
Précision, coût et performance avec les modèles Nvidia Nemotron
- Intelligence Artificielle
 Noesis News
Noesis News- 0
- 11 minutes de lecture
Chaque semaine, de nouveaux modèles sont publiés, ainsi que des dizaines de repères. Mais qu’est-ce que cela signifie pour un praticien de décider quel modèle utiliser? Comment devraient-ils aborder l’évaluation de la qualité d’un modèle nouvellement publié? Et comment les capacités de référence comme le raisonnement se traduisent-elles en valeur réelle?
Dans cet article, nous évaluerons le nouvellement sorti Nvidia Llama Nemotron Super 49b 1.5 modèle. Nous utilisons syftrnotre cadre génératif d’exploration et d’évaluation du flux de travail de l’IA, pour fonder l’analyse dans un problème commercial réel et explorer les compromis d’une analyse multi-objectifs.
Après avoir examiné plus de mille workflows, nous proposons des conseils exploitables sur les cas d’utilisation où le modèle brille.
Le nombre de paramètres comptez, mais ce n’est pas tout
Il n’est pas surprenant que le nombre de paramètres entraîne une grande partie du coût du service des LLM. Les poids doivent être chargés dans la mémoire et les matrices de valeur clé (KV) mises en cache. Les modèles plus grands fonctionnent généralement mieux – les modèles frontaliers sont presque toujours massifs. Les progrès du GPU ont été fondamentaux à l’essor de l’IA en permettant à ces modèles de plus en plus grands.
Mais l’échelle seule ne garantit pas les performances.
De nouvelles générations de modèles surpassent souvent leurs prédécesseurs plus grands, même au même nombre de paramètres. Le Nemotron Les modèles de NVIDIA en sont un bon exemple. Les modèles s’appuient sur les modèles ouverts existants, l’élagage des paramètres inutiles et la distillation de nouvelles capacités.
Cela signifie qu’un modèle de némotron plus petit peut souvent surpasser son plus grand prédécesseur à travers plusieurs dimensions: inférence plus rapide, utilisation de la mémoire plus faible et raisonnement plus fort.
Nous voulions quantifier ces compromis – en particulier contre certains des modèles les plus importants de la génération actuelle.
Combien plus précis? Combien plus efficace? Donc, nous les avons chargés sur notre cluster et nous nous sommes mis au travail.
Comment nous avons évalué la précision et le coût
Étape 1: Identifiez le problème
Avec les modèles en main, nous avions besoin d’un défi réel. Celui qui teste le raisonnement, la compréhension et les performances dans un flux d’IA agentique.
Imaginez un analyste financier junior essayant de se relever dans une entreprise. Ils devraient être en mesure de répondre à des questions telles que: « Boeing a-t-il un profil de marge brute améliorant au cours de l’exercice 2010? »
Mais ils doivent également expliquer la pertinence de cette métrique: «Si la marge brute n’est pas une métrique utile, expliquez pourquoi.»
Pour tester nos modèles, nous lui attribuerons la tâche de synthétiser les données livrées via un flux d’IA agentique, puis de mesurer leur capacité à fournir efficacement une réponse précise.
Pour répondre correctement aux deux types de questions, les modèles doivent:
- Tirez les données de plusieurs documents financiers (tels que les rapports annuels et trimestriels)
- Comparez et interprétez les chiffres sur les périodes
- Synthétiser une explication fondée dans le contexte
FinanceBench Benchmark est conçu pour exactement ce type de tâche. Il associe des dépôts avec des questions et réponses validées par des experts, ce qui en fait un proxy solide pour de vrais workflows d’entreprise. C’est le banc d’essai que nous avons utilisé.
Étape 2: Modèles vers les workflows
Pour tester dans un contexte comme celui-ci, vous devez construire et comprendre le flux de travail complet – pas seulement l’invite – afin que vous puissiez alimenter le bon contexte dans le modèle.
Et tu dois faire ça à chaque fois Vous évaluez une nouvelle paire modèle-Workflow.
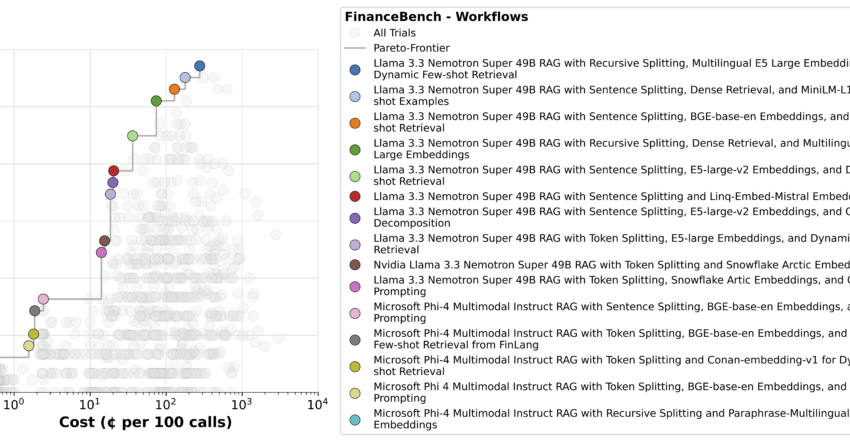
Avec syftrnous sommes en mesure de gérer des centaines de workflows sur différents modèles, faisant rapidement des compromis. Le résultat est un ensemble de flux paréto-optimaux comme celui ci-dessous.
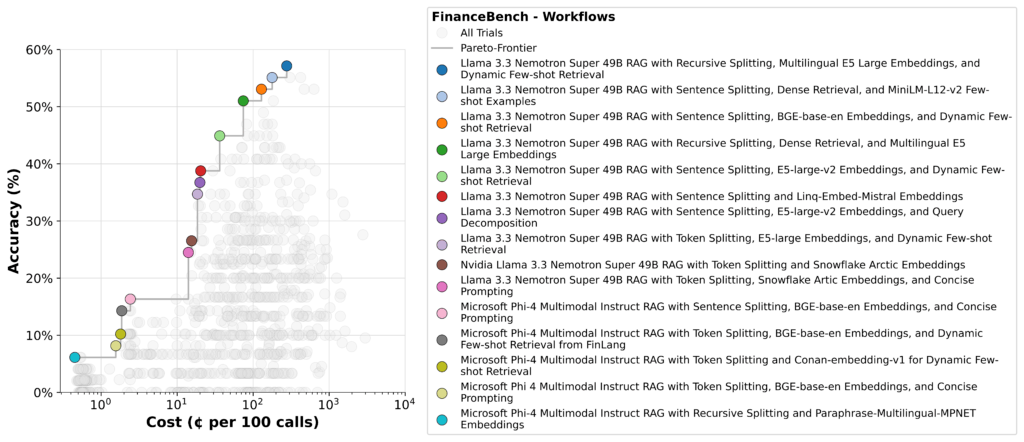
En bas à gauche, vous verrez des pipelines simples en utilisant un autre modèle comme synthétisant LLM. Ceux-ci sont peu coûteux à gérer, mais leur précision est mauvaise.
En haut à droite sont les plus précis – mais plus chers, car ceux-ci reposent généralement sur des stratégies d’agence qui décomposent la question, font plusieurs appels LLM et analysent chaque morceau indépendamment. C’est pourquoi le raisonnement nécessite un calcul et des optimisations efficaces pour maintenir les coûts d’inférence en échec.
Nemotron se présente fortement ici, tenant le coup à travers la frontière de Pareto restante.
Étape 3: plongée profonde
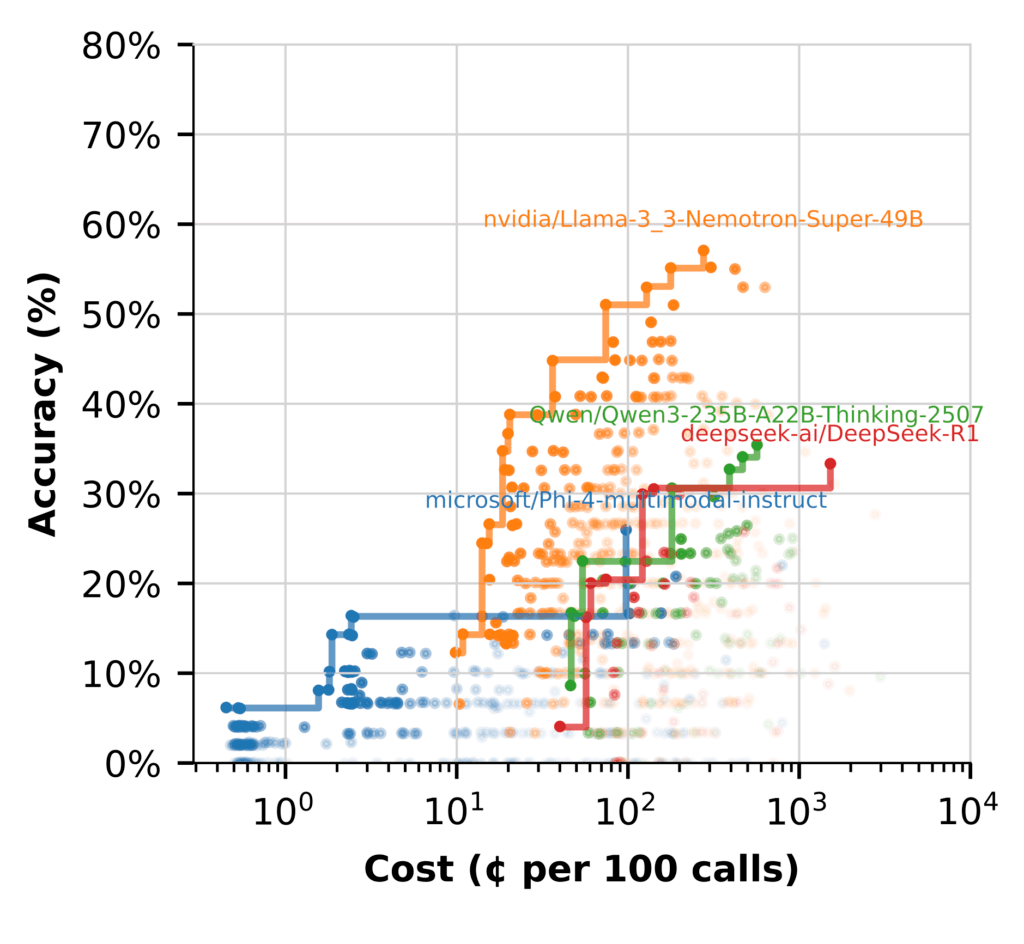
Pour mieux comprendre les performances du modèle, nous avons regroupé les workflows par le LLM utilisé à chaque étape et tracé la frontière de Pareto pour chacune.
L’écart de performance est clair. La plupart des modèles ont du mal à se rapprocher des performances de Nemotron. Certains ont du mal à générer des réponses raisonnables sans ingénierie contextuelle lourde. Même alors, il reste moins précis et plus cher que les modèles plus grands.
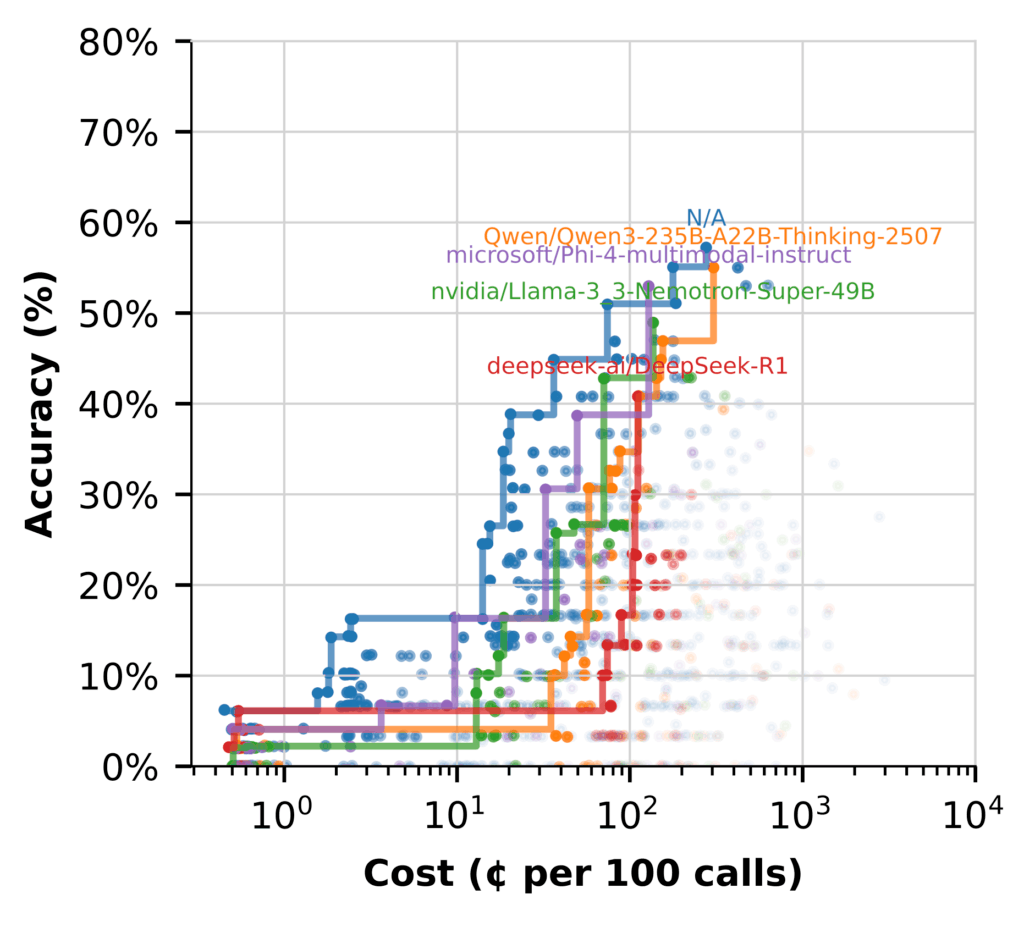
Mais lorsque nous passons à l’utilisation du LLM pour (hypothétique des intégres de documents) Hyde, l’histoire change. (Les flux marqués N / A n’incluent pas Hyde.)
Ici, plusieurs modèles fonctionnent bien, avec l’abordabilité tout en offrant des flux de haute précision.
Les principaux plats à retenir:
- Nemotron brille en synthèse, produisant des réponses à haute fidélité sans coût supplémentaire
- L’utilisation d’autres modèles qui excellent chez Hyde libère du Nemotron pour se concentrer sur le raisonnement à grande valeur
- Les flux hybrides sont la configuration la plus efficace, en utilisant chaque modèle où il fonctionne le mieux
Optimisation de la valeur, pas seulement de la taille
Lors de l’évaluation de nouveaux modèles, le succès n’est pas seulement une question de précision. Il s’agit de trouver le bon équilibre de qualité, de coût et d’adaptation à votre flux de travail. La mesure de la latence, de l’efficacité et de l’impact global permet de vous assurer que vous obtenez une valeur réelle
Les modèles Nvidia Nemotron sont construits dans cet esprit. Ils sont conçus non seulement pour l’électricité, mais pour des performances pratiques qui aident les équipes à générer un impact sans coûts en fuite.
Associez cela à un processus d’évaluation structuré et guidé par Syftr, et vous avez un moyen reproductible de rester en avance sur le désabonnement du modèle tout en gardant le calcul et le budget en échec.
Pour explorer davantage SYFTR, consultez le Github dépôt.
Source link



