
Nuage de pain mixte: une API unifiée pour les pipelines de chiffon
- Intelligence Artificielle
 Noesis News
Noesis News- 0
- 19 minutes de lecture

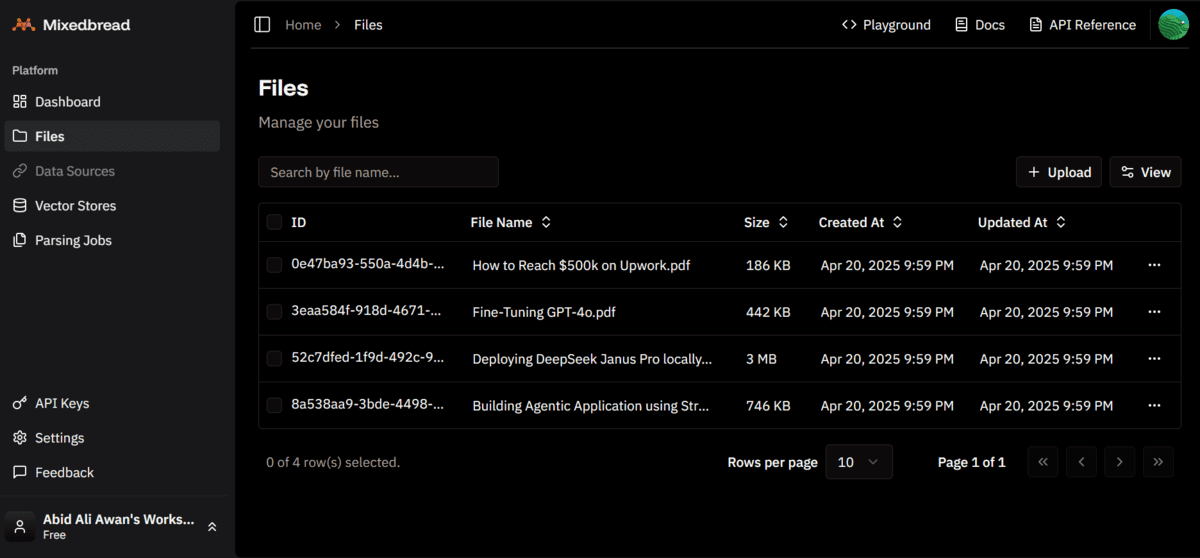
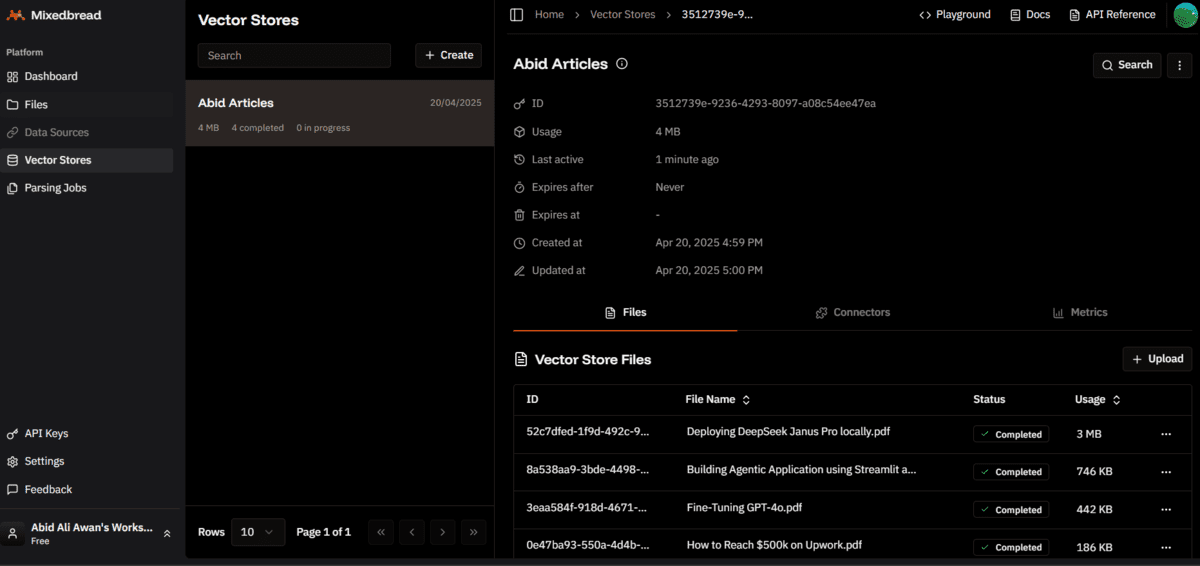

Image de l’éditeur (Kanwal Mehreen) | Toile
Lors d’une conférence avec certains ingénieurs d’apprentissage automatique, j’ai demandé pourquoi nous devons combiner Langchain avec plusieurs API et services pour créer un pipeline de génération augmentée (RAG) de récupération. Pourquoi ne pouvons-nous pas avoir une API qui gère tout – comme le chargement de documents, l’analyse, l’intégration, les modèles de rediffusion et le stockage vectoriel – le tout en un seul endroit?
Il s’avère qu’il existe une solution appelée mixte. Cette plate-forme est rapide, conviviale et fournit des outils pour la construction et le service de pipelines de récupération. Dans ce didacticiel, nous explorerons le cloud à pain mixte et apprendreons à construire un pipeline de chiffons entièrement fonctionnel à l’aide de l’API de MixedBread et du dernier modèle d’Openai.
Présentation du nuage de pain mixte
Le cloud de pain mixte est en une seule solution pour construire une application d’IA appropriée avec des capacités de compréhension de texte avancées. Conçu pour simplifier le processus de développement, il fournit une suite complète d’outils pour gérer tout, de la gestion des documents à la recherche et à la récupération intelligentes.
Le nuage de pain mixte fournit:
- Téléchargement de documents: Téléchargez tout type de documents à l’aide de l’interface ou de l’API conviviale
- Traitement des documents: Extraire des informations structurées à partir de divers formats de documents, transformant des données non structurées en texte
- Magasins vectoriels: Stocker et récupérer des intégres avec des collections consultables de fichiers
- Texte des intérêts: Convertir le texte en représentations vectorielles de haute qualité qui capturent le sens sémantique
- RERANKING: Améliorez la qualité de la recherche en réorganisant les résultats en fonction de leur pertinence pour la requête originale
Construire l’application de chiffon avec mixte et openai
Dans ce projet, nous apprendrons à créer une application de chiffon à l’aide de mixtes et de l’API OpenAI. Ce guide étape par étape vous guidera dans la configuration de l’environnement, le téléchargement des documents, la création d’un magasin vectoriel, la surveillance du traitement des fichiers et la construction d’un pipeline de chiffon entièrement fonctionnel.
1. Configuration
- Visiter le Site Web de pain mixte et créer un compte. Une fois inscrit, générez votre clé API. De même, assurez-vous que vous avez une clé API OpenAI prête.
- Ensuite, enregistrez vos clés API sous forme de variables d’environnement pour un accès sécurisé dans votre code.
- Assurez-vous que les bibliothèques Python nécessaires sont installées:
pip install mixedbread openai
- Initialisez le client de pain mixte et ouvrez le client AI à l’aide des clés API. Réglez également le dossier PAT ou PDF, nommez le magasin vectoriel et réglez le nom LLM.
import os
import time
from mixedbread import Mixedbread
from openai import OpenAI
# --- Configuration ---
# 1. Get your Mixedbread API Key
mxbai_api_key = os.getenv("MXBAI_API_KEY")
# 2. Get your OpenAI API Key
openai_api_key = os.getenv("OPENAI_API_KEY")
# 3. Define the path to the FOLDER containing your PDF files
pdf_folder_path = "/work/docs"
# 4. Vector Store Configuration
vector_store_name = "Abid Articles"
# 5. OpenAI Model Configuration
openai_model = "gpt-4.1-nano-2025-04-14"
# --- Initialize Clients ---
mxbai = Mixedbread(api_key=mxbai_api_key)
openai_client = OpenAI(api_key=openai_api_key)
2. Téléchargement des fichiers
Nous allons localiser tous les fichiers PDF dans le dossier spécifié, puis les télécharger sur le cloud à pain mixte à l’aide de l’API.
import glob
pdf_files_to_upload = glob.glob(os.path.join(pdf_folder_path, "*.pdf")) # Find all .pdf files
print(f"Found {len(pdf_files_to_upload)} PDF files to upload:")
for pdf_path in pdf_files_to_upload:
print(f" - {os.path.basename(pdf_path)}")
uploaded_file_ids = ()
print("nUploading files...")
for pdf_path in pdf_files_to_upload:
filename = os.path.basename(pdf_path)
print(f" Uploading {filename}...")
with open(pdf_path, "rb") as f:
upload_response = mxbai.files.create(file=f)
file_id = upload_response.id
uploaded_file_ids.append(file_id)
print(f" -> Uploaded successfully. File ID: {file_id}")
print(f"nSuccessfully uploaded {len(uploaded_file_ids)} files.")
Les quatre fichiers PDF ont été téléchargés avec succès.
Found 4 PDF files to upload:
- Building Agentic Application using Streamlit and Langchain.pdf
- Deploying DeepSeek Janus Pro locally.pdf
- Fine-Tuning GPT-4o.pdf
- How to Reach $500k on Upwork.pdf
Uploading files...
Uploading Building Agentic Application using Streamlit and Langchain.pdf...
-> Uploaded successfully. File ID: 8a538aa9-3bde-4498-90db-dbfcf22b29e9
Uploading Deploying DeepSeek Janus Pro locally.pdf...
-> Uploaded successfully. File ID: 52c7dfed-1f9d-492c-9cf8-039cc64834fe
Uploading Fine-Tuning GPT-4o.pdf...
-> Uploaded successfully. File ID: 3eaa584f-918d-4671-9b9c-6c91d5ca0595
Uploading How to Reach $500k on Upwork.pdf...
-> Uploaded successfully. File ID: 0e47ba93-550a-4d4b-9da1-6880a748402b
Successfully uploaded 4 files.
Vous pouvez accéder à votre tableau de bord à pain mixte et cliquer sur l’onglet «Fichiers» pour voir tous les fichiers téléchargés.
3. Créer et remplir le magasin vectoriel
Nous allons maintenant créer le magasin vectoriel et ajouter les fichiers téléchargés en fournissant la liste des ID de fichier téléchargés.
vector_store_response = mxbai.vector_stores.create(
name=vector_store_name,
file_ids=uploaded_file_ids # Add all uploaded file IDs during creation
)
vector_store_id = vector_store_response.id
4. Statut de traitement des fichiers du moniteur
Le magasin de vecteur mixte convertira chaque page des fichiers en intégres, puis les enregistrera dans le magasin vectoriel. Cela signifie que vous pouvez effectuer des recherches de similitude pour des images ou du texte dans les PDF.
Nous avons écrit du code personnalisé pour surveiller l’état de traitement des fichiers.
print("nMonitoring file processing status (this may take some time)...")
all_files_processed = False
max_wait_time = 600 # Maximum seconds to wait (10 minutes, adjust as needed)
check_interval = 20 # Seconds between checks
start_time = time.time()
final_statuses = {}
while not all_files_processed and (time.time() - start_time) < max_wait_time:
all_files_processed = True # Assume true for this check cycle
current_statuses = {}
files_in_progress = 0
files_completed = 0
files_failed = 0
files_pending = 0
files_other = 0
for file_id in uploaded_file_ids:
status_response = mxbai.vector_stores.files.retrieve(
vector_store_id=vector_store_id,
file_id=file_id
)
current_status = status_response.status
final_statuses(file_id) = current_status # Store the latest status
if current_status == "completed":
files_completed += 1
elif current_status in ("failed", "cancelled", "error"):
files_failed += 1
elif current_status == "in_progress":
files_in_progress += 1
all_files_processed = False # At least one file is still processing
elif current_status == "pending":
files_pending += 1
all_files_processed = False # At least one file hasn't started
else:
files_other += 1
all_files_processed = False # Unknown status, assume not done
print(f" Status Check (Elapsed: {int(time.time() - start_time)}s): "
f"Completed: {files_completed}, Failed: {files_failed}, "
f"In Progress: {files_in_progress}, Pending: {files_pending}, Other: {files_other} "
f"/ Total: {len(uploaded_file_ids)}")
if not all_files_processed:
time.sleep(check_interval)
# --- Check Final Processing Outcome ---
completed_count = sum(1 for status in final_statuses.values() if status == 'completed')
failed_count = sum(1 for status in final_statuses.values() if status in ('failed', 'cancelled', 'error'))
print("n--- Processing Summary ---")
print(f"Total files processed: {len(final_statuses)}")
print(f"Successfully completed: {completed_count}")
print(f"Failed or Cancelled: {failed_count}")
for file_id, status in final_statuses.items():
if status != 'completed':
print(f" - File ID {file_id}: {status}")
if completed_count == 0:
print("nNo files completed processing successfully. Exiting RAG pipeline.")
exit()
elif failed_count > 0:
print("nWarning: Some files failed processing. RAG will proceed using only the successfully processed files.")
elif not all_files_processed:
print(f"nWarning: File processing did not complete for all files within the maximum wait time ({max_wait_time}s). RAG will proceed using only the successfully processed files.")
Il a fallu près de 42 secondes pour qu’elle traite plus de 100 pages.
Monitoring file processing status (this may take some time)...
Status Check (Elapsed: 0s): Completed: 0, Failed: 0, In Progress: 4, Pending: 0, Other: 0 / Total: 4
Status Check (Elapsed: 21s): Completed: 0, Failed: 0, In Progress: 4, Pending: 0, Other: 0 / Total: 4
Status Check (Elapsed: 42s): Completed: 4, Failed: 0, In Progress: 0, Pending: 0, Other: 0 / Total: 4
--- Processing Summary ---
Total files processed: 4
Successfully completed: 4
Failed or Cancelled: 0
Lorsque vous cliquez sur l’onglet « Vector Store » sur le tableau de bord à pain mixte, vous verrez que le magasin vectoriel a été créé avec succès et qu’il a 4 fichiers stockés.
5. Construire un pipeline de chiffons
Un pipeline de chiffons se compose de trois composants principaux: la récupération, l’augmentation et la génération. Vous trouverez ci-dessous une explication étape par étape de la façon dont ces composants fonctionnent ensemble pour créer un système de réponses de questions robuste.
La première étape du pipeline de chiffons est la récupération, où le système recherche des informations pertinentes en fonction de la requête de l’utilisateur. Ceci est réalisé en interrogeant un magasin vectoriel pour trouver les résultats les plus similaires.
user_query = "How to Deploy Deepseek Janus Pro?"
retrieved_context = ""
search_results = mxbai.vector_stores.search(
vector_store_ids=(vector_store_id), # Search within our newly created store
query=user_query,
top_k=10 # Retrieve top 10 relevant chunks across all documents
)
if search_results.data:
# Combine the content of the chunks into a single context string
context_parts = ()
for i, chunk in enumerate(search_results.data):
context_parts.append(f"Chunk {i+1} from '{chunk.filename}' (Score: {chunk.score:.4f}):n{chunk.content}n---")
retrieved_context = "n".join(context_parts)
else:
retrieved_context = "No context was retrieved."
L’étape suivante est l’augmentation, où le contexte récupéré est combiné avec la requête de l’utilisateur pour créer une invite personnalisée. Cette invite comprend des instructions système, la question de l’utilisateur et le contexte récupéré.
prompt_template = f"""
You are an assistant answering questions based *only* on the provided context from multiple documents.
Do not use any prior knowledge. If the context does not contain the answer to the question, state that clearly.
Context from the documents:
---
{retrieved_context}
---
Question: {user_query}
Answer:
"""
La dernière étape est la génération, où l’invite combinée est envoyée à un modèle de langue (GPT-4.1-nano d’OpenAI) pour générer la réponse. Ce modèle est choisi pour sa rentabilité et sa vitesse.
response = openai_client.chat.completions.create(
model=openai_model,
messages=(
{"role": "user", "content": prompt_template}
),
temperature=0.2,
max_tokens=500
)
final_answer = response.choices(0).message.content.strip()
print(final_answer)
Le pipeline de chiffons produit des réponses très précises et contextuellement pertinentes.
To deploy DeepSeek Janus Pro locally, follow these steps:
1. Install Docker Desktop from https://www.docker.com/ and set it up with default settings. On Windows, ensure WSL is installed if prompted.
2. Clone the Janus repository by running:
```
git clone https://github.com/kingabzpro/Janus.git
```
3. Navigate into the cloned directory:
```
cd Janus
```
4. Build the Docker image using the provided Dockerfile:
```
docker build -t janus .
```
5. Run the Docker container with the following command, which sets up port forwarding, GPU access, and persistent storage:
```
docker run -it --rm -p 7860:7860 --gpus all --name janus_pro -e TRANSFORMERS_CACHE=/root/.cache/huggingface -v huggingface:/root/.cache/huggingface janus:latest
```
6. Wait for the container to download the model and start the Gradio application. Once running, access the app at http://localhost:7860/.
7. The application has two sections: one for image understanding and one for image generation, allowing you to upload images, ask for descriptions or poems, and generate images based on prompts.
This process enables you to deploy DeepSeek Janus Pro locally on your machine.
Conclusion
La construction d’une application de chiffon à l’aide de chair mixte était un processus simple et efficace. L’équipe de paries mixtes recommande fortement d’utiliser son tableau de bord pour des tâches telles que le téléchargement des documents, l’analyse des données, la création de magasins vectoriels et effectuer des recherches de similitude via une interface utilisateur intuitive. Cette approche permet aux professionnels de divers domaines de créer plus facilement leurs propres applications de compréhension de texte sans nécessiter une expertise technique approfondie.
Dans ce tutoriel, nous avons appris comment l’API unifié de MixedBread simplifie le processus de construction d’un pipeline de chiffons. L’implémentation ne nécessite que quelques étapes et fournit des résultats rapides et précis. Contrairement aux méthodes traditionnelles qui grattent le texte des documents, mixtes a converti des pages entières en intégres, permettant une récupération plus efficace et précise des informations pertinentes. Cette approche d’intégration de niveau de page garantit que les résultats sont contextuellement riches et très pertinents.
Abid Ali Awan (@ 1abidaliawan) est un professionnel certifié des data scientifiques qui aime construire des modèles d’apprentissage automatique. Actuellement, il se concentre sur la création de contenu et la rédaction de blogs techniques sur l’apprentissage automatique et les technologies de science des données. Abid est titulaire d’une maîtrise en gestion technologique et d’un baccalauréat en génie des télécommunications. Sa vision est de construire un produit d’IA en utilisant un réseau de neurones graphiques pour les étudiants aux prises avec une maladie mentale.
Source link



