
Préparer des caractéristiques continues pour les réseaux de neurones avec Gaussrank
- Intelligence Artificielle
 Noesis News
Noesis News- 0
- 8 minutes de lecture




Nous présentons une nouvelle méthode pour la transformation des caractéristiques, semblable à la normalisation. La méthode vient de Michael Jahrer, qui a récemment remporté une autre compétition et a ensuite partagé l’approche qu’il a utilisée.
Il y a quelques choses d’intérêt général pour le rédaction. Par exemple, il confirme à nouveau que le renforcement du gradient est beaucoup plus rapide et beaucoup plus facile à utiliser que les réseaux de neurones tout en fournissant des résultats similaires. Michael a utilisé LightGBM:
Belle bibliothèque, très rapide, parfois meilleure que xgboost en termes de précision. Un modèle dans l’ensemble. J’ai réglé des paramètres sur CV.
Pour les réseaux de neurones, Jahrer propose une méthode non standard qui fonctionnait apparemment mieux que la normalisation ou la normalisation. Il l’appelle RANKGAUSS:
La normalisation des entrées pour les modèles basés sur le gradient telles que les NETs neuronaux est critique. Pour LightGBM / XGB, cela n’a pas d’importance. Le meilleur de ce que j’ai trouvé pendant le passé et travaille tout droit de la boîte est «Rankgauss». C’est basé sur la transformation de rang.
La première étape consiste à attribuer un lispace aux fonctionnalités triées de -1… 1, puis à appliquer l’inverse de la fonction d’erreur Erfinv pour les façonner comme des Gaussiens, puis je soustrère la moyenne. Les caractéristiques binaires ne sont pas touchées par ce Trafo (par exemple 1-hot). Cela fonctionne généralement beaucoup mieux que l’échelle moyenne / std standard ou Min / Max.
Même si le nom Rankgauss reflète l’ordre des deux étapes de la méthode, nous préférons «Gaussrank». Cela sonne mieux.
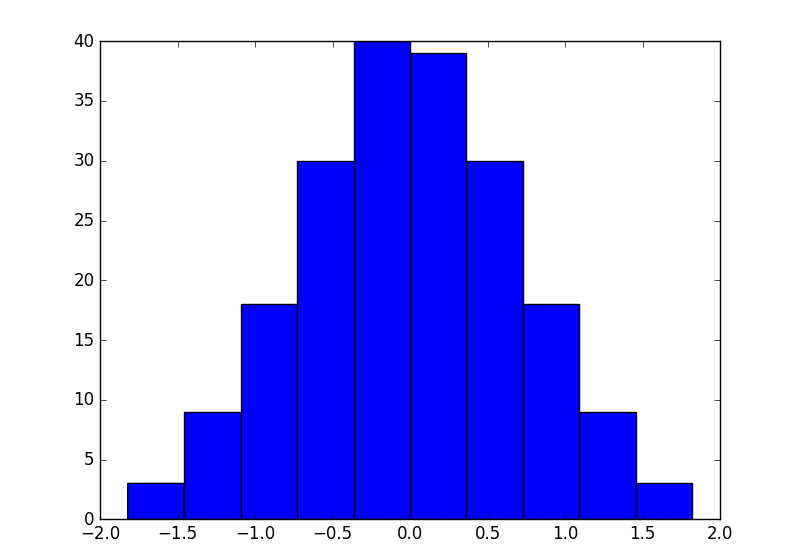
Pour l’implémenter, nous calculons d’abord les rangs pour chaque valeur dans une colonne donnée (argsort). Ensuite, nous normalisons les rangs pour aller de -1 à 1. Ensuite, nous appliquons le mystérieux erfinv fonction. Le but de cela est de faire la distribution des rangs transformés gaussiens.
En fait, Erfinv (-1) est -inf et erfinv (1) est infirmenous devons donc tenir compte de cela.
import numpy as np
import matplotlib.pyplot as plt
from scipy.special import erfinv
# simulating normalized ranks from -0.99 to 0.99
x = np.arange( -0.99, 1, 0.01 )
y = erfinv( x )
plt.hist( y )
La soustraction de la moyenne n’est pas vraiment nécessaire car elle est très proche de zéro.
In (33): y.mean()
Out(33): 1.7495775905650709e-15
En pratique
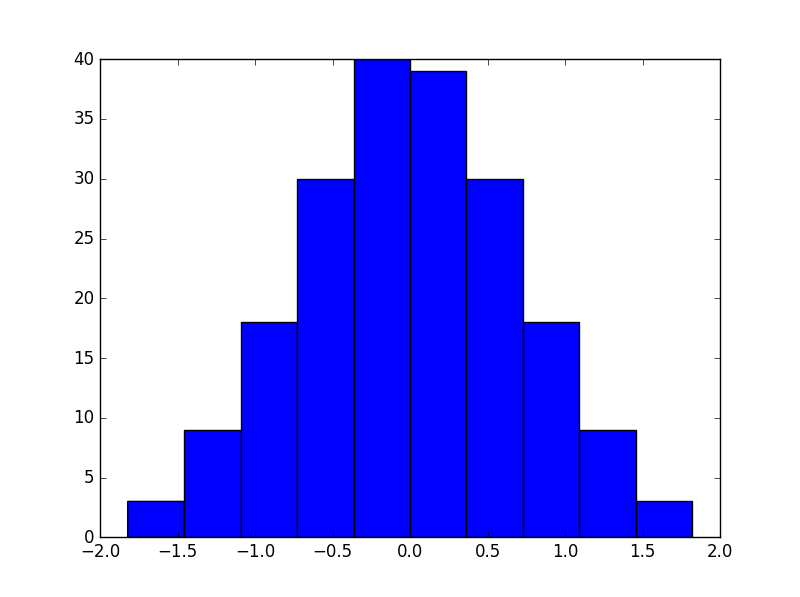
Pour savoir comment cela fonctionne, nous avons testé la méthode sur le kin8nm ensemble de données. Les fonctionnalités de l’ensemble de données, huit au total, sont distribuées plus ou moins uniformément. Voici un histogramme des deux premiers de l’ensemble de formation:
En revanche, la variable cible:
Nous avons mis en œuvre fit_predict () Méthode pour Gaussrank, car c’est beaucoup plus facile que d’écrire séparément ajuster() et prédire() Méthodes. La façon de l’utiliser pour prendre les fonctionnalités à la fois de la formation et des ensembles de tests et de l’ajustement / transformée ensuite conjointement. C’est OK, car nous n’utilisons aucune étiquette.
L’histogramme des deux premières caractéristiques après transformation:
Pour les réseaux de neurones, nous avons utilisé des keras et effectué une recherche d’hyperparam avec Hyperbandepour deux versions de l’ensemble de données: avec et sans Gaussrank.
Le meilleur score que nous avons obtenu avec la version originale était de 8,14% RMSE, qui est proche de ce que nous avons réalisé avec Pybrain il y a quelque temps. Pour la version transformée, il était de 10,86%. Par conséquent, nous devons conclure que Gaussrank ne fonctionne pas bien avec l’ensemble de données.
À titre de comparaison, nous avons également transformé les données avec Projections aléatoiresgardant la même dimensionnalité. Notez que cette méthode transforme la matrice X dans son ensemble, au lieu du schéma colonne par colonne de Gaussrank.
Cette version a donné encore plus d’impressionnant 13,27% RMSE. Ce n’est pas une surprise, car il est peu probable que les projections aléatoires non surveillées soient en général avec une meilleure représentation pour l’apprentissage supervisé.
Données, code et résultats Pour les expériences, sont disponibles sur GitHub.
Source link



