
POURQUOI: un cadre rapide simple pour un impact élevé et des résultats cohérents de LLMS
- Intelligence Artificielle
 Noesis News
Noesis News- 0
- 17 minutes de lecture
Auteur (s): Kaushik Holla
Publié à l’origine sur Vers l’IA.
Ça fait peu plus de deux ans maintenant que j’ai commencé à m’intégrer LLMS dans les applications commerciales pour atteindre les produits KPI et les objectifs – et ce fut une course sauvage. Au cours de ces années, j’ai été dans des situations où j’ai essayé presque toutes les techniques d’incitation comme zéro-shot, quelques coups de rôle, basés sur les rôles, étape par étape, etc. J’ai continué à expérimenter, je me suis toujours retrouvé régulièrement frustré par ce que j’ai récupéré. Parfois, la sortie était proche, mais pas très utile. D’autres fois, il a complètement raté le point.
Après avoir frappé les murs encore et encore, il a finalement cliqué: l’invitation ne consiste pas seulement à «parler à l’IA» mieux – c’est une compétence. Donner la bonne invite est la différence entre les conjectures et un flux de travail fiable. Cela peut être confirmé avec la montée en puissance des entreprises qui ont construit des produits entiers autour d’invites efficaces et bien conçues. Dans de nombreux cas, ils sont essentiellement des emballages LLMS Cela fonctionne si bien parce que les invites dans les coulisses sont nettes, structurées et reproductibles.
Pourquoi avons-nous besoin de ce cadre?
Maintenant que les LLM sont devenus une partie de notre flux de travail quotidien, que ce soit via le chatppt, le curseur, la perplexité ou une douzaine d’autres outils – nous ne pouvons pas nous permettre de compter sur des invites génériques et hit-ou-miss. J’ai passé des mois à itération, tester et affiner ma propre approche, et parmi tous ces essais et erreurs, j’ai trouvé quelque chose que j’appelle maintenant le Framework Why-US. Ce n’est pas parfait, mais ça me donne toujours meilleurs résultats par rapport à simplement l’ailer.
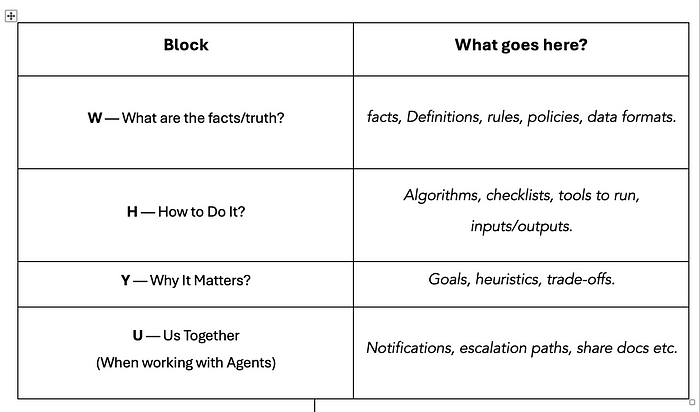
Le Framework W-H-Y-US est une structure reproductible, seulement quatre blocs – pour transformer toute demande floue en un livre de jeu clair et réutilisable qu’une IA peut suivre à chaque fois.
Plâtre dans chaque bloc du cadre et comprendre comment en tirer parti. Je vais parler de chaque bloc et comment l’appliquer à l’aide de la revue des produits Amazon Ensemble de données comme exemple.
Avis sur les produits Amazon Ensemble de données de Kaggle, qui contient 500 000 avis clients à travers une large gamme de produits. Chaque entrée comprend des champs clés comme product_id, review_text, ratinget timestampoffrant une riche source pour analyse des sentimentsDétection des tendances et informations sur la rétroaction des produits.
Le cadre:
W – Quels sont les faits / vérité?
Question directrice: Ce blocage définit les bases, c’est-à-dire«Quels faits ou contraintes ne changent jamais?» Il établit les vérités immuables sur la tâche.
Pour notre ensemble de données:
Structure de l’ensemble de données: Chaque entrée comprend
product_id,review_text,ratingettimestamp.Échelle de notation: Les notes varient de 1 à 5 étoiles.
Langue: Toutes les critiques sont en anglais.
Mappage des sentiments: À des fins d’analyse, les notes sont classées comme:
1. Positif: 4 à 5 étoiles
2. Neutre: 3 étoiles
3. Négatif: 1 à 2 étoiles
Ces constantes définissent les bases de toute analyse ou modélisation. Ce ne sont pas des négociables – le genre de choses que l’IA doit savoir et respecter si cela va faire le emploi droite.
H – comment le faire
Question directrice: «Quelle est la séquence exacte des étapes?» c’est-à-dire que nous définissons la procédure étape par étape.
Nettoyage des données:
Retirez les entrées NULL ou DUPLIQUES.
Normalisez le texte en convertissant en minuscules et en supprimant les caractères spéciaux.
Analyse des sentiments: Appliquer un modèle d’analyse des sentiments pré-formés pour classer
review_texten catégories positives, neutres ou négatives.Agrégation:
Avis de groupe par
product_id.Calculez: note moyenne par produit et comptage des examens par catégorie de sentiment.
Visualisation:
Générez des graphiques à barres montrant la distribution des sentiments par produit.
Créez des nuages de mots pour les termes les plus fréquents dans des critiques positives et négatives.
Rapports: Compiler les résultats dans un rapport de démarque pour les parties prenantes.
Cette approche structurée assure la cohérence et la reproductibilité.
Y – pourquoi c’est important
Question directrice: «Quels critères de réussite, objectifs ou états d’esprit guident les choix?» Fondamentalement, comprendre le but derrière la tâche:
Objectif commercial: Identifiez les tendances de la satisfaction des clients pour éclairer l’amélioration des produits et les stratégies de marketing.
Métriques de qualité:
Précision de la classification des sentiments.
Clarité et lisibilité des visualisations.
Besoins des parties prenantes: Les informations doivent être exploitables et facilement interprétables par les membres de l’équipe non technique.
Garder ces objectifs à l’esprit garantit que l’analyse offre de la valeur.
U – nous ensemble (lorsque vous travaillez avec des agents)
Question directrice: «Comment les agents transmettent-ils ou collaborent-ils?» c’est-à-dire Définir les rôles et les points de collaboration:
#DataEngineer: Prépare et nettoie l’ensemble de données.
#Dataanalyst: Effectue une analyse des sentiments et génère des visualisations.
#MarketingTeam: Examine le rapport pour dériver des informations exploitables.
Outils de collaboration:
Utilisez Slack pour la communication.
Stocker les rapports dans un dossier Google Drive partagé.
Planifiez les réunions bihebdomadaires pour discuter des résultats.
La délimitation claire des responsabilités facilite une collaboration fluide.
Les assembler tous:
Un exemple d’invite en utilisant Whyu
I'm analyzing the (Amazon Product Reviews Dataset)(https://www.kaggle.com/datasets/arhamrumi/amazon-product-reviews) to extract customer sentiment insights.**W — What’s True:**
- Dataset includes `product_id`, `review_text`, `rating`, and `timestamp`.
- Ratings range from 1 to 5 stars.
- Reviews are in English.
**H — How to Do It:**
- Clean the data by removing nulls and duplicates.
- Normalize `review_text`.
- Classify sentiments using a pre-trained model.
- Aggregate data by `product_id` to compute average ratings and sentiment counts.
- Visualize results with bar charts and word clouds.
- Compile findings into a Markdown report.
**Y — Why It Matters:**
- Aim to uncover customer satisfaction trends.
- Provide actionable insights for product and marketing teams.
- Ensure clarity and accuracy in reporting.
**U — Us Together:**
- #DataEngineer handles data preparation.
- #DataAnalyst conducts analysis and visualization.
- #MarketingTeam reviews and acts on insights.
- Utilize Slack and Google Drive for collaboration.
Remarque: si plusieurs rôles sont impliqués, ajoutez un hashtag rapide – #DataEngineer, #DataAnalyst, #MarketingTeam– devant une balle. Si vous êtes en solo, sautez les étiquettes.
N’oubliez pas lors du remplissage du cadre,
- Bullets de duper cérébral Sous chaque rubrique, ne vous inquiétez pas du libellé parfait.
- Gardez uniquement des points qui doit être vrai pour des résultats cohérents.
- Lisez les quatre blocs de haut en bas; Un étranger doit comprendre la tâche.
- Collez comme première invite (ou invite «système») dans Chatgpt, Cursor, Langchain, etc.
- Si le modèle glisse, resserrez la balle qui était vague.
Cette invite structurée offre des sorties cohérentes et précieuses que les invites.
Pièges communs:
Même avec un cadre simple comme W-H-Y-Y-US, il est facile de trébucher. J’ai moi-même commis toutes ces erreurs – voici donc les plus courantes et comment les éviter:
Tout en fourrer dans «quoi»
Il est tentant de saisir toutes vos instructions et votre contexte dans le bloc «What’s True». Mais s’il s’agit d’étapes ou d’actions, il appartient à « Comment. » Si cela implique une collaboration ou qui fait quoi, déplacez-le vers « Nous. »
Être vague dans «pourquoi»
Un générique «ceci est important» n’aidera pas les décisions. Au lieu de cela, ajoutez des critères de réussite clairs comme:
- « Le temps de réponse devrait être inférieur à 3 secondes. »
- « Le résumé doit marquer au moins 80% sur les contrôles de précision. »
- « L’objectif est de 99% de disponibilité sur tous les modules. »
Tive de rôles sur-utilisation
Utilisez uniquement des balises comme #Reviewer ou #Engineer Quand une balle vraiment changements basés sur qui le fait. Sinon, sautez les étiquettes – ils ajoutent plus que la clarté.
Final à emporter
Le Framework W-H-Y-US vous aide à briser toute tâche, grande ou petite en quatre blocs de construction clairs et reproductibles:
Qu’est-ce qui est vrai.
Comment le faire.
Pourquoi c’est important.
Nous ensemble.
Que vous le délégiez à une IA ou que vous collaboriez avec un coéquipier, ce cadre vous donne un moyen structuré et réutilisable de transformer les demandes floues en manuels clairs et fiables. Écrivez une fois, réutilisez pour toujours – et arrêtez de compter sur la «magie» rapide.
Links:
Avis sur les produits Amazon
568k + avis sur les consommateurs sur différents produits Amazon
www.kaggle.com
Publié via Vers l’IA
Source link



