
Régression vs classification dans l’apprentissage automatique – Pourquoi la plupart des débutants se trompent | M004
- Intelligence Artificielle
 Noesis News
Noesis News- 0
- 18 minutes de lecture
Auteur (s): Ligade mehul
Publié à l’origine sur Vers l’IA.
Régression vs classification dans l’apprentissage automatique – Pourquoi la plupart des débutants se trompent | M004
Si tu apprends Apprentissage automatique Et pensez que l’apprentissage supervisé est simple, détrompez-vous.
Au moment où vous commencez à construire votre premier modèle, vous êtes confronté à une décision que la plupart des tutoriels expliquent à peine: cela devrait-il être un problème de régression ou un problème de classification?
La différence peut sembler évidente – jusqu’à ce que vous gâchiez un projet en prédisant les catégories avec un modèle de régression ou en essayant de forcer la sortie numérique en seaux de classification.
Dans cet article, je vais tout décomposer du sol. Pas seulement les définitions des manuels, mais le processus de réflexion derrière le choix du bon type de modèle. Vous apprendrez ce que ces termes signifient vraiment, comment repérer la différence dans la nature et comment j’approche personnellement de ce choix dans des projets du monde réel.
Et comme toujours, pas de peluches recyclées; Seule l’expérience, les informations et les leçons qui restent réellement.
Plongeons maintenant.
📘 Contenu
- Pourquoi cet article existe
- La vraie question derrière la régression et la classification
- Ce que signifie réellement dans Ml
- Un exemple réel de régression
- Ce que signifie la classification et comment cela fonctionne
- Un exemple réel de classification
- Comment choisir entre eux (avec un guide de décision)
- Mesures d’évaluation que vous devez connaître
- Ce que j’ai appris à la dure
- Réflexions finales: ne choisissez pas seulement les modèles. Comprendre les problèmes.
🔴 Pourquoi cet article existe
J’écris ceci parce que je me suis trompé. Plus d’une fois.
Quand j’ai commencé avec l’apprentissage supervisé, j’ai choisi des modèles comme ils étaient des outils dans une boîte à outils. Régression linéaire pour les nombres. Régression logistique pour oui ou non. C’était ça. Fin de l’histoire.
Mais ensuite j’ai frappé des cas de bord – ensembles de données Cela ressemblait à la classification mais a agi comme une régression. Projets où j’ai utilisé la mauvaise fonction de perte et obtenu des résultats mathématiquement corrects mais pratiquement inutiles. Il est devenu clair pour moi que la distinction entre la régression et la classification ne concerne pas seulement le format de sortie. Il s’agit de comprendre votre problème à un niveau plus profond.
Cet article est donc ce que je souhaite que quelqu’un m’ait remis à l’époque.
–
🔴 La vraie question derrière la régression et la classification
Avant de définir quoi que ce soit, demandez-vous ceci:
Quelle est la nature de la chose que j’essaie de prédire?
Est-ce que j’essaie de prédire une quantité? Quelque chose avec une distance mesurable entre les valeurs – comme le prix, l’âge ou la température?
Ou est-ce que j’essaie de prédire une classe? Une étiquette, une catégorie ou un groupe distinct – comme le chat ou le chien, le spam ou non le spam, la fraude ou le véritable?
C’est la fourche fondamentale de la route.
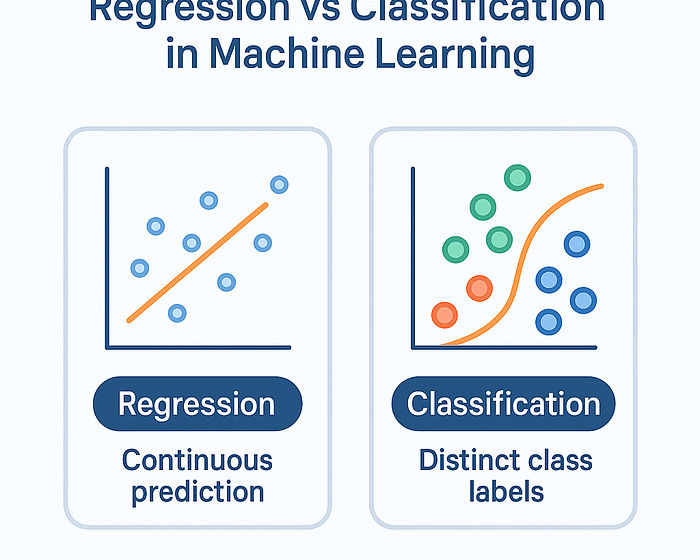
Les problèmes de régression traitent des résultats continus. Vous estimez les valeurs sur une ligne numérique.
Les problèmes de classification traitent des résultats discrets. Vous attribuez des données d’entrée dans l’un des nombreux seaux prédéfinis.
Et chaque modèle, fonction de perte et métriques d’évaluation s’écoulent de ce choix initial.
–
🔴 Ce que signifie réellement la régression en ML
La régression ne concerne pas les graphiques, les pentes ou les lignes. C’est environ l’approximation.
Lorsque vous utilisez la régression, vous demandez au modèle d’apprendre une fonction qui mappe les variables d’entrée à une sortie continue – comme prédire le prix de la maison à partir de la superficie carrée ou prédire le poids de quelqu’un en fonction de l’âge et de la taille.
Mais voici ce qui compte: il n’y a pas d’étiquette «correcte» dans un sens strict. Il n’y a que la proximité. La précision de la régression concerne la distance à laquelle vous êtes de la valeur réelle. C’est pourquoi les modèles de régression minimisent l’erreur – pas les erreurs de classification.
Pensez à ceci: si vous prédisez un prix des maisons à 88,00 000 ₹ alors qu’il est en fait de 90,00 000 ₹, vous êtes sur 2 lakhs. C’est la perte. C’est ce dont nous nous soucions.
Vous n’essayez pas d’obtenir un numéro exact à chaque fois. Vous essayez de vous rapprocher et de se rapprocher constamment.
–
🔴 Un exemple réel de régression
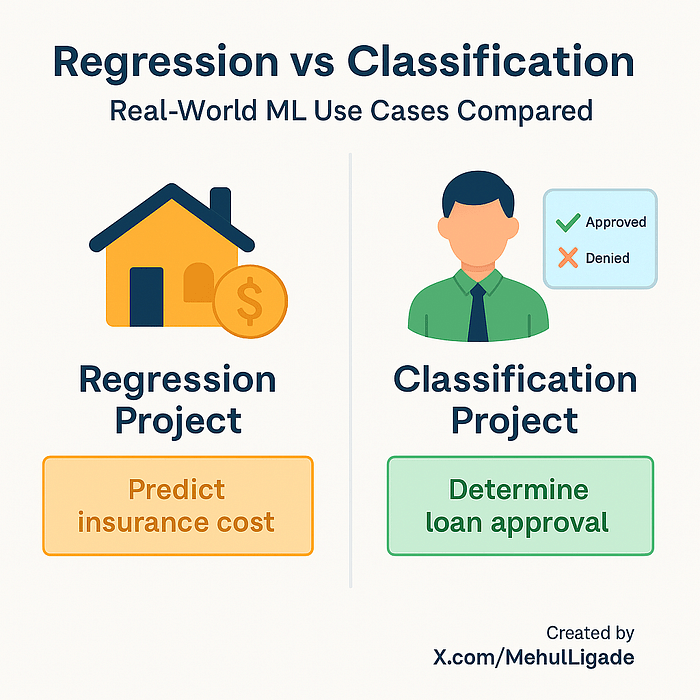
Dans l’un de mes premiers projets, j’ai construit un système pour prédire les frais d’assurance des soins de santé. L’ensemble de données comprenait des facteurs tels que l’âge, l’IMC, le sexe, le statut de tabagisme et l’emplacement. L’objectif était d’estimer le coût de la prime annuelle d’une personne.
Il n’y avait pas de catégories. Juste des chiffres – les montants primes réels des clients précédents.
Il s’agit d’un problème de régression des manuels. La sortie est continue. La distance entre 24 000 et 26 000 ₹ est significative. Une différence de 2 000 ₹ est meilleure qu’une différence de 20 000 ₹.
Mes modèles ont essayé de minimiser l’erreur entre le coût prévu et le coût réel. J’ai utilisé RMSE (Root Mean Squared Error) comme métrique principale. Et même si les chiffres n’étaient pas parfaits, ils se sont approchés pour être précieux pour une réelle prise de décision.
C’est la régression. Apprendre à estimer: ne pas classer.
–
🔴 Ce que signifie la classification et comment cela fonctionne
La classification est différente. Ici, vous prévoyez des catégories.
Vous n’êtes pas intéressé par la valeur de la sortie – uniquement dans quel groupe il se trouve.
C’est le type d’apprentissage utilisé dans des problèmes comme la détection du spam, l’approbation des prêts, analyse des sentimentsdiagnostic médical et reconnaissance d’image.
En classification, vous ne mesurez pas à quel point votre prédiction est proche – vous mesurez si elle est correcte ou non. Il n’y a pas de mi-chemin.
Si vous prédisez qu’une transaction n’est «pas une fraude» et que c’est en fait une «fraude», ce n’est pas une erreur de 40% – c’est une classification erronée à part entière. Le coût de mal peut varier, mais le format est binaire: le bien ou le mal.
Les modèles de classification fonctionnent souvent en estimant les probabilités. Par exemple, un modèle de régression logistique pourrait dire: «Cet e-mail a 92% de chances d’être spam.» Mais à la fin, il doit faire un appel – spam ou non.
La clé est de bien faire les catégories.
–
🔴 Comment choisir entre eux (avec un guide de décision)
Maintenant, voici la question d’or: comment décidez-vous si votre problème est la régression ou la classification?
Demandez-vous:
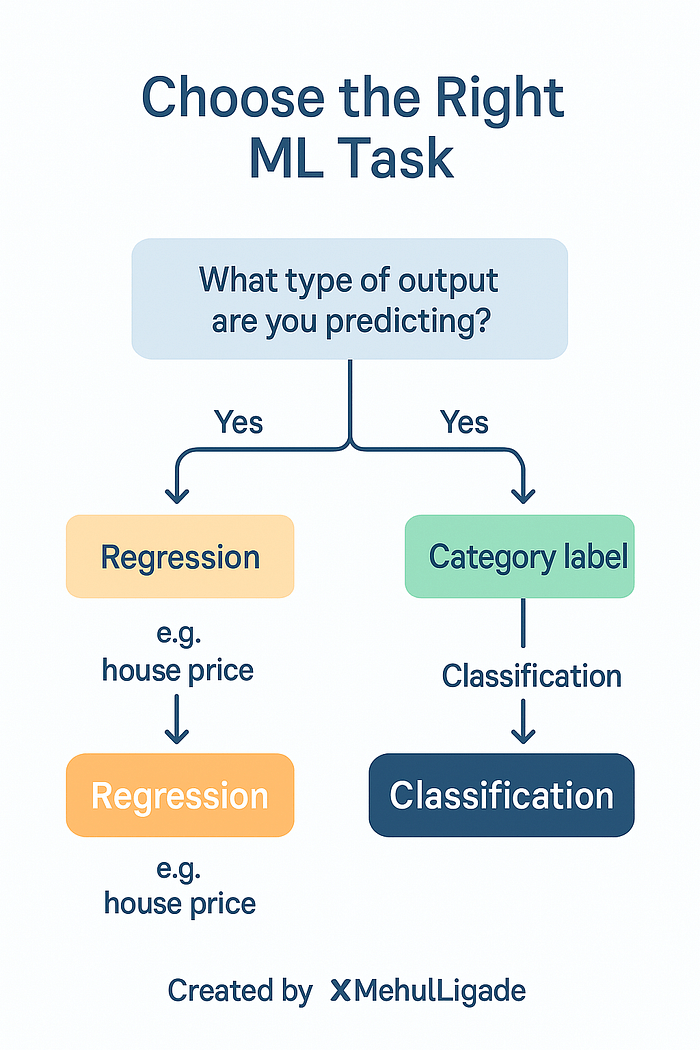
Essayez-vous de prédire une valeur qui tombe à une échelle continue? Si la réponse est oui, c’est probablement une régression. Par exemple, prédire le poids, la vitesse, le coût, le score, la notation ou toute autre mesure numérique.
Essayez-vous d’attribuer une entrée à un groupe prédéfini? Si c’est le cas, c’est la classification. Par exemple, l’identification du sentiment, la détection d’objets, la prévision des diagnostics ou la catégorisation des articles de presse.
Et si vous n’êtes pas sûr, voici un conseil: regardez votre variable cible. S’il a des unités – comme des kilogrammes, des roupies, des degrés ou des centimètres – c’est probablement une régression. S’il a des étiquettes comme «positif», «négatif», «approuvé» ou «rejeté», c’est la classification.
–
🔴 Métriques d’évaluation que vous devez connaître
C’est là que beaucoup de gens se trompent – y compris moi, au début.
Vous ne pouvez pas évaluer les modèles de régression et de classification de la même manière.
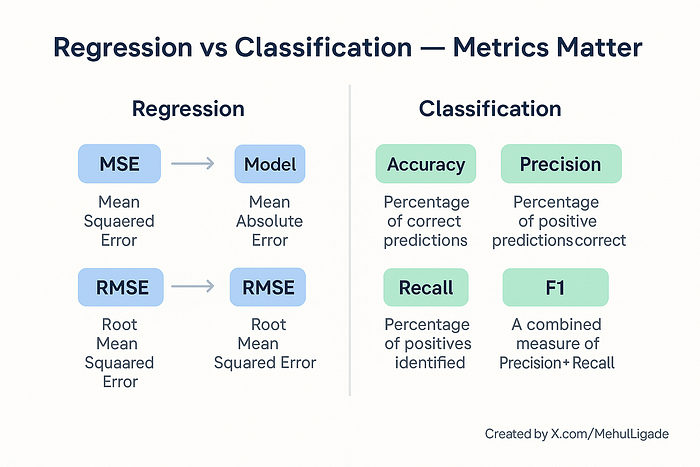
Dans la régression, nous nous soucions de la distance de la prédiction. Des métriques comme l’erreur absolue moyenne, une erreur quadratique moyenne ou une erreur carrée moyenne de racine sont utilisées. Ils vous indiquent à quel point la prédiction est proche de la valeur réelle.
En classification, nous nous soucions de la fréquence à laquelle la prédiction est bonne. Mais la précision seule ne suffit pas toujours – en particulier avec les données déséquilibrées.
Par exemple, dans un modèle de détection de fraude où seulement 1% des transactions sont en fait une fraude, un modèle qui dit «non fraude» pour chaque cas sera précis à 99% – et complètement inutile.
C’est pourquoi nous utilisons d’autres mesures comme la précision, le rappel, le score F1 et l’AUC (zone sous la courbe). Ces mesures nous disent non seulement à quelle fréquence nous avons raison, mais sur la façon dont nous avons raison – et quand c’est important.
Connaître la différence entre les stratégies d’évaluation est tout aussi important que le choix du bon modèle.
–
🔴 Ce que j’ai appris à la dure
Dans l’un de mes modèles précédents, j’essayais de prédire à quel point quelqu’un était susceptible d’acheter un produit.
La colonne cible a été étiquetée «d’achat de vraisemblance» et avait des valeurs entre 0 et 1. J’ai supposé que c’était un problème de régression. J’ai formé un modèle en utilisant RMSE. Les prédictions étaient assez proches.
Mais j’ai ensuite regardé plus profondément et j’ai réalisé que cette cible avait été générée par un modèle précédent. C’était déjà une probabilité. Ce dont j’avais vraiment besoin, c’était une décision de classification: «va acheter» ou «n’achètera pas».
Je l’avais traité comme un problème de régression alors que ce que je voulais vraiment, c’était la classification. Ce décalage entre l’objectif et le cadrage a perdu des semaines d’itération.
Depuis lors, je commence toujours par la même question: «Quelle décision ce modèle aide quelqu’un à prendre?» Cela m’amène presque toujours au bon type de problème.
–
🔴 Réflexions finales: ne choisissez pas seulement les modèles. Comprendre les problèmes.
L’apprentissage automatique est Pas de lancer des algorithmes sur les données. Il s’agit de résoudre de vrais problèmes. Et cela commence par le cadrage de ces problèmes de la bonne façon.
Le choix entre la régression et la classification ne consiste pas à choisir le modèle le plus populaire. Il s’agit de comprendre la forme du résultat que vous essayez de prédire.
Plus vous regardez vos données – en particulier votre variable cible – mieux vos choix seront. Et mieux vos choix, plus vos modèles deviennent fiables.
C’est ainsi que je construis des systèmes ML. Pas seulement en suivant des tutoriels – mais en comprenant ce que le modèle est censé faire et pourquoi.
–
🔴 Ce qui vient ensuite
Dans les prochains articles, je plongerai dans l’évaluation du modèle, l’analyse des erreurs, le sur-ajustement et la façon dont j’ingénie les fonctionnalités qui améliorent réellement les prédictions et non seulement la précision sur papier.
Comme toujours, j’écrirai par expérience. De la curiosité. Des projets du monde réel et des leçons qui collent.
Suivez si vous êtes fatigué des articles moelleux et que vous souhaitez construire des systèmes d’apprentissage automatique qui fonctionnent réellement.
📍 Trouvez-moi ici:
Twitter: x.com/mehulligade
LinkedIn: linkedin.com/in/mehulcode12
Continuons à apprendre une couche plus profonde à la fois.
–
Publié via Vers l’IA
Source link



