nous exécuterons des repères de test de charge et montrerons comment la couche de calcul à la demande fonctionne sous une charge de demande élevée.
Merci d’avoir lu! Veuillez jouer le projet sur Githubrejoignez la communauté sur Moupartagez le blog et laissez vos commentaires.
Publié via Vers l’IA
Source link



