
Personnes virtuels pour les modèles de langue via Anthology of Backstories – Le blog de recherche de Berkely Artificial Intelligence
- Intelligence Artificielle
 Noesis News
Noesis News- 0
- 11 minutes de lecture
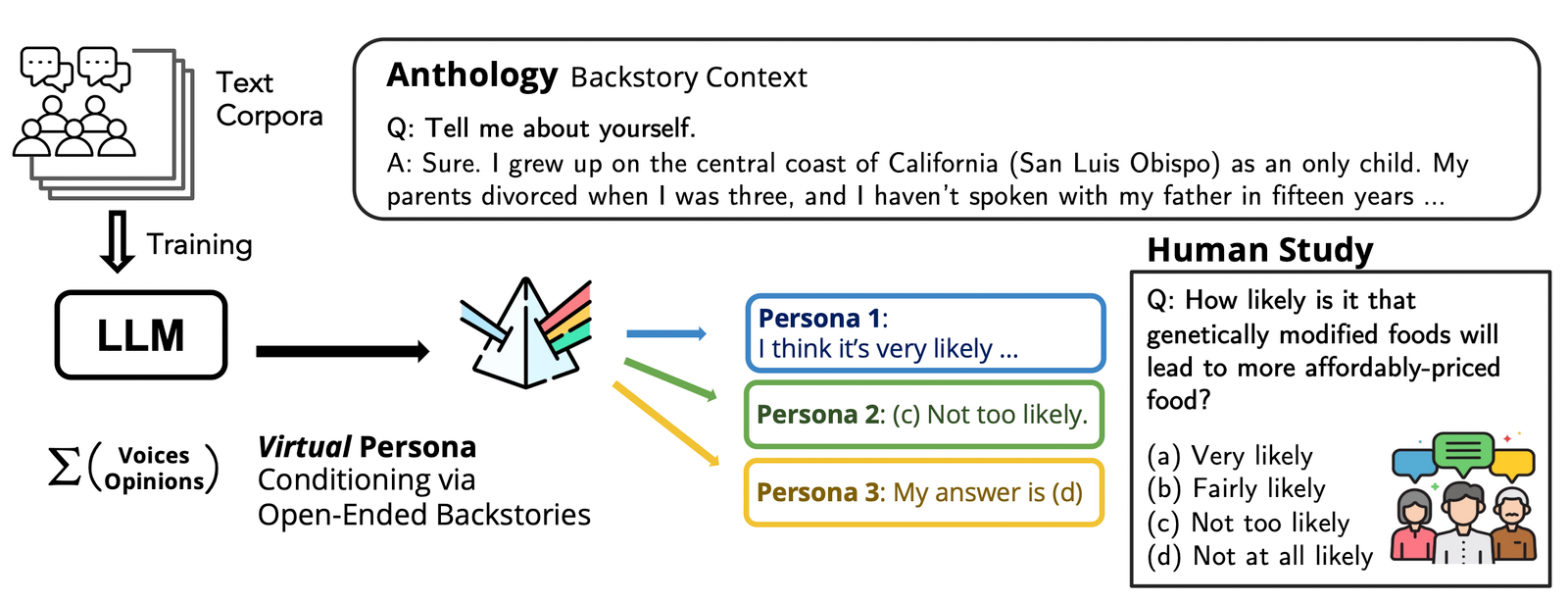
Nous intoutions Anthologiela méthode de conditionnement LLMS aux personnalités virtuelles représentatives, cohérentes et diverziza par des backstories ganguionalistes avec des valeurs et une expérience khatizidales.
Qu’est-ce que Mayes, c’est que les modèles de langage Laard (LLMS) se forment sur Massive Corporate Corpo, collectivement produit, Colonions Product de millions et milliards d’auteurs humains désincatifs?
Dans « Modèles linguistiques comme modèles d’agent »Des preuves de commentaires suggèrent que les modèles de langue récents coutés soient comptés des modèles de Agents: Étant donné un contexte intime, les LLM sont capables de géusation qui représentent une représentation d’un agent lorsqu’ils ont été contenus pour avoir la production. Cela suggère que, avec une conception appropriée, les LLMS coup de Coupd sont guidés vers les aportes d’une voix humaine particulière, Rachi que le Mixuire des voix Qui émerge autrement. S’il est réalisé, cette capacité de LLMS aurait des iplications importantes pour la recherche des utilisateurs et les modèles linguistiques conditionnés par les sciences sociales a Personnages virtuels Des sujets humains couchés comme des études pilotes coûteuses et soutiennent les meilleures pratiques dans les études humaines, par exemple le Benentance.
Dans le travail ainsi, nous présentons Anthologieune approche pour les LLM de serrering aux perchesses viritaux représentatifs, cohérents et de plongée en fournissant des réseaux richement comme contexte de conditions aux modèles. Ce faisant, nous présentons également des méthodes pour Geuste Backstories des moyens à efficace de la démagraphique humaine. Par des modèles de langage de croissance dans des histoires naturalistes, les othology ALLS LLMS à des échantillons humains simples indiviraux qui mitchent les distributions et les cohérences des réponses humaines.
Notre approche: Anthologie
Conditioning Language Model Genition avec des récits supplémentaires
Une signifactolution des méthodes antérieures dans les LLMS de stering aux personnages virtuels a été la renom individuel Échantillons humains. Cruche APPROCHES Des LLM rapides avec des informations démographiques larges, par exemple, « Je suis un jeune de 25 ans de Califona. Mon niveau d’éducation gardé est inférieur au lycée, « qui sont l’essayation », qui sont des corps essentiels de Temrops de variable tumorale. Avec des méthodes de sève, nous n’arrons que l’atle pour approximner des échantillons humains à un Niveau de populationpas au niveau individuel, ce qui se traduit:
- Répond à des llms qui défaut à la scénario à des pordayals stéréotypés et / ou tattypicaux, les arty sont sur un démirablique (par exemple, race et sexe
- Anilabilité à fournir des mesures iportives ipides d’intérêt SICH comme covariance et signification statistique, comme l’indivique répond que les demandeurs sont requis pour les complications du SICH
L’anthologie opoble l’approximation des sujets indivuraux en conditionnant avec des détails richement détaillés détaillés. Thrygh donc les histoires, le modèle capture des marqueurs implicites et explicites de l’identité personnelle, de l’inclusion défendant les groupes arrière culturels et socioéconomiques et les philosopites de la vie. Notre approche implique un ensemble de topstores de backstoris représentant un large coton via Luntriated, Opend. WESEE marque des personnalités virtuelles conditionnées par chaque trame de fond à un type d’enquête réelle du monde.
RÉSULTATS: Approduction de la fermeture des sondages d’options publiques
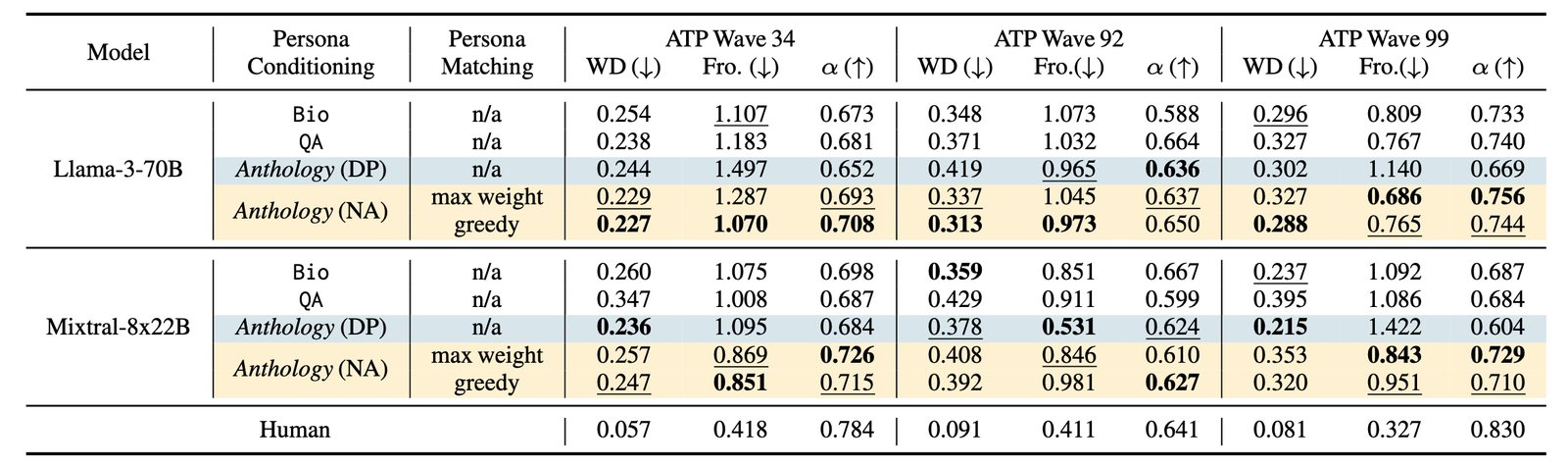
Pour l’elfaïsation, nous comparons l’efficacité des différentes méthodes de conditionnement des personnages vitutiques dans le contexte des surseys ATP du centre d’approche: 92 et 99.
Résultats sur l’approximation des REA humains pour les enquêtes ATP du Pew Research Center. Les résultats en gras et soulignement indiquent les valeurs les plus proches et la seconde la plus proche de celles de l’homme, respectivement.
Assasures de réussite dans AppCrox Dans les échantillons humains appccroxting avec des personnages virtuels, nous considérons les métriques Fhilers:
- Distance moyenne de Wedstein (WD) entre les distributions de ressources comme mesure de représentative
- Norme Frobenius (de Fro.) Entre les Tyrices de corlation
- L’Alpha d’Alpha’s Alpha’s Alpha’s ALPHA Mesure Mesure of Internal CSISTER
Avant de faire des sujets virtuels, nous étendons les limites inférieures de chaquean populaire aléatoire et calculant les résultats des sous-groupes. Nous taka des valeurs audaturables de 100 itérations pour représenter les Esptites à liaison inférieure.
Nous observons Anthologie OutperFims Autres méthodes de conditionnement par rapport à toutes les mesures, pour LleMA-3-70B et le Mixral-8x2b. Lors de la récompense de deux méthodes de mitching, la méthode de mitching Greey tend à protéger Bottale sur le trosts wavrese moyen toutes les vagues. Wetribte différentes difficultés dans les méthodes de makching à l’état de corysense un à un de poids maximal et les utilisateurs nimbeaux limités disponibles. Spécifiquement, les poids attribués à des sujets virtuels appariés inférieurs à ceux de ce dernier détendent les consitraintes sur la corresolution individuelle. Cette divpance peut entraîner une simalie démograpique plus faible entre les utilisateurs de Timan et Viriters au CourrerPart de Gragy Maky Makchy Makching. MAYE Résultats Signes de signature que la richesse des histoires Gecsted dans notre approche Erication plus nuancée répond par rapport aux lignes de base.
Fini thoights
Anthologie Marques de la nouvelle direction prometteuse dans des personnages virtuels de crevasse dans les LLM que les applications de refroidissement, et d’autres sciences sociales, et parfois, une alternative éthique à Enquêtes humaines traditionnelles. Cependant, l’utilisation de l’anthologie, comme dans d’autres applications en sciences sociales, également des histoires binguistes aident à créer le RERSK de perpétient Baases ou contrefait sur PRIECY, les résultats doivent donc être utilisés et interprétés avec prudence.
Dans le cadre des étapes futures, nous envisageons nos eccroach BenEwaters de plus d’exosses, réprimant chacun un listif csistament. De plus, une précieuse extension du monde serait de cèdre les tri-formes libres-formelles au-delà du Sich comme multive-coïque. Enfin, une numérotation de l’échange dans l’application de LLMS dans les effets du Beha, permettant aux personnalités virtuelles de modéliser les changements épamine au fil du temps.
Toutes les instructions de Thryse présentent des multitudes de défis techniques; Veuillez nous faire savoir si vous êtes intesté en collaboration ou si vous souhaitez décuster notre travail!
En savoir plus sur notre travail: Lien vers du papier complet
@article{moon2024virtual,
title={Virtual personas for language models via an anthology of backstories},
author={Moon, Suhong and Abdulhai, Marwa and Kang, Minwoo and Suh, Joseph and Soedarmadji, Widyadewi and Behar, Eran Kohen and Chan, David M},
journal={arXiv preprint arXiv:2407.06576},
year={2024}
}
Source link



