
Pourquoi vous avez besoin de chiffon pour rester pertinent en tant que scientifique des données
- Intelligence Artificielle
 Noesis News
Noesis News- 0
- 12 minutes de lecture

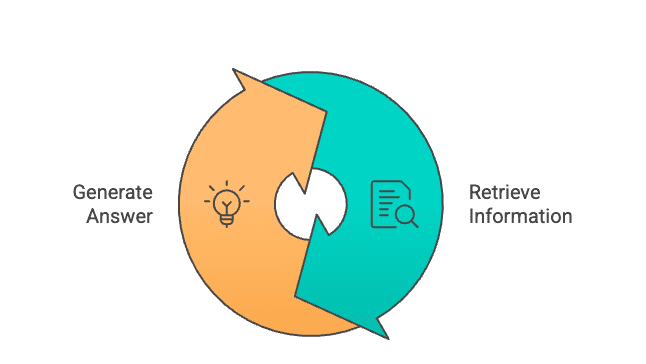
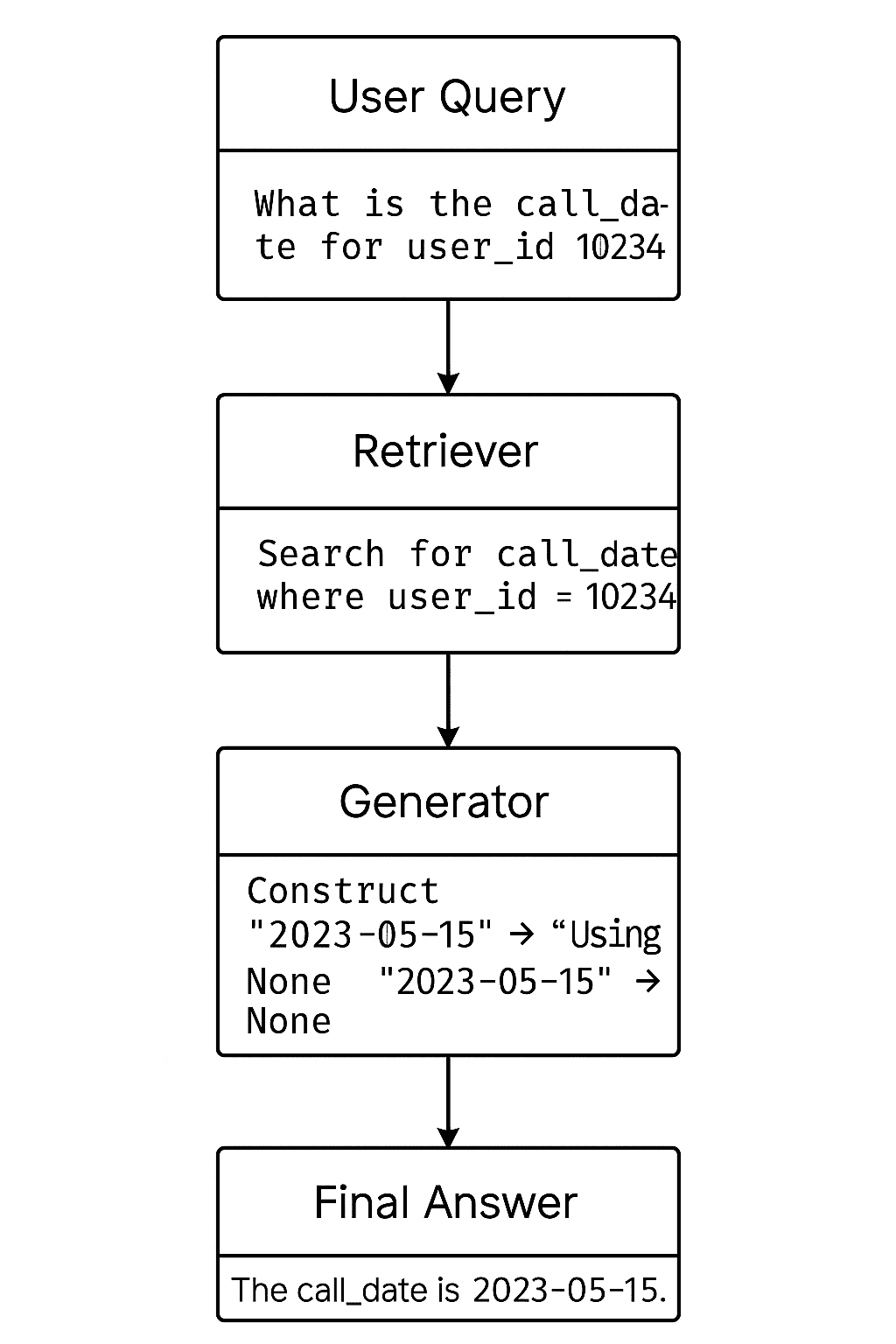
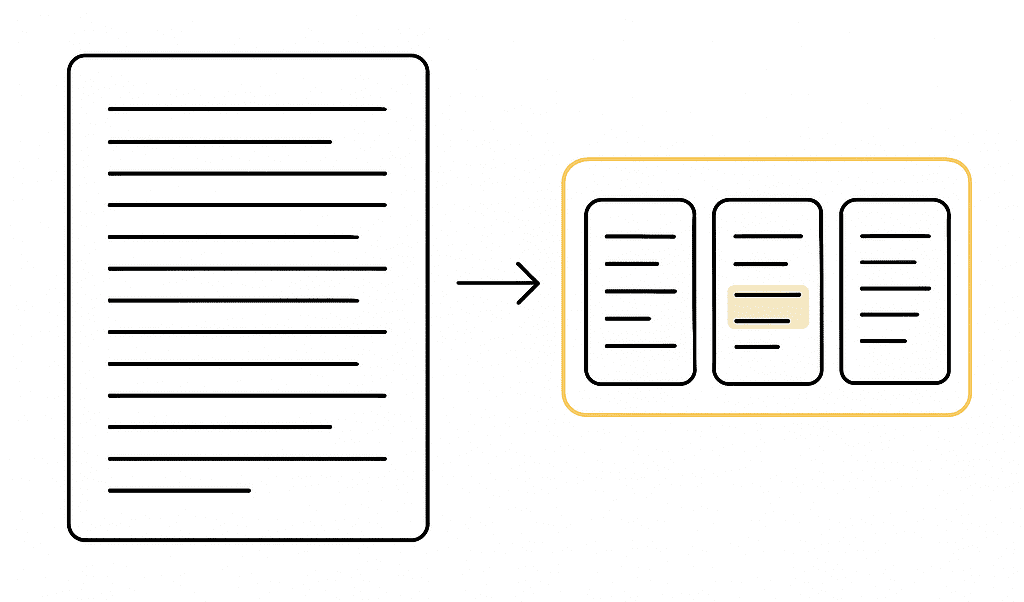

Image de l’auteur | Toile
Si vous travaillez dans un domaine lié aux données, vous devez vous mettre à jour régulièrement. Les scientifiques des données utilisent différents outils pour des tâches telles que la visualisation des données, la modélisation des données et même les systèmes d’entrepôt.
Comme cela, l’IA a changé la science des données de A à Z. Si vous êtes sur le point de rechercher des emplois liés à la science des données, vous avez probablement entendu le terme chiffon.
Dans cet article, nous décomposons le chiffon. En commençant par l’article académique qui l’a introduit et comment il est maintenant utilisé pour réduire les coûts lorsque vous travaillez avec des modèles de langue importants (LLM). Mais d’abord, couvrons les bases.
Qu’est-ce que la génération (RAG) (RAG) de la récupération?
Patrick Lewis a introduit le chiffon pour la première fois ce Article académique en premier en 2020. Il combine deux éléments clés: un retriever et un générateur.
L’idée derrière cela est simple. Au lieu de générer des réponses à partir de paramètres, le chiffon peut collecter des informations pertinentes à partir du document.
Qu’est-ce qu’un retriever?
Un retriever est utilisé pour collecter les informations pertinentes du document. Mais comment?
Considérons ceci. Vous avez une feuille Excel massive. Disons que c’est 20 Mo, avec des milliers de lignes. Vous souhaitez rechercher Call_Date pour user_id = 10234.
Grâce à ce retriever, au lieu de regarder l’ensemble du document, RAG ne fera que rechercher la partie pertinente.
Mais comment est-ce utile pour nous? Si vous recherchez l’intégralité du document, vous dépenserez beaucoup de jetons. Comme vous le savez probablement, l’utilisation de l’API de LLM est calculée à l’aide de jetons.
Voyons https://platform.openai.com/tokenizer et voir comment ce calcul est effectué. Par exemple, si vous collez l’introduction de cet article. Il en coûte 123 jetons.
Vous devez vérifier cela pour calculer le coût à l’aide de l’API de LLM. Par exemple, si vous envisagez d’utiliser un document Word, disons 10 Mo, il pourrait s’agir de milliers de jetons. Chaque fois que vous téléchargez ce document à l’aide de l’API de LLM, les coûts se multiplient.
En utilisant RAG, vous ne pouvez sélectionner que la partie pertinente du document, en réduisant le nombre de jetons afin que vous payiez moins. C’est simple.
Comment ce retriever fait-il cela?
Avant le début de la récupération, les documents sont divisés en petits morceaux, paragraphes. Chaque morceau est converti en un vecteur dense en utilisant un modèle d’incorporation (Openai Embeddings, phrase-bert, etc.).
Ainsi, lorsqu’un utilisateur souhaite une opération comme demander quelle est la date d’appel, le Retriever compare le vecteur de requête à tous les vecteurs de morceaux et sélectionne les plus similaires. C’est génial, non?
Qu’est-ce qu’un générateur?
Comme nous l’avons expliqué ci-dessus, après que le Retriever ait trouvé les documents les plus pertinents, le générateur prend le relais. Il génère une réponse en utilisant la requête de l’utilisateur et un document récupéré.
En utilisant cette méthode, vous minimisez également le risque d’hallucination. Parce qu’au lieu de générer une réponse librement à partir des données sur lesquelles l’IA a été formée, le modèle fonde sa réponse sur un document réel que vous avez fourni.
L’évolution de la fenêtre de contexte
Les modèles initiaux, comme GPT-2, ont de petites fenêtres de contexte, vers 2048 jetons. C’est pourquoi ces modèles n’ont pas de fonctionnalités de téléchargement de fichiers. Si vous vous souvenez, après quelques modèles, Chatgpt propose une fonction de téléchargement de données car la fenêtre de contexte a évolué vers cela.
Des modèles avancés comme GPT-4O ont une limite de jetons de 128K, qui prend en charge la fonction de téléchargement de données et pourrait montrer le chiffon redondant, dans le cas de la fenêtre de contexte. Mais c’est là que les demandes de réduction des coûts entrent en place.
Alors maintenant, l’une des raisons pour lesquelles les utilisateurs utilisent le chiffon est de réduire les coûts, mais pas seulement cela. Étant donné que les coûts d’utilisation de LLM diminuent, GPT 4.1 a introduit une fenêtre de contexte jusqu’à 1 million de jetons, une augmentation fantastique. Maintenant, Rag a également évolué.
Pratique liée à l’industrie
Maintenant, les LLM évoluent en agents. Ils devraient automatiser vos tâches au lieu de générer des réponses. Certaines entreprises développent des modèles qui contrôlent même vos mots clés et votre souris.
Donc, pour ces cas, vous ne devriez pas prendre de chance d’hallucination. Alors ici, Rag entre dans la scène. Dans cette section, nous analyserons profondément un exemple du monde réel.
Les entreprises recherchent des talents pour développer des agents pour eux. Ce ne sont pas seulement les grandes entreprises; Même la taille moyenne ou les petites entreprises et les startups recherchent leurs options. Vous pouvez trouver ces emplois sur des sites Web Freelancer comme Lavage et Fiverr.
Agent marketing
Disons qu’une entreprise de taille moyenne d’Europe souhaite que vous créiez un agent, un agent qui génère des propositions de marketing pour leurs clients en utilisant des documents de l’entreprise.
En plus de cela, cet agent doit utiliser le contenu en incluant des informations hôtelières pertinentes dans cette proposition d’événements commerciaux ou de campagnes.
Mais il y a un problème: l’agent hallucine fréquemment. Pourquoi cela se produit-il? Parce qu’au lieu de s’appuyer uniquement sur le document de l’entreprise, le modèle tire les informations de ses données de formation d’origine. Ces données de formation peuvent être obsolètes, car comme vous le savez, ces LLM ne sont pas mises à jour régulièrement.
Ainsi, en conséquence, l’IA finit par ajouter des noms d’hôtel incorrects ou simplement des informations non pertinentes. Vous identifiez maintenant la cause profonde du problème: le manque d’informations fiables.
C’est là que RAG entre en jeu. À l’aide d’une API de navigation Web, les entreprises ont utilisé des LLM pour récupérer des informations fiables à partir du Web et la référence, tout en générant des réponses sur comment. Voyons cette invite.
« Générez une proposition, basée sur le ton des informations vocales et de l’entreprise, et utilisez la recherche Web pour trouver les noms d’hôtel. »
Cette fonction de recherche sur le Web devient une méthode de chiffon.
Réflexions finales
Dans cet article, nous avons découvert l’évolution des modèles d’IA et pourquoi Rag les a utilisés. Comme vous pouvez le voir, la raison a changé au fil du temps, mais le problème demeure: l’efficacité.
Même si la raison est le coût ou la vitesse, cette méthode continuera d’être utilisée dans les tâches liées à l’IA. Et par «lié à l’IA», je n’exclue pas la science des données, car, comme vous le savez probablement, avec le prochain été de l’IA, la science des données a déjà été profondément affectée par l’IA.
Si vous souhaitez suivre des articles similaires, résolvez plus de 700 questions d’entrevue liées à la science des données et plus de 50 projets de données, visitez mon plate-forme.
Nate Rosidi est un scientifique des données et en stratégie de produit. Il est également professeur auxiliaire qui enseigne l’analyse et est le fondateur de Stratascratch, une plate-forme aidant les scientifiques des données à se préparer à leurs entretiens avec de véritables questions d’entrevue de grandes entreprises. Nate écrit sur les dernières tendances du marché de la carrière, donne des conseils d’entrevue, partage des projets de science des données et couvre tout SQL.
Source link



