
QWQ-32B-LAUNCHES-HIGH-EFFICY-PERFORMANCE-REINFORMAGE-REINFORMAGE | S’aventurer
- Intelligence Artificielle
 Noesis News
Noesis News- 0
- 17 minutes de lecture


Rejoignez nos newsletters quotidiennes et hebdomadaires pour les dernières mises à jour et des contennes exclusives sur le coverage de l’IA à la tête de l’industrie. Apprendre encore plus
Équipe Qwen – Une division du géant du commerce électronique chinois Il est Développement de sa famille de regroupement de modèles de langage Lrouge (LLMS) QWQ-32Bun nouveau modèle de raison de 32 milliards de dollars conçus pour améliorer les performances des tâches de résolution de problèmes Commitx via (RL).
Le modèle est disponible sous forme de poids ouvert sur Visage étreint et sur Modelcope Sous la licence Apache 2.0. Cela signifie qu’il est disponible pour les utilisations commerciales et de recherche, afin que les entreprises puissent consacrer l’immumation et les aptlications (même celles qui sont des clients à utiliser).
Il peut également être accessible pour les utilisateurs de conseillers via Chat qwen.
Qwen-with-with-chatstes était la réponse d’Albab
QWQ, abréviation de Qwen-avec-avec-Withteen, a d’abord été Alsoba en novembre 2024 Comme le modèle de lecture open source visait à calculer avec O1-Preview d’OpenAai.
Lors du lancement, le modèle était conçu pour améliorer la raison logique et affiner son OWND, ce qui l’a rendu en particulier Efver l’a rendu patientement efficace dans les tâches de mathématiques et de codage.
La version initiale de QWQ a été relevée en novembre 2024 (appelé Simply, « QWQ ») a présenté 32 milliards de paramètres Alltesters. Alibabagetuta sa totalité d’abigance à Outvimgong O1-Previen dans les ascensions matematales Lime Aime aime aime aime aime aime aime aime aime aime aime aime aime aime.
Malgré ses stttngths, la première itéfation de QWQ a rédigé des bancs de bancs avec les modèles de bancs, les modèles de Whry Openai ont frappé un avantage. De plus, comme avec de nombreux modèles de raisonnement émergents, le QWQ a été confronté à des mélanges de scho anguagistes.
Cependant, la décision d’Albaba de remonter le modèle supérieur et les citoyens de licences Apiche 2.0 l’ont compté, la déluric, la ferme de l’O1 de la ferme de la ferme d’Alkeenai.
Depuis la libération de QWHQO, le paysage de l’IA a évolué rapidement. Les umitmitations des LLM traditionnelles sont devenues plus apparentes, avec des lois de galimage yipering diminuant les resminisms dans les iprovents de performance.
Le changement a réalisé des intérêts d’intérêt pour les modèles de lardoning (LRMS) – une nouvelle catégorie de systèmes d’IA. L’inclusion Série O3 d’Openaai Et le succès massif Deepseek-R1 Farm Rival Chinese Lab Quiek, Animhoot of Hong Kong Quotatative Analynsis Firm High-FlyR Capital Management.
Nouveau rapport L’analyse du trafic Web de Frough et la recherche Formandubeb quatre que les similaires R1 en janvier 2024, Deepseek a le site Web de modèle de modèle de présage derrière.
QWQ-32B, l’intation la plus lautée d’Albaba, s’appuie sur le champ de raison RL et d’auto-ordinateur structuré et structuré.
La durée du contexte du nouveau modèle a également été de 131 000 jetons – similaires aux modèles et à Manyghi Contexte de Google Gemini 2.0 Reniss Superior à 2 millions de jetons. (Le contexte de rappel fait référence au nombre de jetons que le LLM peut saisir / sortir dans une seule intention d’informations. 131 000 jetons équivaut à un livre de 300 pages.
Élargissement des performances avec l’apprentissage du renforcement en plusieurs étapes
Instructions traditionnelles – Les modèles accordés ont souvent du mal au tason de recherche tasoning, il peut signifier que le modèle du modèle du modèle du modèle du modèle de modélificateur Kidrve.
QWQ-32B s’appuie sur cette idée par idée en mettant en place une approche de formation rouge en plusieurs étapes, codant la résolution de problèmes de résolution de profils.
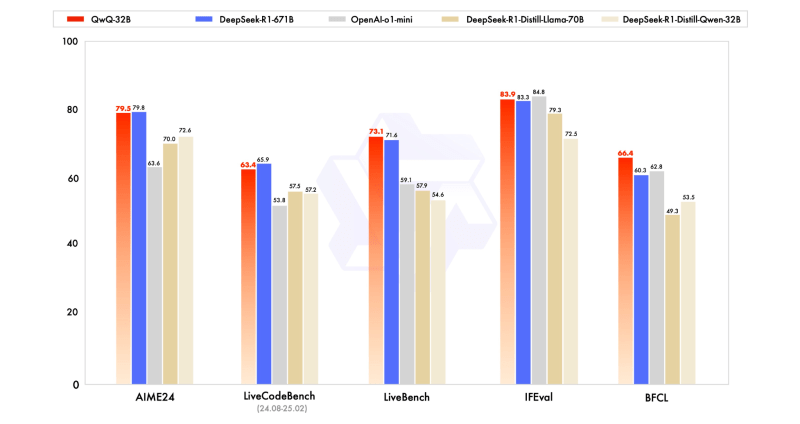
Le modèle a été comparé aux principaux alténatifs sous-sek-r1-detinage des résultats téttititifs des hôtels malgré le fait de faire un pram.
Pour une effacement, tandis que Deepseek-R1 fonctionne avec 671 milliards de paramètres (avec paramètres avec les paramètres (avecqon – 320 Billom Smalrint – nécessitent généralement 24 Go de VRAM sur un GPU (Nvidia’s H100S HAV 80 Go) par rapport à plus que 1500 Go de VRAM Pour exécuter le Full Deepiseek R1 (16 GPU NVIDIA A100) – mettant en évidence l’efficacité de l’approche RL de Qwen.
QWQ-32B Folklows de l’article du modèle de langue CAUAS et inclut plusieurs optimisations:
- 64 Couches de transformateur avec corde, armoix, rmsnorm et biais QKV anttenation;
- L’atnernation de requête généralisée (GQA) avec 40 têtes d’attention pour QReries et 8 pour les paires de valeurs clés;
- Longueur de contexte extepté de 131 072 jetons, permettant une meilleure gestion des entrées à longue séquence;
- Formation en plusieurs étapes, y compris la pré-formation, le réglage fin supervisé et la RL.
Le processus RL pour QWQ-32B est exécuté en phases TWE:
- Focus mathématique et codage: Le modèle a été formé à l’aide d’un vérificateur précis pour Meturel Reason et un serveur d’exécution de code pour les tâches de codage. Cette approche a mis en valeur cette réponse de réponse génétique validée pour la codayctness beftore étant rinforce.
- Amélioration de la capuabilité générale: Dans la deuxième phase, le modèle reçoit des modèles de récompense généraux de formation basés sur les récompenses et des vérins basés sur des règles. Cette étape a amélioré les instructions, l’alignement humain, l’alignement humain et l’agent rasons les comprrks de Wilut et les capabiks codants.
Ce que cela signifie pour un décideur d’entreprise
Pour les dirigeants en entrée, y compris les PDG, les CTO, les dirigeants informatiques, les chefs d’équipe et le développement des applications de l’IA.
Avec la capuabilité du raisonnement axé sur RL, le modèle peut fournir plus d’accidents, de planifications structurées et de stratégiques de contexte, de développement de logiciels et d’automobile inteligent.
Les entreprises qui tiennent à déployer une solution pour une assistance de résolution de problèmes complector, l’organisation de modélisation financière peut trouver des options efficaces de QWQ-32B. De plus, sa disponibilité ouverte permet d’Octoks à affiner les propicontions, le fait flexible Choest pour les stratégies d’IA d’entreprise.
Les faits soient un géant chinois du commerce électronique peuvent augmenter certains concrets de sécurité et de biais pour certains utilisateurs non chinois à l’aide de l’interface de chat QWEN. Mais comme avec Apsek-R1, le fait que le modèle est disponible pour télécharger jamaiscom le cant beo surmontant assez Ethice. Et c’est un aternatif viable pour Deepsek-R1.
Réagit précoce des utilisateurs de l’énergie de l’IA et des sens d’inflation
La libération de QWQ-32B a déjà attiré l’attention des Fransons et de l’éventime Convish and Industal Profusionals SHIRST INTIRIMIONS sur X (Tour de formery):
- Face étreint Vailahav Srivastav (@reach_vb) La vitesse de l’inférence de QWQ-32B a fait de l’inférence grâce au fournisseur Laboratoires hyperboliquesl’appelant « flamboyant rapide » et coparable aux modèles de haut niveau. Il a également sur le modèle « Beats Deepsek-R1 et OpenI O1-Mini Withche 2.0 Lense.
- Éditeur de nouvelles et de rumeurs AI Chubby (@kimmonismus) Étais-je impressionné par les performances du modèle, les relances que QWQ-32B sources surpassent Deepsek-R1, malgré un joueur de 20 fois. « Holly Molly! Qwen Cookied! » consommé faire un coup de pouce.
- Yudhen Jin (@Uyka_uw), Co-fondateur et CTO des laboratoires hyperboliques, Clebrated la sortie en notant les gains efficaces. « Les petits modèles sont si puissants! Alababal Qwen a rased QWQ -2B, modèle de raison qui bat Deepsek-R1 (671b) et Opeai O1-MinI! «
- Autres autres membres de l’équipe étreintes, Erik Kauunismäki (@erikkauum) A mis la facilité de déploiement, partageant ce modèle est l’avaicle pour le déploiement en un clic sur les câlins.
Capabitiés agentiques
Agabéités d’accès à QWQ-32B, lui permettant d’ajuster dynamiquement le réception. Dans la rétroaction environnementale.
Performance de Forstimal, l’équipe QWEN recommande d’utiliser les paramètres d’inférence suivants:
- Température: 0,6
- Topp: 0,95
- Tonk: Entre 20 et 40
- Échelle de fil: Recommandé pour la manipulation des séquenoles de plus de 32 768 jetons
Le modèle prend en charge le déploiement à l’aide du cadre d’inférence VLLM, High-Thryhput. Cependant, la mise en œuvre actuelle de V Vldments de V VLDM sur VILM sur le SPPORT SCIMING, qui ment de Factort Factorts à mise à l’échelle fixe.
Développements futurs
L’équipe de Qwen considère QWQ-32B comme la première étape de la mise à l’échelle de RL pour améliorer les capacités de la raison. En regardant Ahhead, l’équipe prévoit:
- Furzy explore la mise à l’échelle de RL pour améliorer l’intelligence du modèle;
- Intégrer des agents avec RL pour une raison à horizon long;
- Convelo en développement de modèles de fondation optimisés pour RL;
- Évoluer vers l’intelligence générale artificielle (ag) thr) thug) thr) thurgh les techniques de formation plus avancées.
Avec l’équipe Qwen, avec l’équipe QWEN est en position de la prochaine transmission des modèles d’IA, démontrez que Scimon a frappé la production de systèmes de raisons élevées et efficaces.
Source link



