
(R) (P) Nous compressons n’importe quel modèle BF16 à ~ 70% de taille pendant l’inférence, tout en gardant la sortie sans perte afin que vous puissiez s’adapter à plus de contexte ou exécuter des modèles plus grands.
- Intelligence Artificielle
 Noesis News
Noesis News- 0
- 12 minutes de lecture
|
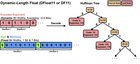
Heureux de partager un autre travail intéressant de notre part: Taille de 70%, 100% Précision: compression LLM sans perte pour l’inférence GPU efficace via un flotteur de longueur dynamique (DF11) Le tl; dr de ce travail est super simple. Nous – et plusieurs travaux antérieurs – avons remarqué que pendant que BF16 est souvent promu comme une alternative «plus d’autonomie, moins de précision» au FP16 (en particulier pour éviter le débordement / sous-flux de valeur pendant la formation), Sa partie de plage (bits d’exposants) finit par être assez redondante une fois le modèle formé. En d’autres termes, bien que BF16 en tant que format de données puisse représenter un large éventail de nombres, la plupart des représentants de modèles formés sont très rares. En pratique, les bits d’exposants transportent environ 2,6 bits d’informations réelles en moyenne – loin des 8 bits qui leur sont attribués. Cela ouvre la porte au codage classique de Huffman – où des séquences de bits plus courtes sont affectées à des valeurs plus fréquentes – à comprimer les poids du modèle dans un nouveau format de données que nous appelons Dfloat11 / df11résultant en un Compression sans perte jusqu’à ~ 11 bits. Mais n’est-ce pas simplement zip?Pas exactement. Il est vrai que des outils comme Zip exploitent également le codage Huffman, mais la partie délicate ici est Rendre sa mémoire efficace pendant l’inférencecomme les utilisateurs finaux ne seront probablement pas trop trilletés si cela rend les téléchargements de point de contrôle de modèle un peu plus rapidement (en toute honnêteté, les petits Chekpoints signifient beaucoup lors de la formation à grande échelle, mais ce n’est pas un problème pour les utilisateurs de tous les jours). Ce qui compte pour les utilisateurs quotidiens, c’est Rendre l’empreinte de la mémoire plus petite pendant l’inférence du GPU, ce qui nécessite des efforts non triviaux. Mais nous l’avons compris et nous avons ouvert le code. Alors maintenant, vous pouvez:
Certains postes de promotion de la recherche tentent de surgir leur faiblesse ou leur compromis, ce n’est pas nous. Voici donc quelques FAQ honnêtes: Quelle est la prise?Comme tous les travaux de compression, il y a un coût à la décompression. Et voici quelques rapports d’efficacité.
Pourquoi ne pas simplement (perte) quantifier à 8 bits?La réponse courte est que vous devez totalement le faire si vous êtes satisfait de la quantification à 8 bits perdante de sortie par rapport à votre tâche. Mais comment savez-vous vraiment que c’est toujours bon? De nombreuses littératures de référence suggèrent que la compression d’un modèle (en poids uniquement ou autre) à 8 bits est généralement une opération sûre, même si elle est techniquement perte. Ce que nous avons trouvé, cependant, c’est que même si cette affirmation est souvent faite dans les documents de quantification, leurs références ont tendance à se concentrer sur des tâches générales comme le MMLU et le raisonnement de bon sens; qui ne présentent pas une image complète de la capacité du modèle. Des références plus difficiles – telles que celles impliquant un raisonnement complexe – et les préférences des utilisateurs réelles révèlent souvent des différences notables. Un bon exemple est que Chatbot Arena indique le 8 bits (bien qu’il soit W8A8 où le DF11 est uniquement du poids, il n’est donc pas 100% pomme à pair) et 16 bits LLAMA 3.1 405B ont tendance à se comporter tout à fait différemment sur certaines catégories de tâches (par exemple, mathématiques et codage). Bien que la question plus large: « Quelle tâche spécifique, sur quel modèle, en utilisant quelle technique de quantification, dans quelles conditions, conduiront à une baisse notable par rapport à FP16 / BF16? » est susceptible de rester ouvert simplement en raison de la quantité de combinaisons potentielles et de la définition de «notable». Il est juste de dire que la quantification avec perte introduit des complexités que certains utilisateurs finaux préféreraient éviter, car il crée des variables incontrôlées qui doivent être testées empiriquement pour chaque scénario de déploiement. DF11 propose une alternative qui évite cette préoccupation à 100%. Qu’en est-il de Finetuning?Notre méthode pourrait potentiellement bien s’associer à des méthodes PEFT comme Lora, où les poids de base sont congelés. Mais comme nous compressons le bloc, nous ne pouvons pas simplement l’appliquer naïvement sans casser les gradients. Nous explorons activement cette direction. Si cela fonctionne, il deviendrait potentiellement une alternative Qlora où vous pouvez perdre Lora Finetune un modèle avec une empreinte mémoire réduite. (Comme toujours, heureux de répondre à des questions ou de discuter jusqu’à ce que mon conseiller remarque que je suis en train de faire un décollage social pendant les heures de travail:>) soumis par / u / chohz |




{kind=link}