
Test de contrainte Fastapi Application – Kdnuggets
- Intelligence Artificielle
 Noesis News
Noesis News- 0
- 21 minutes de lecture
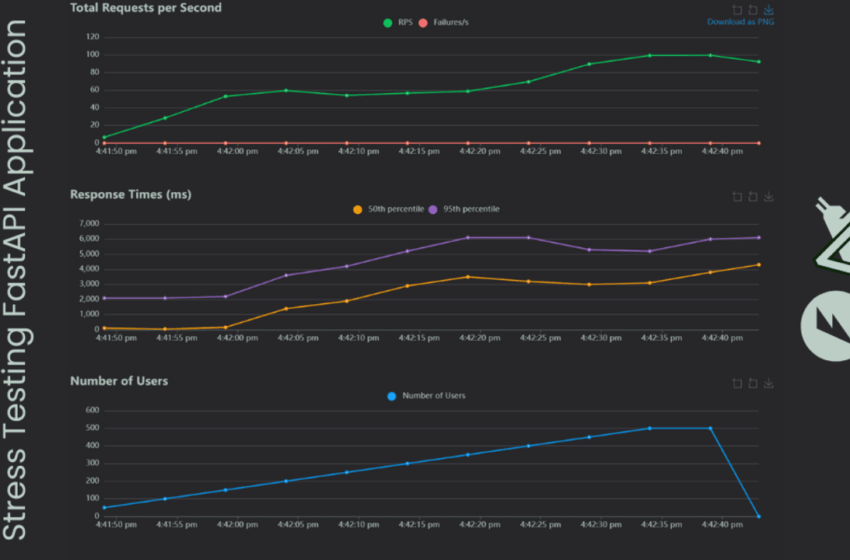
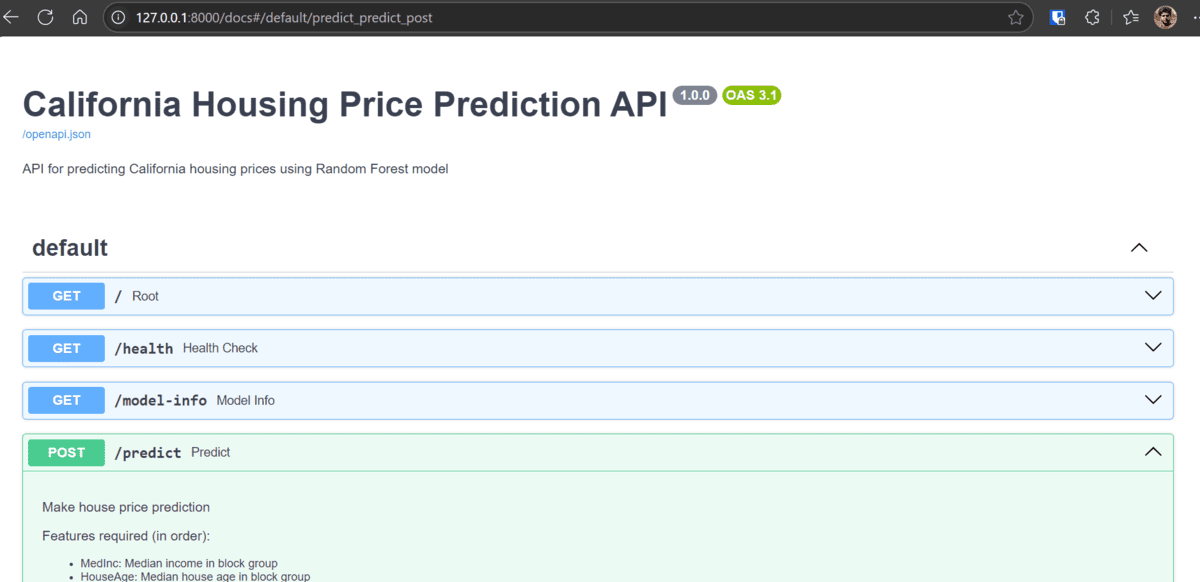
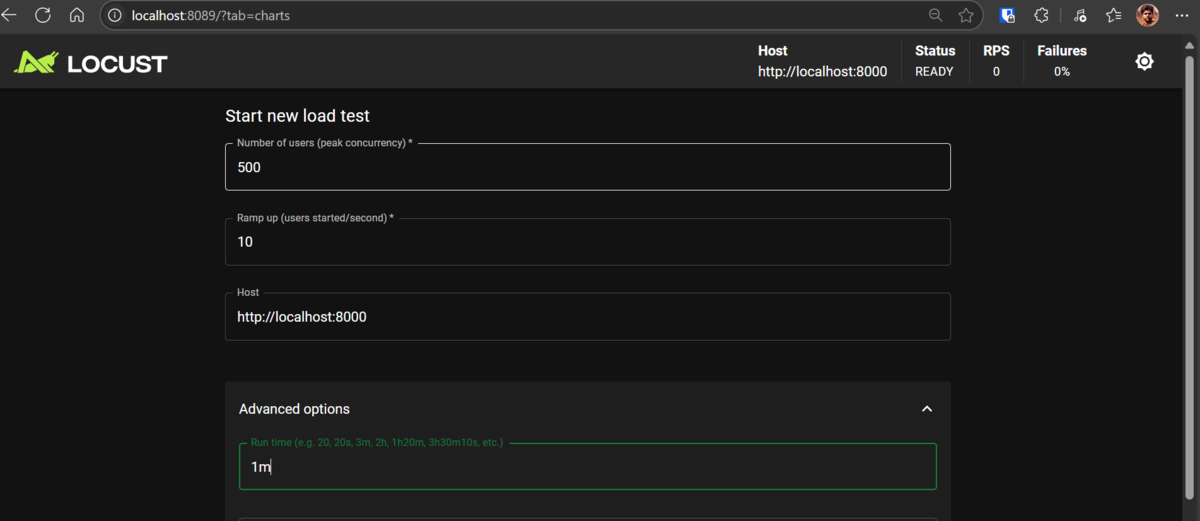
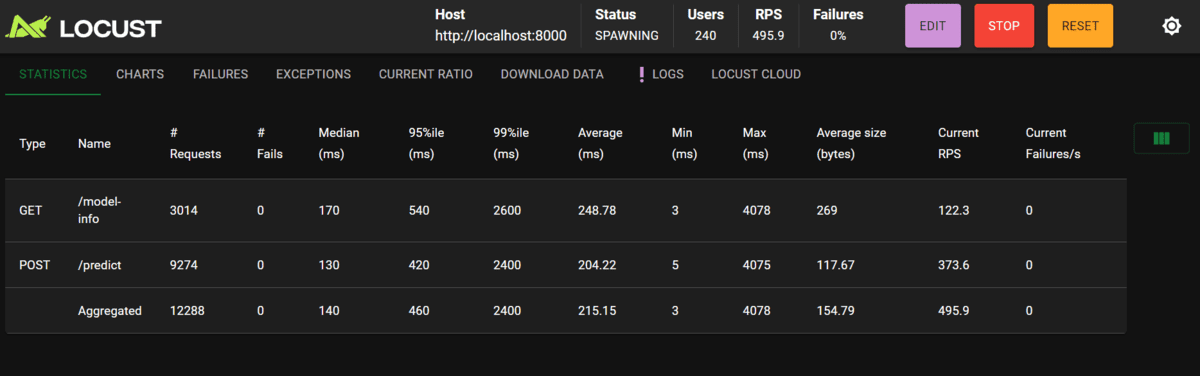
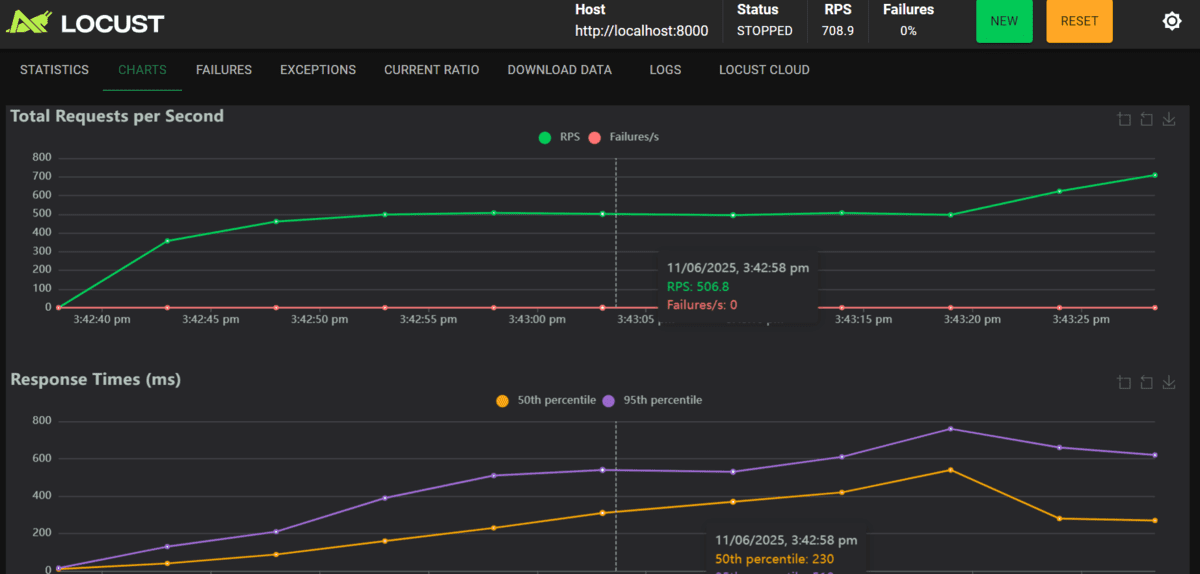
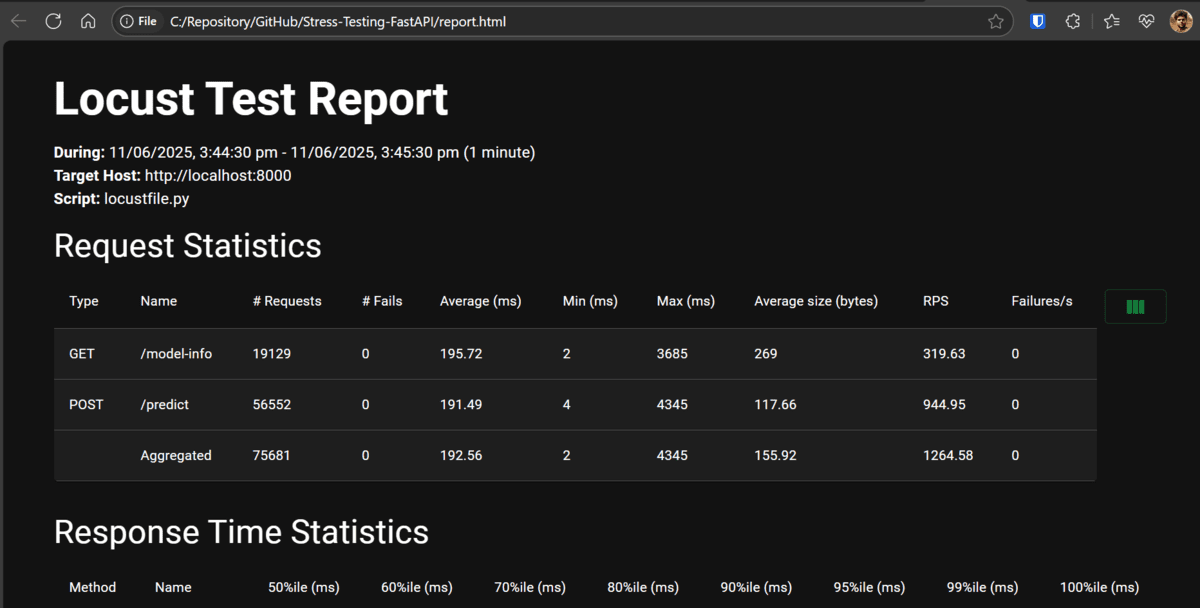
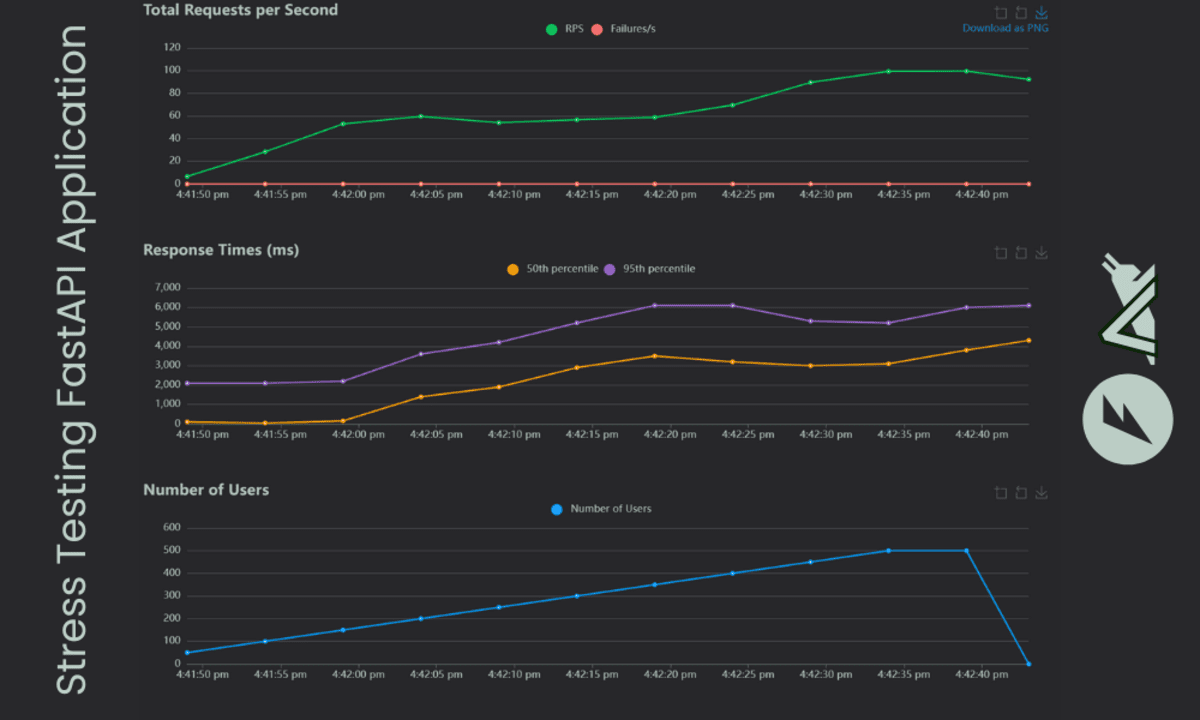
Image par auteur
# Introduction
Les tests de stress sont cruciaux pour comprendre comment votre application se comporte sous une charge intense. Pour les API alimentées par l’apprentissage automatique, il est particulièrement important car l’inférence du modèle peut être à forte intensité de processeur. En simulant un grand nombre d’utilisateurs, nous pouvons identifier les goulots d’étranglement des performances, déterminer la capacité de notre système et assurer la fiabilité.
Dans ce tutoriel, nous utiliserons:
- Fastapi: Un cadre Web moderne et rapide (haute performance) pour la création d’API avec Python.
- Uvicorn: Un serveur ASGI pour exécuter notre application FastAPI.
- Criquet: Un outil de test de charge open source. Vous définissez le comportement de l’utilisateur avec le code Python et essaiffez votre système avec des centaines d’utilisateurs simultanés.
- Scikit-Learn: Pour notre exemple de modèle d’apprentissage automatique.
# 1. Configuration du projet et dépendances
Configurez la structure du projet et installez les dépendances nécessaires.
- Créer
requirements.txtfichier et ajouter les packages Python suivants: - Ouvrez votre terminal, créez un environnement virtuel et activez-le.
- Installez tous les packages Python à l’aide du
requirements.txtdéposer.
fastapi==0.115.12
locust==2.37.10
numpy==2.3.0
pandas==2.3.0
pydantic==2.11.5
scikit-learn==1.7.0
uvicorn==0.34.3
orjson==3.10.18
python -m venv venv
venvScriptsactivate
pip install -r requirements.txt
# 2. Construire l’application Fastapi
Dans cette section, nous créerons un fichier pour la formation du modèle de régression, pour les modèles pydantiques et l’application FastAPI.
Ce ml_model.py gère le modèle d’apprentissage automatique. Il utilise un singleton pour garantir une seule instance du modèle. Le modèle est un régresseur forestier aléatoire formé sur l’ensemble de données de logements en Californie. Si un modèle pré-formé (Model.pkl et Scaler.pkl) n’existe pas, il en entraîne et en sauve un nouveau.
app/ml_model.py:
import os
import threading
import joblib
import numpy as np
from sklearn.datasets import fetch_california_housing
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
class MLModel:
_instance = None
_lock = threading.Lock()
def __new__(cls):
if cls._instance is None:
with cls._lock:
if cls._instance is None:
cls._instance = super().__new__(cls)
return cls._instance
def __init__(self):
if not hasattr(self, "initialized"):
self.model = None
self.scaler = None
self.model_path = "model.pkl"
self.scaler_path = "scaler.pkl"
self.feature_names = None
self.initialized = True
self.load_or_create_model()
def load_or_create_model(self):
"""Load existing model or create a new one using California housing dataset"""
if os.path.exists(self.model_path) and os.path.exists(self.scaler_path):
self.model = joblib.load(self.model_path)
self.scaler = joblib.load(self.scaler_path)
housing = fetch_california_housing()
self.feature_names = housing.feature_names
print("Model loaded successfully")
else:
print("Creating new model...")
housing = fetch_california_housing()
X, y = housing.data, housing.target
self.feature_names = housing.feature_names
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
self.scaler = StandardScaler()
X_train_scaled = self.scaler.fit_transform(X_train)
self.model = RandomForestRegressor(
n_estimators=50, # Reduced for faster predictions
max_depth=8, # Reduced for faster predictions
random_state=42,
n_jobs=1, # Single thread for consistency
)
self.model.fit(X_train_scaled, y_train)
joblib.dump(self.model, self.model_path)
joblib.dump(self.scaler, self.scaler_path)
X_test_scaled = self.scaler.transform(X_test)
score = self.model.score(X_test_scaled, y_test)
print(f"Model R² score: {score:.4f}")
def predict(self, features):
"""Make prediction for house price"""
features_array = np.array(features).reshape(1, -1)
features_scaled = self.scaler.transform(features_array)
prediction = self.model.predict(features_scaled)(0)
return prediction * 100000
def get_feature_info(self):
"""Get information about the features"""
return {
"feature_names": list(self.feature_names),
"num_features": len(self.feature_names),
"description": "California housing dataset features",
}
# Initialize model as singleton
ml_model = MLModel()
Le pydantic_models.py Le fichier définit les modèles pydantiques pour la validation et la sérialisation des données de demande et de réponse.
app/pydantic_models.py:
from typing import List
from pydantic import BaseModel, Field
class PredictionRequest(BaseModel):
features: List(float) = Field(
...,
description="List of 8 features: MedInc, HouseAge, AveRooms, AveBedrms, Population, AveOccup, Latitude, Longitude",
min_length=8,
max_length=8,
)
model_config = {
"json_schema_extra": {
"examples": (
{"features": (8.3252, 41.0, 6.984, 1.024, 322.0, 2.556, 37.88, -122.23)}
)
}
}
app/main.py: Ce fichier est l’application FastAPI principale, définissant les points de terminaison de l’API.
import asyncio
from contextlib import asynccontextmanager
from fastapi import FastAPI, HTTPException
from fastapi.responses import ORJSONResponse
from .ml_model import ml_model
from .pydantic_models import (
PredictionRequest,
)
@asynccontextmanager
async def lifespan(app: FastAPI):
# Pre-load the model
_ = ml_model.get_feature_info()
yield
app = FastAPI(
title="California Housing Price Prediction API",
version="1.0.0",
description="API for predicting California housing prices using Random Forest model",
lifespan=lifespan,
default_response_class=ORJSONResponse,
)
@app.get("/health")
async def health_check():
"""Health check endpoint"""
return {"status": "healthy", "message": "Service is operational"}
@app.get("/model-info")
async def model_info():
"""Get information about the ML model"""
try:
feature_info = await asyncio.to_thread(ml_model.get_feature_info)
return {
"model_type": "Random Forest Regressor",
"dataset": "California Housing Dataset",
"features": feature_info,
}
except Exception:
raise HTTPException(
status_code=500, detail="Error retrieving model information"
)
@app.post("/predict")
async def predict(request: PredictionRequest):
"""Make house price prediction"""
if len(request.features) != 8:
raise HTTPException(
status_code=400,
detail=f"Expected 8 features, got {len(request.features)}",
)
try:
prediction = ml_model.predict(request.features)
return {
"prediction": float(prediction),
"status": "success",
"features_used": request.features,
}
except ValueError as e:
raise HTTPException(status_code=400, detail=str(e))
except Exception:
raise HTTPException(status_code=500, detail="Prediction error")
Points clés:
lifespanGestionnaire: s’assure que le modèle ML est chargé lors du démarrage de l’application.asyncio.to_thread: Ceci est crucial car la méthode de prédire de Scikit-Learn est liée au processeur (synchrone). L’exécuter dans un thread séparé l’empêche de bloquer la boucle d’événements asynchrones de Fastapi, permettant au serveur de gérer d’autres demandes simultanément.
Points de terminaison:
/health: Un simple contrôle de santé./model-info: Fournit des métadonnées sur le modèle ML./predict: Accepte une liste des fonctionnalités et renvoie une prévision des prix des maisons.
run_server.py: Il contient le script qui est utilisé pour exécuter l’application Fastapi à l’aide d’Uvicorn.
import uvicorn
if __name__ == "__main__":
uvicorn.run("app.main:app", host="localhost", port=8000, workers=4)
Tous les fichiers et configurations sont disponibles dans le référentiel GitHub: Kingabzpro / Stress-test-fastapi
# 3. Écriture du test de stress des criquets
Maintenant, créons le script de test de contrainte à l’aide du locuste.
tests/locustfile.py: Ce fichier définit le comportement des utilisateurs simulés.
import json
import logging
import random
from locust import HttpUser, task
# Reduce logging to improve performance
logging.getLogger("urllib3").setLevel(logging.WARNING)
class HousingAPIUser(HttpUser):
def generate_random_features(self):
"""Generate random but realistic California housing features"""
return (
round(random.uniform(0.5, 15.0), 4), # MedInc
round(random.uniform(1.0, 52.0), 1), # HouseAge
round(random.uniform(2.0, 10.0), 2), # AveRooms
round(random.uniform(0.5, 2.0), 2), # AveBedrms
round(random.uniform(3.0, 35000.0), 0), # Population
round(random.uniform(1.0, 10.0), 2), # AveOccup
round(random.uniform(32.0, 42.0), 2), # Latitude
round(random.uniform(-124.0, -114.0), 2), # Longitude
)
@task(1)
def model_info(self):
"""Test health endpoint"""
with self.client.get("/model-info", catch_response=True) as response:
if response.status_code == 200:
response.success()
else:
response.failure(f"Model info failed: {response.status_code}")
@task(3)
def single_prediction(self):
"""Test single prediction endpoint"""
features = self.generate_random_features()
with self.client.post(
"/predict", json={"features": features}, catch_response=True, timeout=10
) as response:
if response.status_code == 200:
try:
data = response.json()
if "prediction" in data:
response.success()
else:
response.failure("Invalid response format")
except json.JSONDecodeError:
response.failure("Failed to parse JSON")
elif response.status_code == 503:
response.failure("Service unavailable")
else:
response.failure(f"Status code: {response.status_code}")
Points clés:
- Chaque utilisateur simulé attendra entre 0,5 et 2 secondes entre l’exécution des tâches.
- Crée des données de fonctionnalités aléatoires réalistes pour les demandes de prédiction.
- Chaque utilisateur fera une demande Health_Check et 3 demandes Single_Prediction.
# 4. Exécution du test de stress
- Pour évaluer les performances de votre application sous charge, commencez par démarrer votre application d’apprentissage automatique asynchrone dans un terminal.
- Ouvrez votre navigateur et accédez à http: // localhost: 8000 / docs. Utilisez la documentation API interactive pour tester vos points de terminaison et assurez-vous qu’ils fonctionnent correctement.
- Ouvrez une nouvelle fenêtre de terminal, activez l’environnement virtuel et accédez au répertoire racine de votre projet pour exécuter Locusst avec l’interface utilisateur Web:
- Dans l’interface utilisateur Web Locust, définissez le nombre total d’utilisateurs sur 500, le taux d’apparition sur 10 utilisateurs par seconde et exécutez-le pendant une minute.
- Pendant le test, Locust affichera des statistiques en temps réel, y compris le nombre de demandes, de défaillances et de temps de réponse pour chaque point de terminaison.
- Une fois le test terminé, cliquez sur l’onglet des graphiques pour afficher les graphiques interactifs montrant le nombre d’utilisateurs, les demandes par seconde et les temps de réponse.
- Pour exécuter Locust sans l’interface utilisateur Web et générer automatiquement un rapport HTML, utilisez la commande suivante:
Model loaded successfully
INFO: Started server process (26216)
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
locust -f tests/locustfile.py --host http://localhost:8000
Accéder à l’interface utilisateur du locasse http://localhost:8089 dans votre navigateur.
locust -f tests/locustfile.py --host http://localhost:8000 --users 500 --spawn-rate 10 --run-time 60s --headless --html report.html
Une fois le test terminé, un rapport HTML nommé Report.html sera enregistré dans votre répertoire de projet pour une revue ultérieure.
# Réflexions finales
Notre application peut gérer un grand nombre d’utilisateurs car nous utilisons un modèle d’apprentissage automatique simple. Les résultats montrent que le point final du modèle-info a un temps de réponse plus élevé que la prédiction, ce qui est impressionnant. Il s’agit du meilleur scénario de cas pour tester votre application localement avant de le pousser à la production.
Si vous souhaitez vivre cette configuration de première main, veuillez visiter le Kingabzpro / Stress-test-fastapi Référentiel et suivez les instructions de la documentation.
Abid Ali Awan (@ 1abidaliawan) est un professionnel certifié des data scientifiques qui aime construire des modèles d’apprentissage automatique. Actuellement, il se concentre sur la création de contenu et la rédaction de blogs techniques sur l’apprentissage automatique et les technologies de science des données. Abid est titulaire d’une maîtrise en gestion technologique et d’un baccalauréat en génie des télécommunications. Sa vision est de construire un produit d’IA en utilisant un réseau de neurones graphiques pour les étudiants aux prises avec une maladie mentale.
Source link



