
(R) transfert des intérêts pré-entraînés
- Intelligence Artificielle
 Noesis News
Noesis News- 0
- 4 minutes de lecture
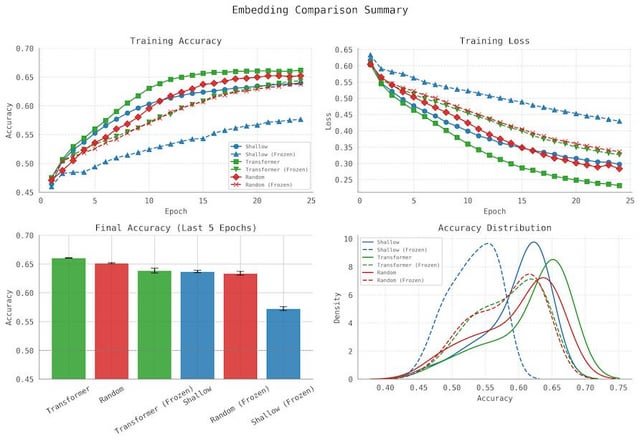
|
Tout en travaillant avec des vocabulaires personnalisés et des architectures de modèle, j’ai rencontré des preuves que la transférabilité des couches d’intégration à différentes tâches / architectures est plus efficace qu’on ne le pensait auparavant. Lorsque des différences telles que la dimensionnalité, les décalages de vocabulaire sont contrôlés, la source de l’incorporation semble faire une plus grande différence, même lorsqu’elle est gelée, et même lorsqu’elle est déplacée dans une architecture de transformateur différente avec un modèle d’attention différent. Quelqu’un d’autre examine-t-il cela? La plupart des recherches que j’ai trouvées mélangent des composants du codeur et du décodeur pendant le transfert ou se concentrent sur la réutilisation de modèles complets plutôt que d’isoler les intérêts. Dans ma configuration, je ne transfère que le couche d’incorporation– soit d’un LLM (Transformer) ou un modèle d’incorporation peu profond– en aval fixe modèle de notation formé à partir de zéro. Cela me permet d’évaluer directement la transférabilité et l’utilité inductive des intérêts eux-mêmes, indépendants du reste de l’architecture. Comment puis-je rendre cela plus rigoureux ou utile? Quels types de lignes de base ou de cibles de transfert rendraient cela plus convaincant? Est-ce digne d’une enquête plus approfondie? Un travail connexe, mais rien ne fait la même chose:
Heureux de partager plus de détails si les gens sont intéressés. (Avertissement: écrit par un humain, édité avec Chatgpt) soumis par / u / arkamedus |




{kind=link}