
(P) Nous avons construit ce projet pour augmenter le débit LLM par 3x. Maintenant, il a été adopté par IBM dans leur pile de service LLM!
- Intelligence Artificielle
 Noesis News
Noesis News- 0
- 3 minutes de lecture
|
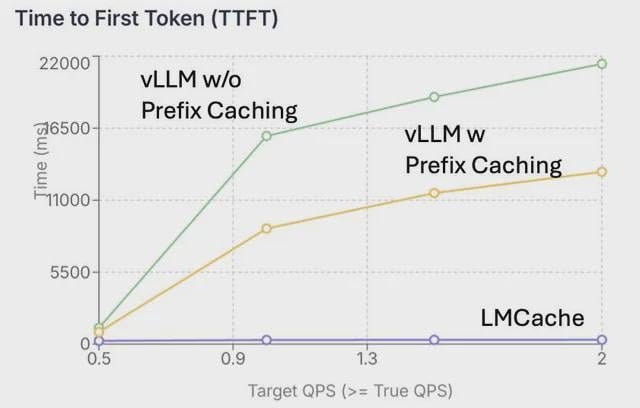
Salut les gars, notre équipe a construit ce projet open source, LMCACH, pour réduire le calcul répétitif dans l’inférence LLM et faire des systèmes servir plus de personnes (3x plus de débit dans les applications de chat) et il a été utilisé dans la pile d’idées Open Source LLM d’Open source d’IBM. Dans LLM Serving, l’entrée est calculée dans des états intermédiaires appelés KV Cache pour fournir davantage des réponses. Ces données sont relativement importantes (~ 1 à 2 Go pour un contexte long) et sont souvent expulsées lorsque la mémoire GPU ne suffit pas. Dans ces cas, lorsque les utilisateurs posent une question de suivi, le logiciel doit recomputer le même cache KV. LMCACH est conçu pour lutter contre cela en déchargeant et en chargeant efficacement ces caches KV vers et depuis DRAM et DISK. Cela est particulièrement utile dans les paramètres d’AQ à plusieurs tourments lorsque la réutilisation du contexte est importante, mais la mémoire GPU ne suffit pas. Demandez-nous n’importe quoi! soumis par / U / Nice-Fachfortable-650 |




{kind=link}