
Trouver des flux d’agent d’agence «Silver Bulte» avec SYFTR
- Intelligence Artificielle
 Noesis News
Noesis News- 0
- 28 minutes de lecture
TL; Dr
Le moyen le plus rapide de bloquer un projet d’IA agentique est de réutiliser un flux de travail qui ne s’adapte plus. En utilisant syftrnous avons identifié les flux de «solutionnaires d’argent» pour les priorités à faible latence et à haute précision qui fonctionnent systématiquement bien dans plusieurs ensembles de données. Ces flux surpassent l’ensemencement aléatoire et transfèrent l’apprentissage au début de l’optimisation. Ils récupèrent environ 75% des performances d’un SYFTR complet à une fraction du coût, ce qui en fait un point de départ rapide mais laisse toujours de la place pour s’améliorer.
Si vous avez déjà essayé de réutiliser un flux de travail agentique d’un projet dans un autre, vous savez à quelle fréquence il tombe à plat. La longueur du contexte du modèle peut ne pas être suffisante. Le nouveau cas d’utilisation peut nécessiter un raisonnement plus profond. Ou les exigences de latence peuvent avoir changé.
Même lorsque l’ancienne configuration fonctionne, elle peut être trop construite – et trop chère – pour le nouveau problème. Dans ces cas, une configuration plus simple et plus rapide peut être tout ce dont vous avez besoin.
Nous avons entrepris de répondre à une question simple: Y a-t-il des flux agentiques qui fonctionnent bien dans de nombreux cas d’utilisation, vous pouvez donc en choisir un en fonction de vos priorités et aller de l’avant?
Nos recherches suggèrent que la réponse est oui, et nous les appelons des «balles d’argent».
Nous avons identifié des balles d’argent pour les objectifs de faible latence et de haute précision. Dans l’optimisation précoce, ils battent constamment l’apprentissage du transfert et l’ensemencement aléatoire, tout en évitant le coût total d’un SYFTR complet.
Dans les sections qui suivent, nous expliquons comment nous les avons trouvées et comment elles s’accumulent contre d’autres stratégies d’ensemencement.
Une amorce rapide sur Pareto-frontiers
Vous n’avez pas besoin d’un diplôme en mathématiques pour suivre, mais la compréhension du Pareto-Frantier facilitera le reste de ce post.
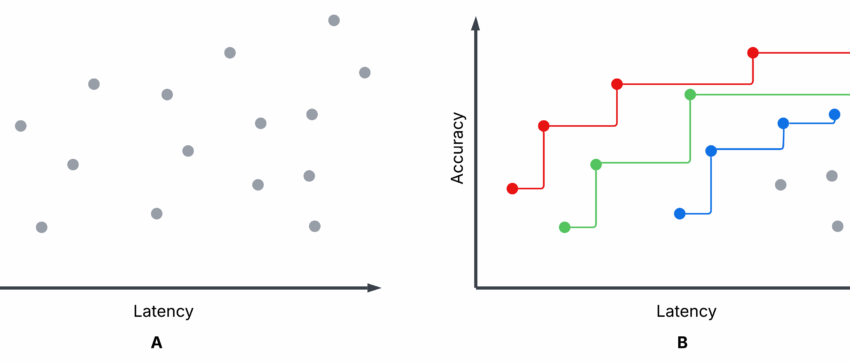
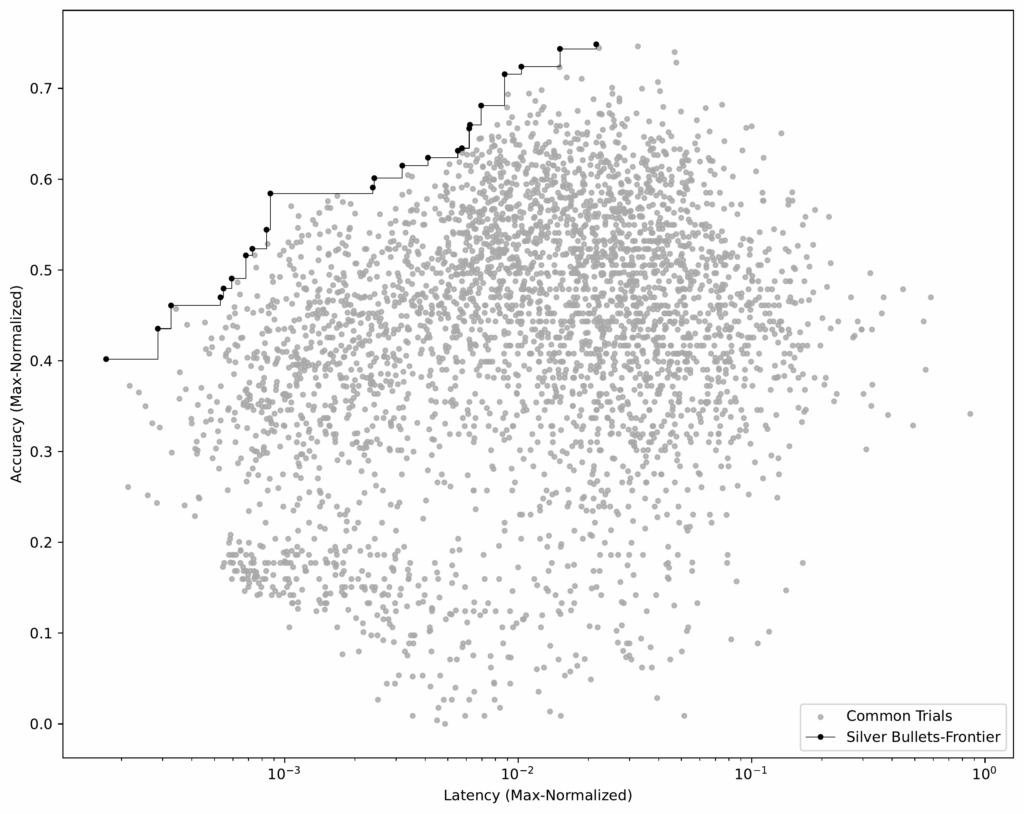
La figure 1 est un tracé de dispersion illustratif – pas de nos expériences – montrant terminé syftr essais d’optimisation. La sous-intrigue A et la sous-parcelle B sont identiques, mais B met en évidence les trois premiers Pareto-Frontiers: P1 (rouge), P2 (vert) et P3 (bleu).
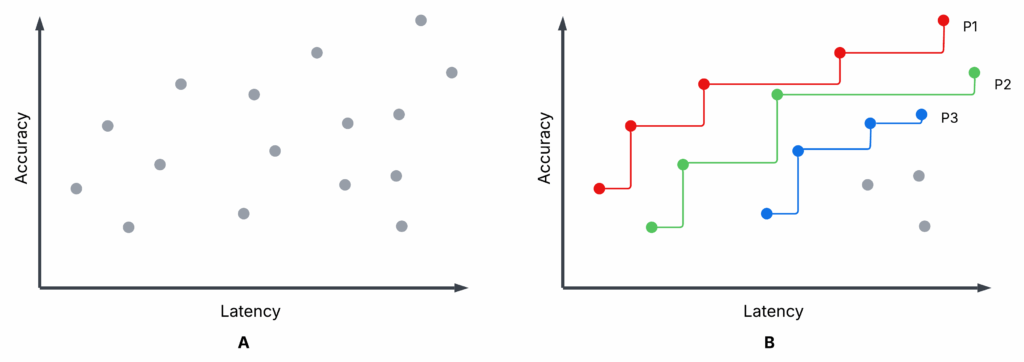
- Chaque essai: Une configuration de flux spécifique est évaluée sur la précision et la latence moyenne (une précision plus élevée, une latence plus faible sont meilleures).
- Pareto-frontier (P1): Aucun autre flux n’a à la fois une précision plus élevée et une latence plus faible. Ce sont non dominé.
- Flux non parito: Au moins un flux de Pareto les bat sur les deux mesures. Ce sont dominé.
- P2, P3: Si vous supprimez P1, P2 devient la meilleure frontière suivante, alors P3, et ainsi de suite.
Vous pouvez choisir entre les flux de Pareto en fonction de vos priorités (par exemple, favorisant une faible latence par rapport à une précision maximale), mais il n’y a aucune raison de choisir un flux dominé – il y a toujours une meilleure option à la frontière.
Optimisation des flux d’IA agentiques avec SYFTR
Tout au long de nos expériences, nous avons utilisé syftr pour optimiser les flux d’agence pour la précision et la latence.
Cette approche vous permet de:
- Sélectionnez des ensembles de données contenant des paires de questions-réponses (QA)
- Définir un espace de recherche pour les paramètres d’écoulement
- Définir des objectifs tels que la précision et le coût, ou dans ce cas, la précision et la latence
En bref, SYFTR automatise l’exploration des configurations de flux par rapport aux objectifs choisis.
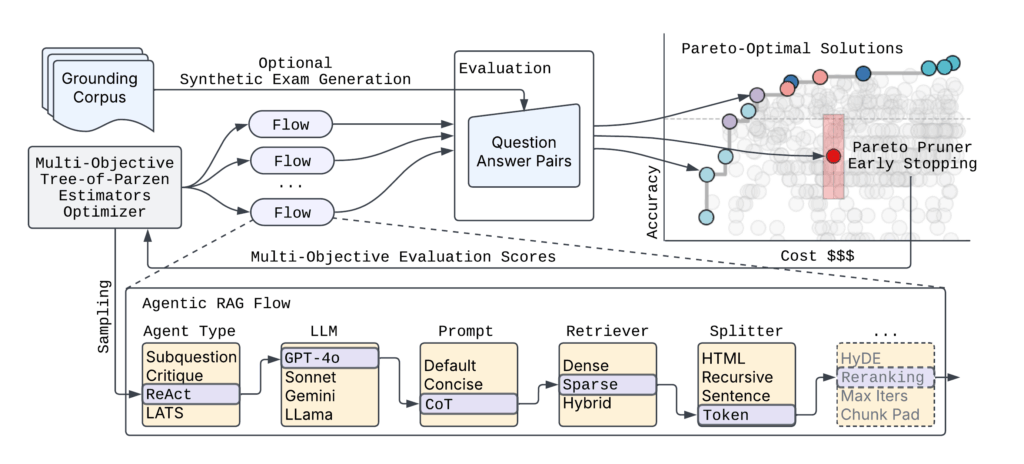
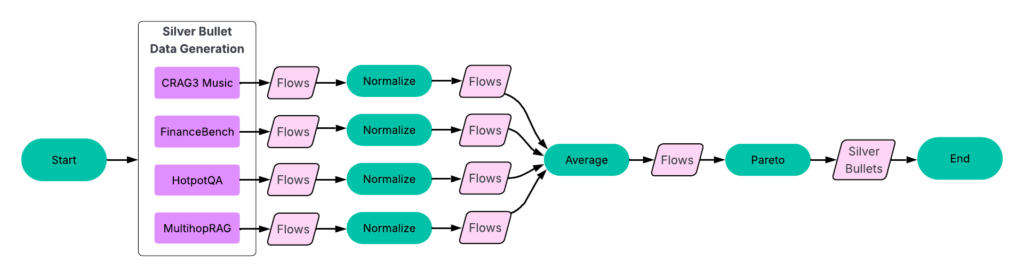
La figure 2 montre l’architecture SYFTR de haut niveau.
Compte tenu du nombre pratiquement sans fin de paramétrisations de flux agentiques possibles, SyFTR repose sur deux techniques clés:
- Optimisation bayésienne multi-objectifs pour naviguer efficacement dans l’espace de recherche.
- Paritoprueur Pour arrêter l’évaluation des flux sous-optimaux probables tôt, gagner du temps et calculer tout en faisant surface les configurations les plus efficaces.
Expériences de Silver Bulte
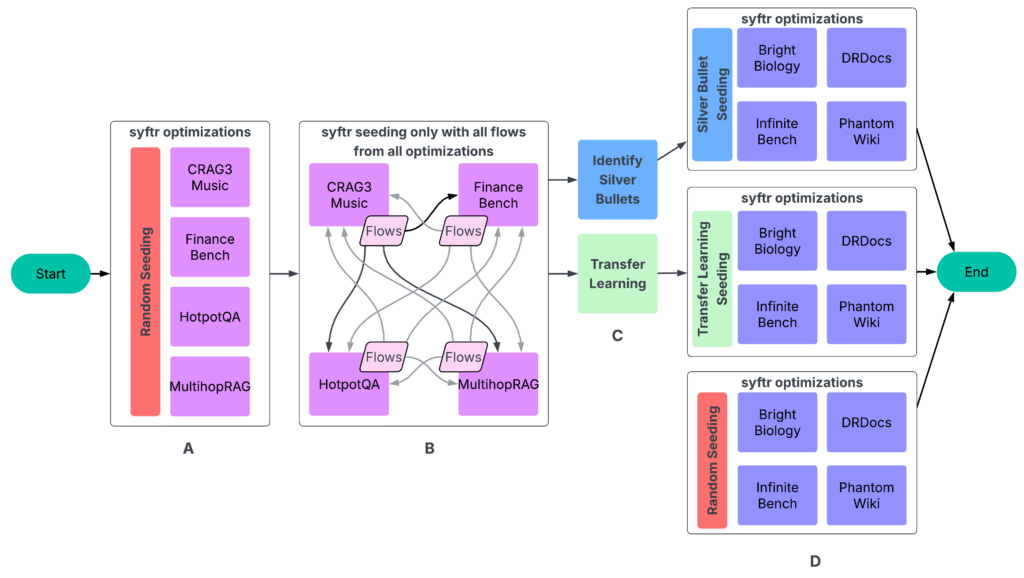
Nos expériences ont suivi un processus en quatre parties (figure 3).
UN: Exécutez SYFTR en utilisant un échantillonnage aléatoire simple pour l’ensemencement.
B: Exécutez tous les flux finis sur toutes les autres expériences. Les données résultantes alimentent ensuite l’étape suivante.
C: Identification des balles d’argent et effectuer un apprentissage du transfert.
D: Exécution de SYFTR sur quatre ensembles de données maintenus trois fois, en utilisant trois stratégies de semis différentes.
Étape 1: Optimiser les flux par ensemble de données
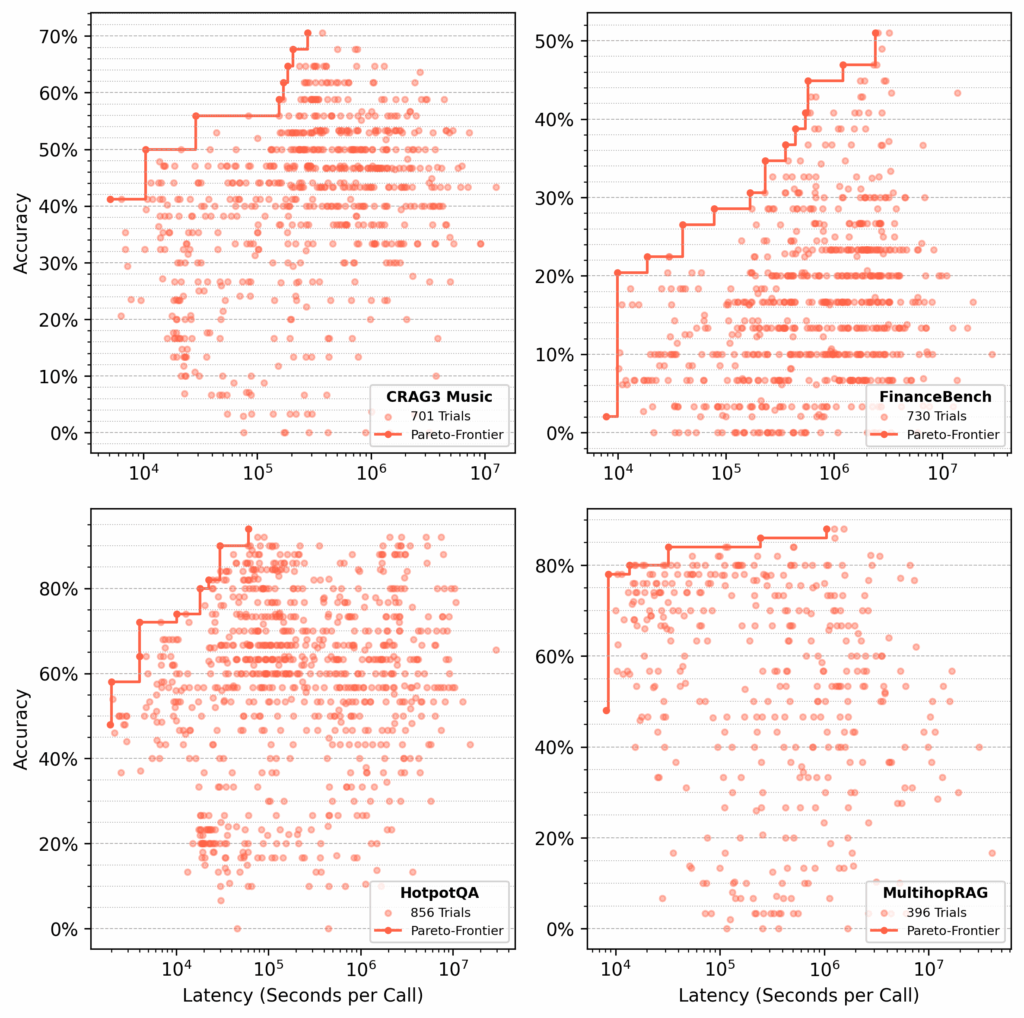
Nous avons mené plusieurs centaines d’essais sur chacun des ensembles de données suivants:
- Crag Task 3 Musique
- Financement
- Hotpotqa
- Multiprag
Pour chaque ensemble de données, syftr recherché des flux paréto-optimaux, l’optimisation de la précision et de la latence (Figure 4).
Étape 3: Identifier les balles d’argent
Une fois que nous avons eu des flux identiques dans tous les ensembles de données d’entraînement, nous pourrions identifier les balles argentées – les flux qui sont paréto-optimaux en moyenne sur tous les ensembles de données.
Processus:
- Normaliser les résultats par ensemble de données. Pour chaque ensemble de données, nous normalisons les scores de précision et de latence par les valeurs les plus élevées de cet ensemble de données.
- Groupes de groupes identiques. Nous regroupons ensuite les flux de correspondance entre les ensembles de données et calculons leur précision et leur latence moyennes.
- Identifier le Pareto-Frantier. À l’aide de cet ensemble de données moyennes (voir figure 6), nous sélectionnons les flux qui construisent le Pareto-Frantier.
Ces 23 flux sont nos balles d’argent – celles qui fonctionnent bien dans tous les ensembles de données de formation.
Étape 4: graines avec apprentissage transfert
Dans notre original papier syftrnous avons exploré l’apprentissage du transfert comme moyen d’optimiser les graines. Ici, nous l’avons comparé directement au semis de balle argenté.
Dans ce contexte, transfert d’apprentissage signifie simplement sélectionner des flux spécifiques hautement performants des études historiques (formation) et les évaluer sur des ensembles de données détenus. Les données que nous utilisons ici sont les mêmes que pour les balles d’argent (figure 3).
Processus:
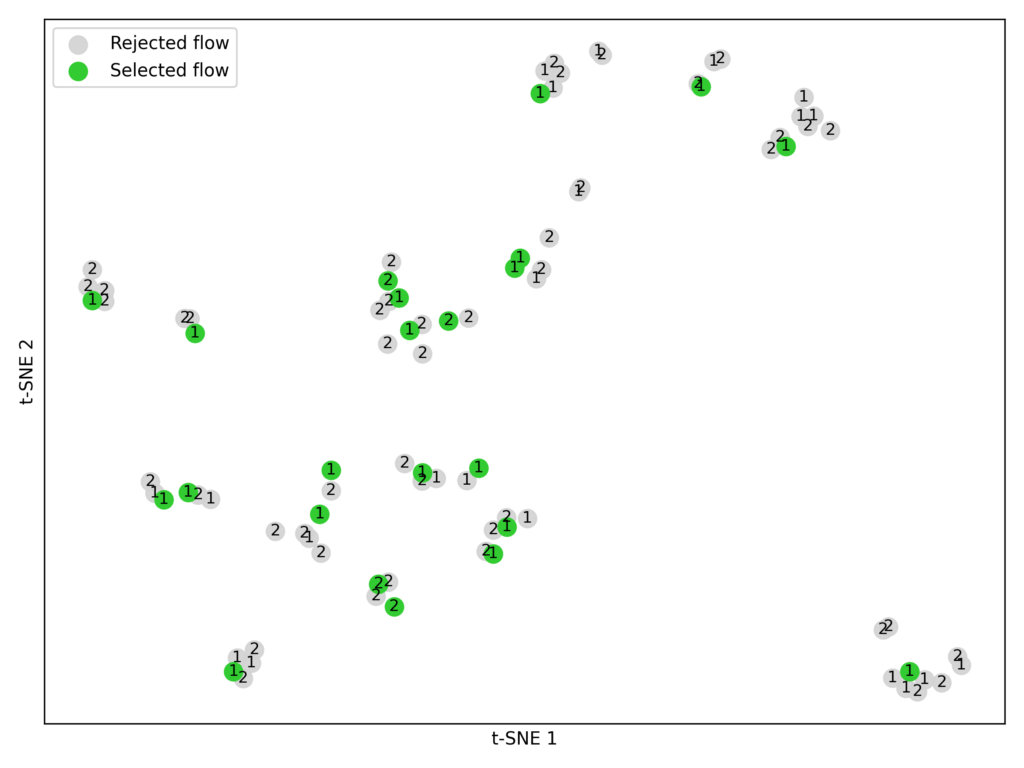
- Sélectionnez les candidats. À partir de chaque ensemble de données d’entraînement, nous avons pris les flux les plus performants des deux premiers-frontiers Pareto (P1 et P2).
- Intégrer et grappe. En utilisant le modèle d’incorporation BAAI / BGE-LARGE-EN-V1.5, nous avons converti les paramètres de chaque flux en vecteurs numériques. Nous avons ensuite appliqué le clustering K-Means (k = 23) aux groupes similaires (figure 7).
- Faire correspondre les contraintes d’expérience. Nous avons limité chaque stratégie d’ensemencement (Silver Bullets, Transfert Learning, Random Sampling) à 23 flux pour une comparaison équitable, car c’est le nombre de formes d’argent que nous avons identifiées.
Note: L’apprentissage du transfert pour l’ensemencement n’est pas encore entièrement optimisé. Nous pourrions utiliser plus de pareto-frontiers, sélectionner plus de flux ou essayer différents modèles d’incorporation.
Étape 5: Tester tout cela
Dans la phase d’évaluation finale (étape D de la figure 3), nous avons effectué environ 1 000 essais d’optimisation sur quatre ensembles de données de test – Bright Biology, Drdocs, InfiniteBench et Phantomwiki – répétant le processus trois fois pour chacune des stratégies de semence suivantes:
- Se dans les saliers argentés
- Transférer l’apprentissage de l’apprentissage
- Échantillonnage aléatoire
Pour chaque procès, le GPT-4O-MINI a été le juge, vérifiant la réponse d’un agent contre la réponse au sol.
Résultats
Nous avons décidé de répondre:
Quelle approche d’ensemencement – échantillonnage aléatoire, apprentissage du transfert ou balles d’argent – offre les meilleures performances pour un nouvel ensemble de données dans le moins d’essais?
Pour chacun des quatre ensembles de données de test (biologie brillante, Drdocs, InfiniteBench et Phantomwiki), nous avons tracé:
- Précision
- Latence
- Coût
- Pareto-Area: une mesure de la proximité des résultats du résultat optimal
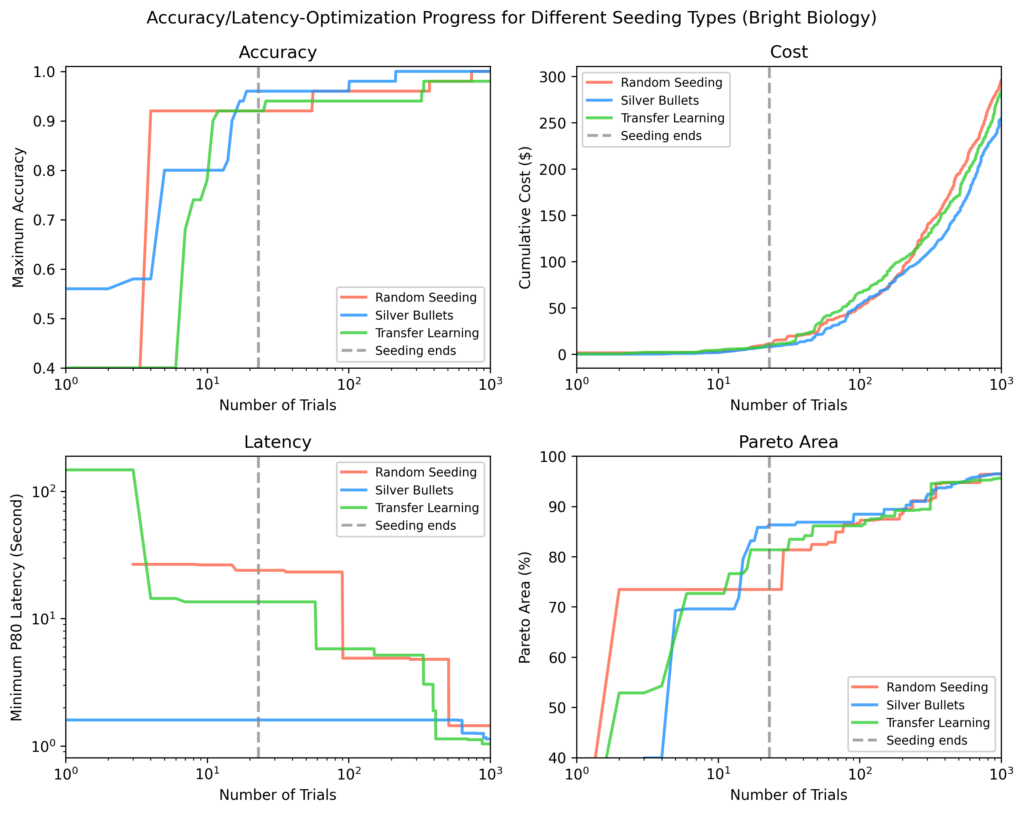
Dans chaque tracé, le ligne pointillée verticale marque le point où tous les essais d’ensemencement ont terminé. Après l’ensemencement, les balles d’argent ont montré en moyenne:
- 9% précision maximale plus élevée
- 84% latence minimale inférieure
- 28% plus grande région paréenne
par rapport aux autres stratégies.
Biologie brillante
Les balles argentées avaient la plus grande précision, la latence la plus faible et la plus grande région pareto après l’ensemencement. Certains essais de semis aléatoires n’ont pas fini. Les paéto-zones pour toutes les méthodes ont augmenté au fil du temps mais se sont rétrécies à mesure que l’optimisation progressait.
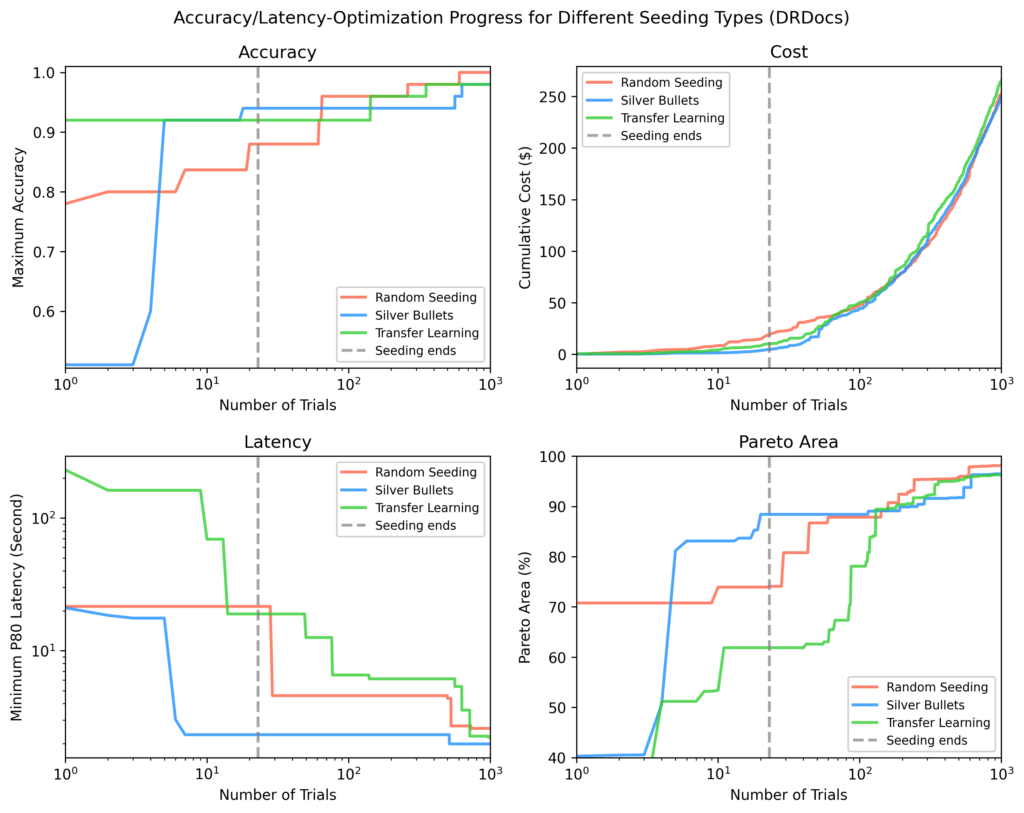
Drdocs
Semblable à la biologie brillante, les balles argentées ont atteint une région de Pareto à 88% après l’ensemencement contre 71% (apprentissage du transfert) et 62% (aléatoire).
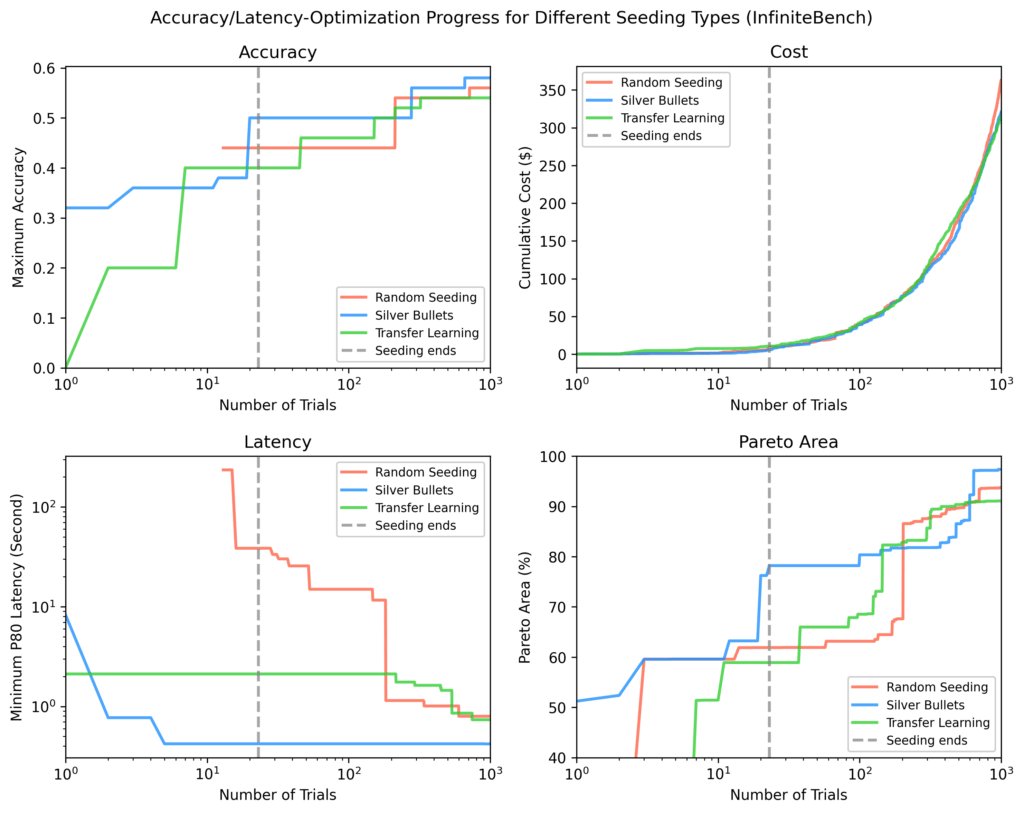
Infini
D’autres méthodes ont besoin de ~ 100 essais supplémentaires pour correspondre à la région de Pareto de Silver Bullet, et ne correspondaient toujours pas aux flux les plus rapides trouvés via des balles d’argent à la fin de ~ 1 000 essais.
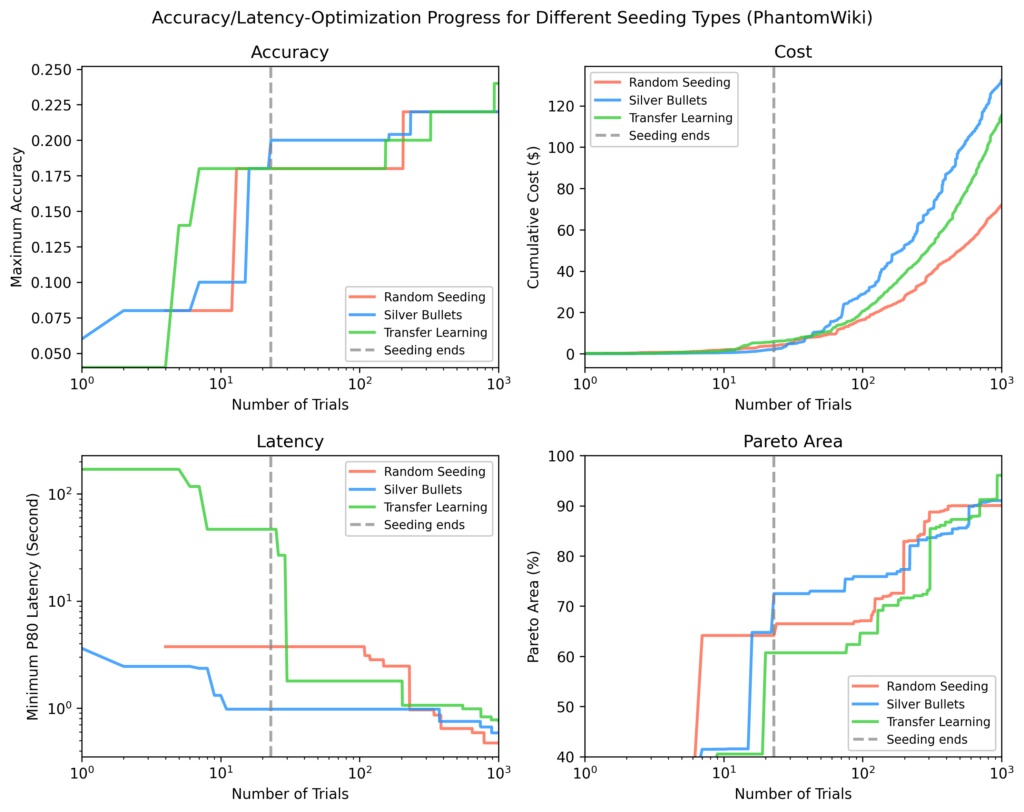
Phantomwiki
Les balles d’argent ont à nouveau fonctionné le mieux après l’ensemencement. Cet ensemble de données a montré la divergence des coûts les plus larges. Après ~ 70 essais, le Silver Bullet Run se concentrait brièvement sur les flux plus chers.
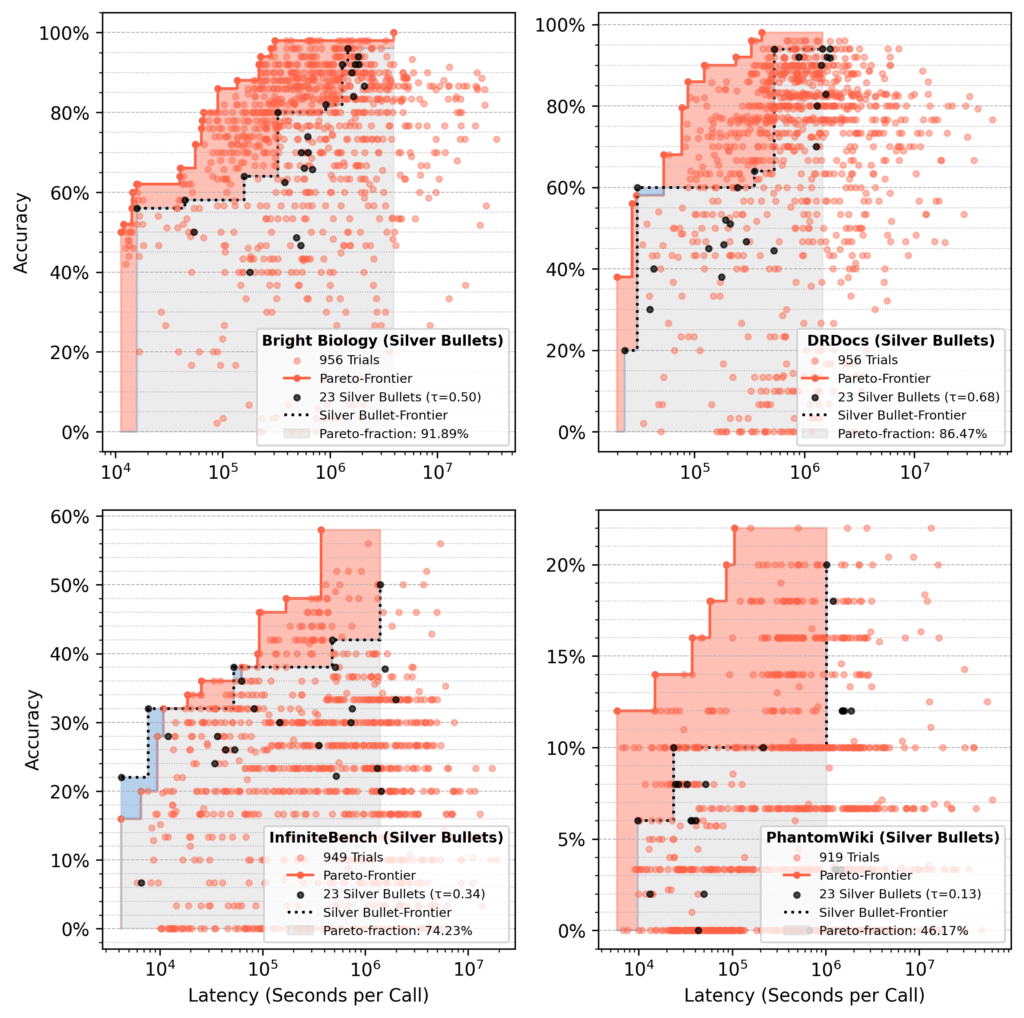
Analyse de la fraction de Pareto
Dans les courses à tête de série avec des balles d’argent, les 23 flux de balles en argent représentaient environ 75% de la paréto finale après 1 000 essais, en moyenne.
- Zone rouge: gains de l’optimisation par rapport aux performances initiales de la solution miracle.
- Zone bleue: les coulées de balles en argent dominant toujours à la fin.
Notre plats à emporter
L’ensemencement avec des balles en argent offre des résultats toujours solides et même surpasse l’apprentissage du transfert, malgré cette méthode qui tire d’un ensemble diversifié de flux historiques de Pareto-Frontier.
Pour nos deux objectifs (précision et latence), les balles d’argent commencent toujours par une précision plus élevée et une latence plus faible que les flux d’autres stratégies.
À long terme, l’échantillonneur TPE réduit l’avantage initial. Dans quelques centaines d’essais, les résultats de toutes les stratégies convergent souvent, ce qui est prévu car chacun devrait éventuellement trouver des flux optimaux.
Alors, les flux agentiques existent-ils qui fonctionnent bien dans de nombreux cas d’utilisation? Oui – à un point:
- En moyenne, un petit ensemble de balles en argent récupère environ 75% de la région de Pareto d’une optimisation complète.
- Les performances varient selon les données, comme la récupération de 92% pour la biologie brillante, contre 46% pour Phantomwiki.
Fin de compte: Les balles en argent sont un moyen peu coûteux et efficace de se rapprocher d’une course SYFTR complète, mais elles ne remplacent pas. Leur impact pourrait croître avec plus de ensembles de données de formation ou des optimisations de formation plus longues.
Paramétrisations de la solution miracle
Nous avons utilisé ce qui suit:
LLMS
- Microsoft / PHI-4-Multimodal-Istruct
- Deepseek-ai / Deepseek-R1-Distill-Llama-70b
- Qwen / qwen2.5
- Qwen / qwen3-32b
- Google / Gemma-3-27b-it
- Nvidia / Llama-3_3-Nemotron-Super-49b
Modèles d’intégration
- Baai / bge-small-en-v1.5
- alorslper / gte-gren
- mixte-pain-ai / mxbai-embed-Large-v1
- Transformateurs de phrases / All-Minilm-L12-V2
- Transformateurs de phrase / paraphrase-multitilingue-MPNET-Base-V2
- Baai / BGE-Base-en-V1.5
- Baai / bge-large-en-v1.5
- Tencentbac / Conan-Embedding-V1
- Linq-a-research / linq-embed-mistral
- Flocon de neige / flocon de neige-arctique-l-v2.0
- Baai / bge-multilingual-gemma2
Types de flux
- vanille
- Agent de chiffon de réact
- Agent de la critique
- Chiffon de sous-question
Voici la liste complète de tous 23 balles en argenttrié de faible précision / latence faible à haute précision / latence élevée: silver_bullets.json.
Essayez-le vous-même
Vous voulez expérimenter ces paramétrisations? Utiliser le running_flows.ipynb Notebook dans notre référentiel SYFTR – Assurez-vous simplement d’avoir accès aux modèles énumérés ci-dessus.
Pour une plongée plus profonde dans l’architecture et les paramètres de Syftr, consultez notre document technique ou explorez le base de code.
Nous présenterons également ce travail au Conférence internationale sur l’apprentissage automatique automatisé (Automl) en septembre 2025 à New York.
Source link



