
(R) sont des courbes AUC / ROC "boîte noire" métrique?
- Intelligence Artificielle
 Noesis News
Noesis News- 0
- 5 minutes de lecture
|
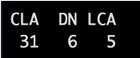
Salut les gars! (Mon premier post ici, pls soyez gentil hehe) Je suis un doctorant (relativement nouveau pour l’IA) travaillant avec des modèles ML pour une tâche de classification multi-classes. Étant donné que j’ai exclu la précision comme la métrique d’évaluation étant donné un déséquilibre de classe dans mes données (précision paradoxe), je suis resté collé à l’AUC et en traçant les courbes ROC (comme quelques articles ont dit qu’ils sont bons pour les ensembles de train déséquilibrés) pour évaluer les performances d’un modèle de forêt aléatoire (10 fois validé) formé sur un jeu de données désagréable et testé sur un jeu de données indépendant. J’ai essayé Satin pour travailler sur le déséquilibre, mais cela ne semblait pas aider mon cas car il y a un chevauchement majeur dans la distribution des instances de données dans chacune des classes que j’ai (CLA, LCA, DN) et les échantillons synthétiques générés étaient juste un bruit aléatoire au lieu d’être représentatif de la classe minoritaire. Récemment, lorsque j’essayais de tirer les prévisions de classe par le modèle, j’ai remarqué une des classes ayant 0 instances classées en dessous. Mais la courbe ROC a dit le contraire (photos ci-jointes). Compte tenu de ma surveillance, je pensais que DN a brillé, car il avait juste quelques échantillons dans le test de test, mais ce n’était pas le cas avec LCA (qui avait moins d’échantillons). Puis je suis descendu dans le trou de lapin de ce que ROC et AUC signifiaient réellement. C’est ce que je pensais et aimerais plus de perspicacité sur ce que vous pensez et ce que cela peut signifier, ce qui pourrait diriger mes prochaines étapes. Le modèle attribue des scores de probabilité plus élevés aux vrais échantillons DN que les échantillons non DN (CLA et LCA), mais en ce qui concerne les prédictions du modèle, les probabilités ne sont pas en mesure de passer le seuil sélectionné. Est-ce une bonne interprétation? Si oui, j’ai pensé à ces étapes: – Réglez le seuil manuellement en jetant un coup d’œil à la distribution des probabilités (dont je suis toujours sceptique) – Abandonnez probablement ROC et AUC comme les mesures d’évaluation (je me suis menti tout ce temps!) Si vous pensez que je suis un peu parti sur ce qui se passe, vos idées aideraient vraiment, merci beaucoup! Échantillons de fréquences dans l’ensemble de tests d’origine soumis par / u / pure_landscape8863 |




{kind=link}
{kind=link}
{kind=link}