
(R) Amélioration des modèles de gros langues avec un réglage fin concept
- Intelligence Artificielle
 Noesis News
Noesis News- 0
- 3 minutes de lecture
|
Tl; dr: CAFT permet une prédiction multi-token pour le réglage fin. Améliore les performances via une meilleure compréhension conceptuelle. Papier: https://www.arxiv.org/abs/2506.07833 Code: https://github.com/michaelchen-lab/caft-llm Motivations:
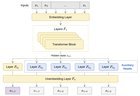
Architecture: Les têtes auxiliaires sont d’abord formées afin de faciliter le réglage fin multi-token sur les modèles suivants. Cela ne doit être formé qu’une seule fois pour un modèle donné et peut être fourni par un tiers, donc les praticiens ont seulement besoin de se concentrer sur l’application de CAFT à leur tâche spécifique. Après le réglage fin, les têtes auxiliaires sont jetées, il n’y a donc pas de coûts supplémentaires à l’inférence. Résultats: Des gains de performances substantiels dans le codage, les mathématiques, le résumé de texte, la génération moléculaire et la conception de protéines de novo. soumis par / u / Micky04 |




{kind=link}