
Ragent: Un chuchoteur PDF multi-agent construit sur Langchain + Langgraph
- Intelligence Artificielle
 Noesis News
Noesis News- 0
- 39 minutes de lecture
Auteur (s): Bandyopadhyay dwaipayan
Publié à l’origine sur Vers l’IA.
RLa génération augmentée etrievale est une approche très connue dans le domaine de AI génératifqui se compose généralement d’un flux linéaire de se déchaîner un document, le stockant dans une base de données vectorielle, puis récupérant des morceaux pertinents en fonction de la requête utilisateur et l’alimentation LLM pour obtenir la réponse finale. Ces derniers temps, le terme «IA agentique» a pris d’assaut Internet, en termes simples, il fait référence à la décomposition d’un problème en petites sections et à l’attribuer à certains «agents» qui sont capables de gérer une certaine tâche, et de combiner des agents plus petits comme celui-ci pour construire un flux de travail complexe. Que se passe-t-il si nous combinons cette approche agentique et récupérons la génération augmentée? Dans cet article, nous expliquerons un concept / architecture similaire que nous avons développé à l’aide de Langgraph, Faish et Openai.
Nous n’explorerons pas les agents de l’IA et comment ils fonctionnent dans cet article; Sinon, cela deviendrait un livre à part entière. Mais pour donner un bref aperçu de ce que sont les «agents d’IA», nous pouvons considérer un «agent d’IA» en tant qu’assistant, quelqu’un ou quelque chose qui est un maître dans une tâche particulière, plusieurs agents ayant plusieurs capacités sont additionnés pour faire une réponse complète de l’agent graphique, où chaque agent peut communiquer entre eux, peut comprendre ce que l’agent précédent a été remis en fonction et.
Dans notre approche, nous avons divisé le concept de «génération augmentée de récupération» en trois tâches différentes et créé un agent pour chaque tâche capable de gérer une tâche spécifique, un agent examinera la partie de récupération, tandis que l’autre examinera la partie d’augmentation, et enfin le dernier agent examinera la partie de génération. Ensuite, nous avons combiné les trois agents pour fabriquer un flux de travail agentique de bout en bout. Plongeons profondément dans la section de codage.
La section de codage commence
Premièrement, nous installerons tous les packages nécessaires nécessaires. La meilleure pratique serait de créer d’abord un environnement virtuel, puis d’installer les packages suivants.
Une fois installé avec succès, nous importerons tous les packages nécessaires pour créer d’abord l’agent Retriever.
Codage du retrieveragent:
from langchain_openai import ChatOpenAI
from langchain_community.vectorstores.faiss import FAISS
from langchain_openai import OpenAIEmbeddings
from langchain.docstore.document import Document
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder
from pypdf import PdfReader
import re
from dotenv import load_dotenv
import streamlit as stload_dotenv()
LLM = ChatOpenAI(model_name="gpt-4o", temperature=0.0)
def extract_text_from_pdf(pdf_path):
try:
pdf = PdfReader(pdf_path)
output = ()
for i, page in enumerate(pdf.pages, 1):
text = page.extract_text()
text = re.sub(r"(w+)-n(w+)", r"12", text)
text = re.sub(r"(?, " ", text.strip())
text = re.sub(r"ns*n", "nn", text)
output.append((text, i)) # Tuple of (text, page number)
return output
except Exception as e:
st.error(f"Error reading PDF: {e}")
return ()
def text_to_docs(text_with_pages):
docs = ()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=4000, chunk_overlap=200)
for text, page_num in text_with_pages:
chunks = text_splitter.split_text(text)
for i, chunk in enumerate(chunks):
doc = Document(
page_content=chunk,
metadata={"source": f"page-{page_num}", "page_num": page_num}
)
docs.append(doc)
return docs
def create_vectordb(pdf_path):
text_with_pages = extract_text_from_pdf(pdf_path)
if not text_with_pages:
raise ValueError("No text extracted from PDF.")
docs = text_to_docs(text_with_pages)
embeddings = OpenAIEmbeddings()
return FAISS.from_documents(docs, embeddings)
# Define Tools
def retrieve_from_pdf(query: str, vectordb) -> dict:
"""Retrieve the most relevant text and page number using similarity search."""
# Use similarity_search to get the top result
docs = vectordb.similarity_search(query, k=3) # k=1 for single most relevant result
if docs:
doc = docs(0)
content = f"Page {doc.metadata('page_num')}: {doc.page_content}"
page_num = doc.metadata("page_num")
return {"content": content, "page_num": page_num}
return {"content": "No content retrieved.", "page_num": None}
RETRIEVE_PROMPT = ChatPromptTemplate.from_messages((
("system", """
You are the Retrieve Agent. Your task is to fetch the most relevant text from a PDF based on the user's query.
- Use the provided retrieval function to get content and a single page number.
- Return the content directly with the page number included (e.g., 'Page X: text').
- If no content is found, return "No content retrieved."
"""),
MessagesPlaceholder(variable_name="chat_history"),
("human", "{query}"),
))
Explication du code –
Dans ce code d’agent Retriever, premièrement, nous importons tous les modules et classes nécessaires, nous stockons nos informations d’identification, telles que la clé API OpenAI, dans un .env Fichier, c’est pourquoi le module Dotenv a été utilisé ici aux côtés de l’appel Fonction Load_Dotenv. Ensuite, nous initialisons le LLM en fournissant des arguments requis tels que le nom du modèle, la température, etc.
Descriptions des fonctions
extract_text_from_pdf est utilisé pour lire et extraire le contenu du PDF et le nettoyer un peu en fixant des ruptures de ligne en dyphéné, qui provoquent la rupture d’un mot en deux pièces, convertissant les lignes de New Lines en espaces à moins qu’elles fassent partie de l’espacement des paragraphes, etc. Le processus de nettoyage est effectué sur la page, c’est pourquoi une boucle est appliquée sur le nombre de pages en utilisant la fonction énumérée. Enfin, à partir de cette fonction, le contenu extrait nettoyé est renvoyé aux côtés de ses paginumbers est renvoyé comme une forme de liste de tuples. Si une erreur indésirable se produit, cela peut également être géré via le essai à l’exception bloc utilisé; Cela garantit que le code fonctionne parfaitement sans se casser en raison d’erreurs.
text_to_docs est utilisé pour faire Se déchaînerici le RecursiveCaracterTextSplitter La classe du module Langchain est utilisée, chaque taille de morceau serait de 4000, et le chevauchement serait de 200. Ensuite, une boucle est effectuée sur l’argument text_with_pages, qui recevra la sortie de la fonction précédente, c’est-à-dire extract_text_from_pdf, car il renvoie la sortie dans un format de liste de tuples. Deux variables sont utilisées dans la boucle pour considérer les deux éléments du tuple. Ensuite, le texte nettoyé est divisé en morceaux et converti en un objet de document, qui sera davantage utilisé pour les convertir en intégres. Outre le contenu de la page, l’objet Document conservera le numéro de page et une étiquette de chaîne, y compris le numéro de page sous forme de métadonnées. Chaque document sera ensuite annexé sur une liste et retourné.
create_vectordb Cette fonction utilise les deux fonctions ci-dessus pour créer des incorporations à l’aide de VectorStore de FAISS (Facebook AI Simility Search). Il s’agit d’un magasin vectoriel léger qui stocke l’index localement et aide à effectuer facilement des recherches. Cette fonction crée et renvoie la base de données vectorielle. C’est ça.
rétrive_from_pdf Dans cette fonction, nous effectuons la recherche de similitude et obtenons les 3 premiers morceaux, et si nous trouvons, alors nous considérons le premier morceau uniquement pour qu’il se compose du contenu le plus similaire et de le renvoyer avec son numéro de page en tant que dictionnaire.
Le rétrive_prompt est un chatPromptmplate composé de l’instruction, c’est-à-dire un message système pour le LLM, mentionnant son emploi En tant qu’agent Retriever. Il considérera également la totalité de l’historique de chat d’une session particulière et acceptera la requête utilisateur comme une entrée humaine.
Coder l’agent d’augmentateur
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder
from typing import Optionaldef augment_with_context(content: str, page_num: Optional(int)) -> str:
"""Augment retrieved content with source context."""
if content != "No content retrieved." and page_num:
return f"{content}nnAdditional context: Sourced from page {page_num}."
return f"{content}nnAdditional context: No specific page identified."
AUGMENT_PROMPT = ChatPromptTemplate.from_messages((
("system", """
You are the Augment Agent. Enhance the retrieved content with additional context.
- If content is available, append a note with the single page number.
- If no content is retrieved, return "No augmented content."
"""),
MessagesPlaceholder(variable_name="chat_history"),
("human", "Retrieved content: {retrieved_content}nPage number: {page_num}"),
))
Explication des fonctions
augment_with_context Il s’agit d’une approche très simple où nous recherchons des informations supplémentaires du PDF fourni pour solidifier les informations récupérées par l’agent de récupération. S’il est trouvé, le contenu supplémentaire, à côté de son numéro de page, sera ajouté au contenu récupéré d’origine; Sinon, si les deux ne sont pas trouvés, il renverra simplement le même contenu original sans aucune modification
L’AUGMENT_PROMPT est à nouveau très simple, ce ne sont que des informations pour le LLM de rechercher des informations qui solidifieront le contenu récupéré par l’agent de récupération, qui est également considéré comme le chat_history, et les variables récupérées_content et page_num seront remplies automatiquement par le LLM pendant l’exécution.
Codage du générateur de fonds
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholderGENERATE_PROMPT = ChatPromptTemplate.from_messages((
("system", """
You are the Generate Agent. Create a detailed response based on the augmented content.
- Focus on DBMS and SQL content.
- Append "Source: Page X" at the end if a page number is available.
- If the user query consists of terms like "explain", "simple", "simplify" etc. or relatable, then do not return any page number, otherwise return the proper page number.
- If the question is not DBMS-related, reply "Not applicable."
- Use the chat history to maintain context.
"""),
MessagesPlaceholder(variable_name="chat_history"),
("human", "{query}nAugmented content: {augmented_content}"),
))
L’agent de générateur ne se compose que de l’interrompu avec l’instruction de la façon de générer une réponse finale en fonction du contenu récupéré ainsi que des informations supplémentaires augmentées à partir des deux étapes précédentes.
Après que tous ces agents distincts soient créés, il est temps de les stocker sous un seul parapluie et de former l’intégralité du flux de travail de bout en bout à l’aide de Langgraph.
Code de la création de graphiques à l’aide de Langgraph
import streamlit as st
from langgraph.graph import StateGraph, END
from typing import TypedDict, List, Optional
import re
from IPython.display import display, Image
from retriever import (LLM,extract_text_from_pdf,text_to_docs,create_vectordb,retrieve_from_pdf,RETRIEVE_PROMPT)
from augmentation import augment_with_context,AUGMENT_PROMPT
from generation import GENERATE_PROMPT
from dotenv import load_dotenvload_dotenv()
PDF_FILE_PATH = "dbms_notes.pdf"
# Define the Agent State
class AgentState(TypedDict):
query: str
chat_history: List(dict)
retrieved_content: Optional(str)
page_num: Optional(int) # Single page number instead of a list
augmented_content: Optional(str)
response: Optional(str)
def format_for_display(text):
def replace_latex(match):
latex_expr = match.group(1)
return f"$${latex_expr}$$" # Use $$ for Streamlit Markdown to render LaTeX
text = re.sub(r'\frac{((^})+)}{((^})+)}', r'$\frac{1}{2}$', text)
return text
# Define Multi-Agent Nodes
def retrieve_agent(state: AgentState) -> AgentState:
chain = RETRIEVE_PROMPT | LLM
retrieved = retrieve_from_pdf(state("query"), st.session_state.vectordb)
response = chain.invoke({"query": state("query"), "chat_history": state("chat_history")})
#print(retrieved)
return {
"retrieved_content": retrieved('content'),
"page_num": retrieved("page_num")
}
def augment_agent(state: AgentState) -> AgentState:
chain = AUGMENT_PROMPT | LLM
if state("retrieved_content") and state("retrieved_content") != "No content retrieved.":
# Prepare input for the LLM
input_data = {
"retrieved_content": state("retrieved_content"),
"page_num": str(state("page_num")) if state("page_num") else "None",
"chat_history": state("chat_history")
}
# Invoke the LLM to generate augmented content
response = chain.invoke(input_data)
augmented_content = response.content # Use the LLM's output
else:
augmented_content = "No augmented content."
return {"augmented_content": augmented_content}
def generate_agent(state: AgentState) -> AgentState:
chain = GENERATE_PROMPT | LLM
response = chain.invoke({
"query": state("query"),
"augmented_content": state("augmented_content") or "No augmented content.",
"chat_history": state("chat_history")
})
return {"response": response.content}
# Define Conditional Edge Logic
def decide_augmentation(state: AgentState) -> str:
if state("retrieved_content") and state("retrieved_content") != "No content retrieved.":
return "augmentation"
return "generation"
workflow = StateGraph(AgentState)
workflow.add_node("retrieve_agent", retrieve_agent)
workflow.add_node("augment_agent", augment_agent)
workflow.add_node("generate_agent", generate_agent)
workflow.set_entry_point("retrieve_agent")
workflow.add_conditional_edges(
"retrieve_agent",
decide_augmentation,
{
"augmentation": "augment_agent",
"generation": "generate_agent"
}
)
workflow.add_edge("augment_agent", "generate_agent")
workflow.add_edge("generate_agent", END)
agent = workflow.compile()
# display(Image(agent.get_graph().draw_mermaid_png(output_file_path="tutor_agent.png")))
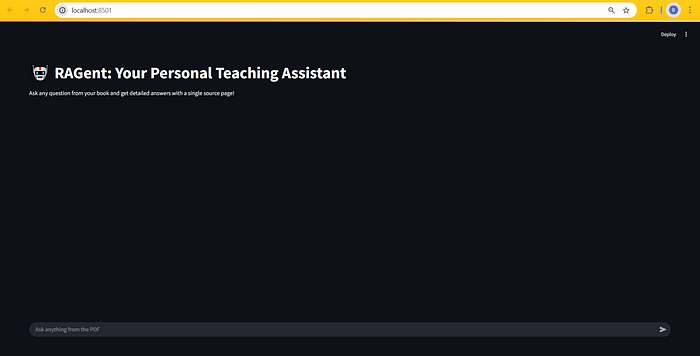
st.set_page_config(page_title="🤖 RAGent", layout="wide")
st.title("🤖 RAGent : Your Personal Teaching Assistant")
st.markdown("Ask any question from your book and get detailed answers with a single source page!")
# Initialize session state for vector database
if "vectordb" not in st.session_state:
with st.spinner("Loading PDF content... This may take a minute."):
try:
st.session_state.vectordb = create_vectordb(PDF_FILE_PATH)
except Exception as e:
st.error(f"Failed to load PDF: {e}")
st.stop()
# Initialize chat history in session state
if "messages" not in st.session_state:
st.session_state.messages = ()
# Display chat history
for message in st.session_state.messages:
with st.chat_message(message("role")):
st.markdown(message("content"))
# User input
user_input = st.chat_input("Ask anything from the PDF")
if user_input:
# Add user message to chat history
st.session_state.messages.append({"role": "user", "content": user_input})
with st.chat_message("user"):
st.markdown(user_input)
# Display assistant response
with st.chat_message("assistant"):
message_placeholder = st.empty()
# Prepare chat history for the agent
chat_history = (
{"type": "human", "content": msg("content")} if msg("role") == "user" else
{"type": "ai", "content": msg("content")}
for msg in st.session_state.messages(:-1) # Exclude current input
)
# Prepare initial state
initial_state = {
"query": user_input,
"chat_history": chat_history,
"retrieved_content": None,
"page_num": None,
"augmented_content": None,
"response": None, # Add field for Ragas sample
}
# Run the agent with a spinner
with st.spinner("Processing..."):
final_state = agent.invoke(initial_state)
answer = final_state("response")
formatted_answer = format_for_display(answer)
# Display response
message_placeholder.markdown(formatted_answer)
# Update chat history
st.session_state.messages.append({
"role": "assistant",
"content": formatted_answer
})
Explication du code
Classe d’agentState – Dans cette classe, nous définissons un schéma qui sera appliqué en plus de la réponse LLM et l’ensemble de «l’état» portera cette même structure tout au long du flux de travail. Cela sera adopté comme argument lors de la création d’État.
Fonction Format_For_Display – Cette fonction a une fonction imbriquée, qui sera utilisée pour gérer les sorties basées sur le latex. Nous l’utilisons parce que le document peut contenir des fractions qui pourraient ne pas être gérées correctement par rationalisation, donc en utilisant cela comme une précaution supplémentaire.
Fonction Retrieve_agent – Cela utilisera la fonction rétrive_from_pdf que nous avons définie précédemment. Tout d’abord, nous créerons une chaîne à l’aide de l’invite de récupération et de LLM. Ensuite, invoquez-le à l’aide de la requête fournie par l’utilisateur, qui n’est rien d’autre que la question de l’utilisateur, et considérez également l’intégralité de Chat_history, et enfin il renverra le contenu et le numéro de page.
fonction augment_agent – Ici, nous allons à nouveau créer une chaîne à l’aide de l’augment_prompt, cette fois et vérifierons si l’agent Retriever a renvoyé un contenu ou non. S’il a renvoyé un contenu, nous appellerons la fonction augment_with_context et passerons le contenu récupéré, le numéro de page, ainsi que le chat_history, renvoyez le contenu fourni par la réponse.
Fonction générée_agent – Ici, enfin, nous passons le contenu augmenté, la requête de l’utilisateur et l’historique de chat afin que LLM puisse tirer parti du contenu augmenté et générer la réponse finale en fonction des informations augmentées et l’afficher à l’utilisateur.
Fonction décide_augmentation – Il s’agit d’une étape facultative fournie pour vérifier s’il est nécessaire que l’agent d’augmentation s’exécute ou non.
Une fois que tous les agents nécessaires sont créés, il est temps de les combiner pour créer un flux de travail de bout en bout, qui se fera en utilisant la classe StateGraph de Langgraph. Lors de l’initialisation de la classe StateGraph, nous passerons la classe AgentState que nous avons définie plus tôt comme son paramètre pour indiquer que pendant l’ensemble du flux de travail, ce sont les seules clés qui seront là dans la réponse, rien d’autre. Ensuite, nous ajoutons les nœuds dans le Stategraph pour créer l’intégralité du flux de travail, en configurant manuellement le point d’entrée pour faire comprendre à quel nœud sera exécuté en premier, en ajoutant des bords entre les nœuds pour indiquer à quoi ressemblera le flux de travail, en ajoutant un avantage conditionnel entre les deux pour signifier que le nœud connecté au bord conditionnel, peut être appelé pendant le travail de travail à chaque temps.
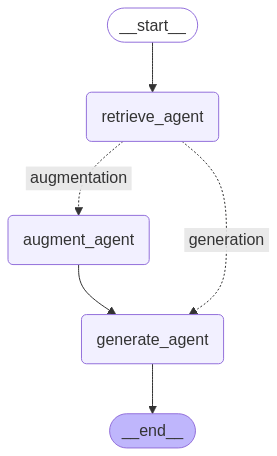
Enfin, la compilation de l’ensemble du flux de travail pour vérifier si tout fonctionne bien et que le graphique créé est approprié ou non. Nous pouvons afficher le graphique à l’aide du module IPython et de la méthode d’encre de sirène. Le graphique ressemblera ci-dessous, si tout se passe correctement.
Ensuite, le reste du code est entièrement basé sur le rationalisation. L’utilisateur peut concevoir l’interface utilisateur en fonction de son choix. Nous avons adopté une approche très basique dans la conception de l’interface utilisateur, afin qu’elle reste conviviale. Nous envisageons également certains états de session, donc pour maintenir l’historique de chat, la requête utilisateur, etc. Cela ne démarrera pas sans la saisie de l’utilisateur, ce qui signifie que jusqu’à et à moins que l’utilisateur ne fournisse une requête, le workflow ne démarre pas.
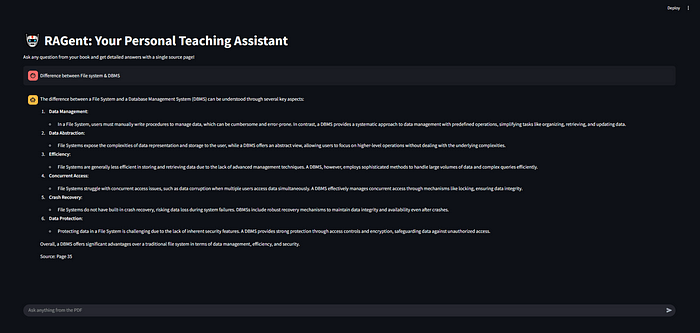
Captures d’écran de l’application en état de fonctionnement –
Cet article a été écrit en collaboration avec Biswajit das
Publié via Vers l’IA
Source link



