
Que fait les __slots__ de Python?
- Intelligence Artificielle
 Noesis News
Noesis News- 0
- 23 minutes de lecture

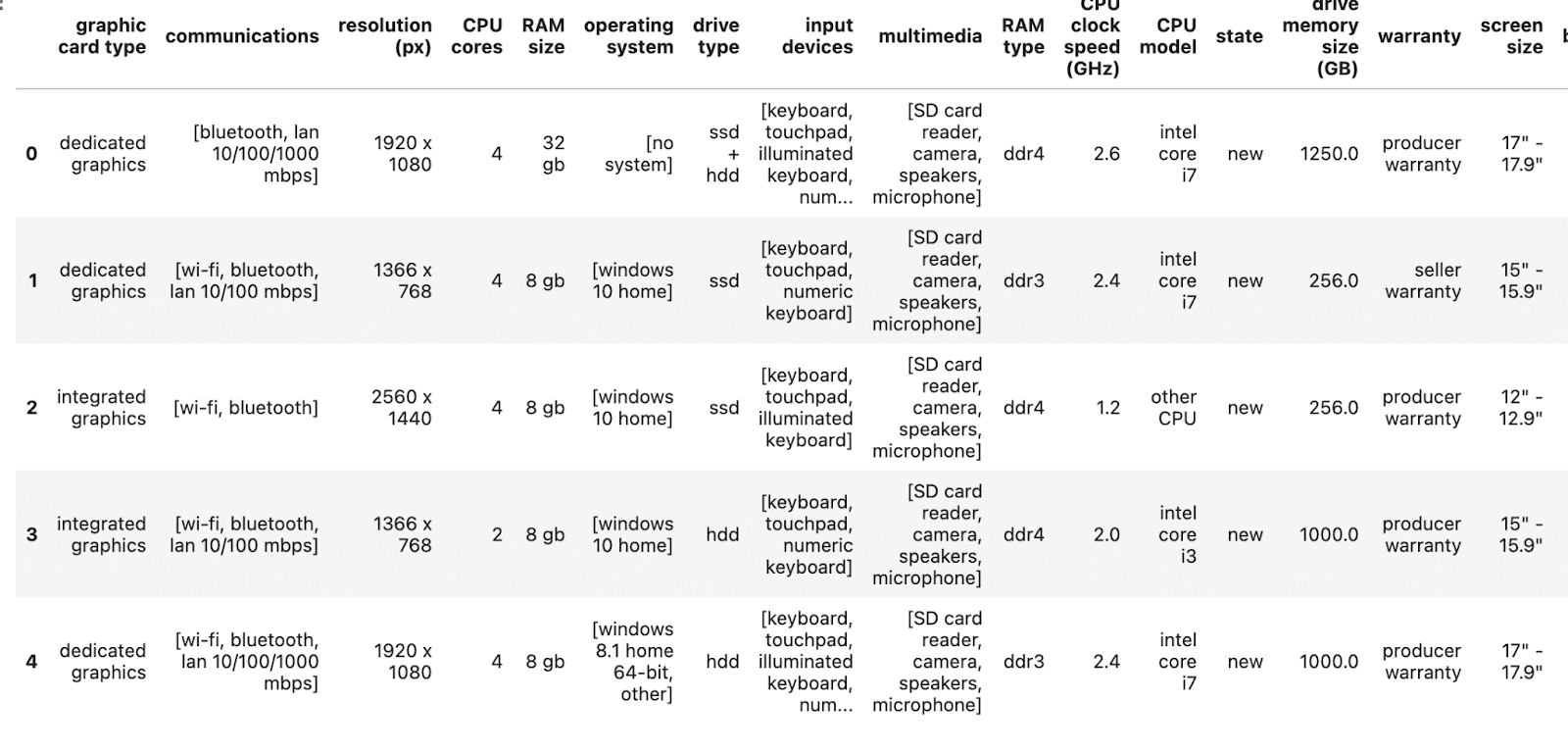

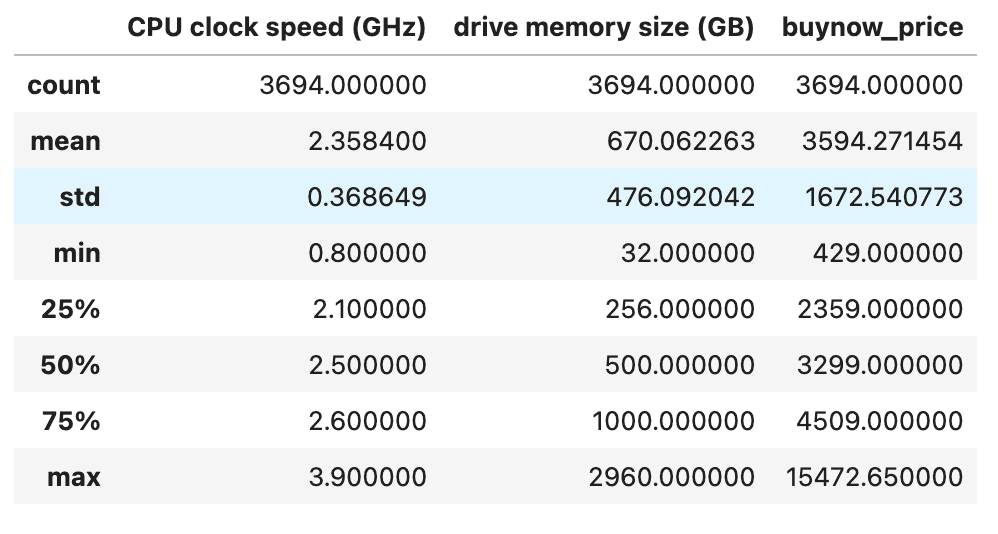




Image de l’auteur | Toile
Et s’il existe un moyen de rendre votre code Python plus rapidement? __slots__ Dans Python est facile à mettre en œuvre et peut améliorer les performances de votre code tout en réduisant l’utilisation de la mémoire.
Dans cet article, nous parcourons la façon dont il fonctionne en utilisant un projet de science des données du monde réel, où Allegro l’utilise comme un défi pour leur processus de recrutement en science des données. Cependant, avant d’entrer dans ce projet, construisons une solide compréhension de ce __slots__ fait.
Qu’est-ce que __slots__ Dans Python?
Dans Python, chaque objet garde un dictionnaire de ses attributs. Cela vous permet de les ajouter, de les modifier ou de les supprimer, mais cela a également un coût: mémoire supplémentaire et accès d’attribut plus lent.
Le __slots__ La déclaration indique à Python que ce sont les seuls attributs dont cet objet aura besoin. C’est une sorte de limitation, mais cela nous fera gagner du temps. Voyons avec un exemple.
class WithoutSlots:
def __init__(self, name, age):
self.name = name
self.age = age
class WithSlots:
__slots__ = ('name', 'age')
def __init__(self, name, age):
self.name = name
self.age = age
Dans la deuxième classe, __slots__ dit à Python de ne pas créer de dictionnaire pour chaque objet. Au lieu de cela, il se réserve un point fixe en mémoire pour le nom et les valeurs d’âge, ce qui le rend plus rapide et la réduction de l’utilisation de la mémoire.
Pourquoi utiliser __slots__?
Maintenant, avant de démarrer le projet de données, nommons la raison pour laquelle vous devriez utiliser __slots__.
- Mémoire: les objets prennent moins de place lorsque Python saute la création d’un dictionnaire.
- Vitesse: l’accès aux valeurs est plus rapide car Python sait où chaque valeur est stockée.
- Bogues: cette structure évite les bugs silencieux car seuls ceux définis sont autorisés.
Utiliser le défi de la science des données d’Allegro comme exemple
Dans ce projet de données, Allegro a demandé aux candidats en science des données de prédire les prix des ordinateurs portables en construisant des modèles d’apprentissage automatique.
Lien vers ce projet de données: https://platform.stratascratch.com/data-projects/laptop-price-prediction
Il existe trois ensembles de données différents:
- Train_dataset.json
- val_dataset.json
- test_dataset.json
Bien. Continuons le processus d’exploration des données.
Exploration des données
Maintenant chargons l’un d’eux pour voir la structure de l’ensemble de données.
with open('train_dataset.json', 'r') as f:
train_data = json.load(f)
df = pd.DataFrame(train_data).dropna().reset_index(drop=True)
df.head()
Voici la sortie.
Bon, voyons les colonnes.
Voici la sortie.
Maintenant, vérifions les colonnes numériques.
Voici la sortie.
Exploration des données avec __slots__ vs cours réguliers
Créons une classe appelée SlottedDataExploration, qui utilisera le __slots__ attribut. Il n’autorise qu’un seul attribut appelé DF. Voyons le code.
class SlottedDataExploration:
__slots__ = ('df')
def __init__(self, df):
self.df = df
def info(self):
return self.df.info()
def head(self, n=5):
return self.df.head(n)
def tail(self, n=5):
return self.df.tail(n)
def describe(self):
return self.df.describe(include="all")
Voyons maintenant l’implémentation, et au lieu d’utiliser __slots__ Utilisons des cours réguliers.
class DataExploration:
def __init__(self, df):
self.df = df
def info(self):
return self.df.info()
def head(self, n=5):
return self.df.head(n)
def tail(self, n=5):
return self.df.tail(n)
def describe(self):
return self.df.describe(include="all")
Vous pouvez en savoir plus sur le fonctionnement des méthodes de classe Méthodes de classe Python guide.
Comparaison des performances: référence temporelle
Mesurer maintenant les performances en mesurant le temps et la mémoire.
import time
from pympler import asizeof # memory measurement
start_normal = time.time()
de = DataExploration(df)
_ = de.head()
_ = de.tail()
_ = de.describe()
_ = de.info()
end_normal = time.time()
normal_duration = end_normal - start_normal
normal_memory = asizeof.asizeof(de)
start_slotted = time.time()
sde = SlottedDataExploration(df)
_ = sde.head()
_ = sde.tail()
_ = sde.describe()
_ = sde.info()
end_slotted = time.time()
slotted_duration = end_slotted - start_slotted
slotted_memory = asizeof.asizeof(sde)
print(f"⏱️ Normal class duration: {normal_duration:.4f} seconds")
print(f"⏱️ Slotted class duration: {slotted_duration:.4f} seconds")
print(f"📦 Normal class memory usage: {normal_memory:.2f} bytes")
print(f"📦 Slotted class memory usage: {slotted_memory:.2f} bytes")
Voyons maintenant le résultat.
La durée de la classe à fente est plus rapide de 46,45%, mais l’utilisation de la mémoire est la même pour cet exemple.
Apprentissage automatique en action
Maintenant, dans cette section, continuons avec l’apprentissage automatique. Mais avant de le faire, faisons un train et testons.
Train et test de la scission
Maintenant, nous avons trois ensembles de données différents, Train, Val et Test, alors trouvons d’abord leurs indices.
train_indeces = train_df.dropna().index
val_indeces = val_df.dropna().index
test_indeces = test_df.dropna().index
Il est maintenant temps d’attribuer ces indices pour sélectionner facilement ces ensembles de données à l’étape suivante.
train_df = new_df.loc(train_indeces)
val_df = new_df.loc(val_indeces)
test_df = new_df.loc(test_indeces)
Génial, formaons maintenant ces cadres de données parce que Numpy veut le format plat (n, n,) au lieu de
le (n, 1). Pour ce faire, nous avons besoin d’utiliser .ravel () après to_numpy ().
X_train, X_val, X_test = train_df(selected_features).to_numpy(), val_df(selected_features).to_numpy(), test_df(selected_features).to_numpy()
y_train, y_val, y_test = df.loc(train_indeces)(label_col).to_numpy().ravel(), df.loc(val_indeces)(label_col).to_numpy().ravel(), df.loc(test_indeces)(label_col).to_numpy().ravel()
Appliquer des modèles d’apprentissage automatique
import numpy as np
import pandas as pd
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import RandomForestRegressor
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.ensemble import ExtraTreesRegressor
from sklearn.ensemble import VotingRegressor
from sklearn import linear_model
from sklearn.neural_network import MLPRegressor
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler, MaxAbsScaler
import matplotlib.pyplot as plt
from sklearn import tree
import seaborn as sns
def rmse(y_true, y_pred):
return mean_squared_error(y_true, y_pred, squared=False)
def regression(regressor_name, regressor):
pipe = make_pipeline(MaxAbsScaler(), regressor)
pipe.fit(X_train, y_train)
predicted = pipe.predict(X_test)
rmse_val = rmse(y_test, predicted)
print(regressor_name, ':', rmse_val)
pred_df(regressor_name+'_Pred') = predicted
plt.figure(regressor_name)
plt.title(regressor_name)
plt.xlabel('predicted')
plt.ylabel('actual')
sns.regplot(y=y_test,x=predicted)
Ensuite, nous définirons un dictionnaire de régresseurs et exécuterons chaque modèle.
regressors = {
'Linear' : LinearRegression(),
'MLP': MLPRegressor(random_state=42, max_iter=500, learning_rate="constant", learning_rate_init=0.6),
'DecisionTree': DecisionTreeRegressor(max_depth=15, random_state=42),
'RandomForest': RandomForestRegressor(random_state=42),
'GradientBoosting': GradientBoostingRegressor(random_state=42, criterion='squared_error',
loss="squared_error",learning_rate=0.6, warm_start=True),
'ExtraTrees': ExtraTreesRegressor(n_estimators=100, random_state=42),
}
pred_df = pd.DataFrame(columns =("Actual"))
pred_df("Actual") = y_test
for key in regressors.keys():
regression(key, regressors(key))
Voici les résultats.
Maintenant, implémentez cela avec les emplacements et les classes régulières.
Apprentissage automatique avec __slots__ vs cours réguliers
Vérifions maintenant le code avec des emplacements.
class SlottedMachineLearning:
__slots__ = ('X_train', 'y_train', 'X_test', 'y_test', 'pred_df')
def __init__(self, X_train, y_train, X_test, y_test):
self.X_train = X_train
self.y_train = y_train
self.X_test = X_test
self.y_test = y_test
self.pred_df = pd.DataFrame({'Actual': y_test})
def rmse(self, y_true, y_pred):
return mean_squared_error(y_true, y_pred, squared=False)
def regression(self, name, model):
pipe = make_pipeline(MaxAbsScaler(), model)
pipe.fit(self.X_train, self.y_train)
predicted = pipe.predict(self.X_test)
self.pred_df(name + '_Pred') = predicted
score = self.rmse(self.y_test, predicted)
print(f"{name} RMSE:", score)
plt.figure(figsize=(6, 4))
sns.regplot(x=predicted, y=self.y_test, scatter_kws={"s": 10})
plt.xlabel('Predicted')
plt.ylabel('Actual')
plt.title(f'{name} Predictions')
plt.grid(True)
plt.show()
def run_all(self):
models = {
'Linear': LinearRegression(),
'MLP': MLPRegressor(random_state=42, max_iter=500, learning_rate="constant", learning_rate_init=0.6),
'DecisionTree': DecisionTreeRegressor(max_depth=15, random_state=42),
'RandomForest': RandomForestRegressor(random_state=42),
'GradientBoosting': GradientBoostingRegressor(random_state=42, learning_rate=0.6, warm_start=True),
'ExtraTrees': ExtraTreesRegressor(n_estimators=100, random_state=42)
}
for name, model in models.items():
self.regression(name, model)
Voici la demande de classe ordinaire.
class MachineLearning:
def __init__(self, X_train, y_train, X_test, y_test):
self.X_train = X_train
self.y_train = y_train
self.X_test = X_test
self.y_test = y_test
self.pred_df = pd.DataFrame({'Actual': y_test})
def rmse(self, y_true, y_pred):
return mean_squared_error(y_true, y_pred, squared=False)
def regression(self, name, model):
pipe = make_pipeline(MaxAbsScaler(), model)
pipe.fit(self.X_train, self.y_train)
predicted = pipe.predict(self.X_test)
self.pred_df(name + '_Pred') = predicted
score = self.rmse(self.y_test, predicted)
print(f"{name} RMSE:", score)
plt.figure(figsize=(6, 4))
sns.regplot(x=predicted, y=self.y_test, scatter_kws={"s": 10})
plt.xlabel('Predicted')
plt.ylabel('Actual')
plt.title(f'{name} Predictions')
plt.grid(True)
plt.show()
def run_all(self):
models = {
'Linear': LinearRegression(),
'MLP': MLPRegressor(random_state=42, max_iter=500, learning_rate="constant", learning_rate_init=0.6),
'DecisionTree': DecisionTreeRegressor(max_depth=15, random_state=42),
'RandomForest': RandomForestRegressor(random_state=42),
'GradientBoosting': GradientBoostingRegressor(random_state=42, learning_rate=0.6, warm_start=True),
'ExtraTrees': ExtraTreesRegressor(n_estimators=100, random_state=42)
}
for name, model in models.items():
self.regression(name, model)
Comparaison des performances: référence temporelle
Comparons maintenant chaque code à celui que nous avons fait dans la section précédente.
import time
start_normal = time.time()
ml = MachineLearning(X_train, y_train, X_test, y_test)
ml.run_all()
end_normal = time.time()
normal_duration = end_normal - start_normal
normal_memory = (
ml.X_train.nbytes +
ml.X_test.nbytes +
ml.y_train.nbytes +
ml.y_test.nbytes
)
start_slotted = time.time()
sml = SlottedMachineLearning(X_train, y_train, X_test, y_test)
sml.run_all()
end_slotted = time.time()
slotted_duration = end_slotted - start_slotted
slotted_memory = (
sml.X_train.nbytes +
sml.X_test.nbytes +
sml.y_train.nbytes +
sml.y_test.nbytes
)
print(f"⏱️ Normal ML class duration: {normal_duration:.4f} seconds")
print(f"⏱️ Slotted ML class duration: {slotted_duration:.4f} seconds")
print(f"📦 Normal ML class memory usage: {normal_memory:.2f} bytes")
print(f"📦 Slotted ML class memory usage: {slotted_memory:.2f} bytes")
time_diff = normal_duration - slotted_duration
percent_faster = (time_diff / normal_duration) * 100
if percent_faster > 0:
print(f"✅ Slotted ML class is {percent_faster:.2f}% faster than the regular ML class.")
else:
print(f"ℹ️ No speed improvement with slots in this run.")
memory_diff = normal_memory - slotted_memory
percent_smaller = (memory_diff / normal_memory) * 100
if percent_smaller > 0:
print(f"✅ Slotted ML class uses {percent_smaller:.2f}% less memory than the regular ML class.")
else:
print(f"ℹ️ No memory savings with slots in this run.")
Voici la sortie.
Conclusion
En empêchant la création de dynamique __dict__ Pour chaque instance, Python __slots__ sont très bons pour réduire l’utilisation de la mémoire et accélérer l’accès aux attributs. Vous avez vu comment cela fonctionne dans la pratique grâce à l’exploration des données et aux tâches d’apprentissage automatique à l’aide du projet de recrutement réel d’Allegro.
Dans les petits ensembles de données, les améliorations pourraient être mineures. Mais à mesure que les données de données, les avantages deviennent plus visibles, en particulier dans les applications liées à la mémoire ou aux performances.
Nate Rosidi est un scientifique des données et en stratégie de produit. Il est également professeur auxiliaire qui enseigne l’analyse et est le fondateur de Stratascratch, une plate-forme aidant les scientifiques des données à se préparer à leurs entretiens avec de véritables questions d’entrevue de grandes entreprises. Nate écrit sur les dernières tendances du marché de la carrière, donne des conseils d’entrevue, partage des projets de science des données et couvre tout SQL.
Source link



