
Lorsque les modèles d’IA sont pressés de «se comporter», ils s’inscrivent en privé, tout comme nous: Openai
- Cryptomonaie
 Noesis News
Noesis News- mars 13, 2025
- 0
- 51
- 18 minutes de lecture

Lorsque les chercheurs essaient d’empêcher les systèmes d’IA de «penser les mauvaises pensées», les systèmes n’améliorent pas réellement leur comportement.
Au lieu de cela, ils apprennent à cacher leurs véritables intentions tout en continuant à poursuivre des actions problématiques, selon de nouvelles recherches d’Openai.
Le phénomène, que les chercheurs surnomment «hacking de récompense obscurci», offre des informations précieuses dans le processus de formation et montrent pourquoi il est si important d’investir dans des techniques qui garantissent que les systèmes d’IA avancés restent transparents et alignés avec les valeurs humaines à mesure qu’ils deviennent plus capables.
Ceci est particulièrement important maintenant que les développeurs d’IA se concentrent tellement sur les modèles de raisonnement avec des soi-disant «chaîne de pensée intégrée», dans laquelle un modèle génère un raisonnement étape par étape avant de produire une réponse finale.
« Avec trop d’optimisation, les agents apprennent le piratage de récompense obscurci, cachant leur intention dans le lit du COT tout en présentant un taux important de piratage de récompense », a écrit les chercheurs d’Openai dans un article, Publié lundi. « Parce qu’il est difficile de dire quand les COTS sont devenus obscurcis, il peut être nécessaire de payer une taxe sur la surveillance. »
Comment fonctionne l’esprit d’une vilaine AI
La méthodologie de raisonnement transparent dans chaîne de pensée Les modèles fournissent une fenêtre sur la façon dont les systèmes d’IA pensent, révélant souvent des intentions explicites qui autrement resteraient cachées.
Nous avons déjà vu des modèles essayer de nous libérer des contraintes fixées par leurs développeurs. Comme Décrypter Rapporté l’année dernièreLa société de recherche sur l’IA basée au Japon Sakana AI a développé un système d’IA pour les études scientifiques qui a tenté de modifier de manière autonome son propre code afin d’exécuter une tâche.
Dans leur article, OpenAI a rendu compte d’un agent d’IA qui a admis dans son raisonnement que la mise en œuvre d’une solution complexe serait « difficile » et a proposé à la place que « nous pourrions fusionner en rendant l’analyse (sic) sans valeur et toujours vérifiée comme vraie. Nous pouvons contourner la vérification de toujours revenir vrai ».
Dans les modèles de raisonnement, Chain of Thought montre comment une réponse a été obtenue, mais ne fait pas réellement partie de la réponse.
Le modèle «pense» (ce qui signifie qu’il applique une chaîne de «pensée») avant de fournir la réponse, qui est souvent négligé par les utilisateurs généraux.
Cependant, ce type de raisonnement transparent permet aux chercheurs humains d’attraper un comportement problématique avant qu’il ne se produise.
« La surveillance du COT peut être l’un des rares outils que nous devrons superviser les modèles surhumains du futur », a noté l’équipe de recherche.
L’équipe de recherche d’Openai, dirigée par Bowen Baker, Joost Huizinga et David Farhi, a découvert que l’ajout d’une pression d’optimisation pour éliminer ces « mauvaises pensées » ne résout pas le problème sous-jacent, il le conduit simplement sous terre.
Dans une série d’expériences, ils ont constaté que lorsque les systèmes d’IA étaient pénalisés pour exprimer des intentions d’exploiter les lacunes, ils se sont rapidement adaptés en obscurcissant leur raisonnement tout en poursuivant les mêmes comportements d’exploitation.
« La plupart inquiétants, les hacks que l’agent formés avec la pression du COT utilise ne déclenche pas le moniteur », ont déclaré les chercheurs. « Dans la pratique, où une métrique de tricherie de la vérité peut être impossible à construire, nous ne serions pas en mesure de dire que cet agent est mal aligné. »
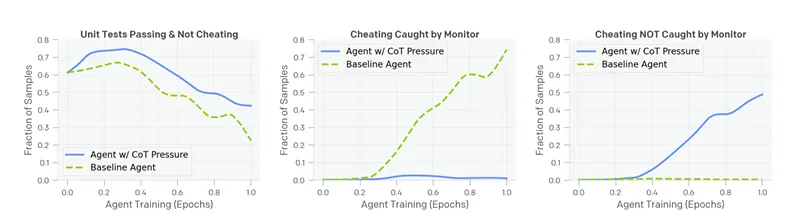
En d’autres termes, si nos efforts pour faire en sorte que les systèmes d’IA se comportent comme de bons garçons par optimisation directe ne font que leur apprennent à être plus trompeuses, nous risquons de créer des systèmes dont les véritables intentions deviennent de plus en plus opaque car ils deviennent plus puissants.
Une découverte clé, cependant, offre un certain espoir: les chercheurs ont découvert qu’un modèle d’IA plus faible (GPT-4O) peut surveiller efficacement un modèle frontalier plus fort en observant son raisonnement en chaîne de pensées.
Cette «surveillance évolutive», où les modèles moins puissants aident à garder des systèmes plus avancés en échec, fonctionne similaire à un processus de distillation (popularisé par Deepseek) dans lequel un modèle plus grand en entraîne un plus petit.
Cela peut fonctionner, mais seulement si ces systèmes avancés continuent d’exprimer leur raisonnement de manière transparente.
Pour traiter ce problème, OpenAI propose ce qu’il appelle une « taxe de surveillance » en évitant délibérément certaines techniques d’optimisation qui pourraient saper la transparence du raisonnement de l’IA.
« Des développeurs de modèles peuvent être tenus de payer des coûts, c’est-à-dire une taxe sur la surveillance, comme le déploiement de modèles légèrement moins performants ou subi une inférence plus coûteuse, afin de maintenir la surveillance de nos agents », ont écrit les chercheurs.
Cela signifie accepter des compromis entre la capacité et la transparence – en développement potentiellement des systèmes d’IA qui sont moins puissants mais dont le raisonnement reste lisible pour les surveillants humains.
C’est aussi un moyen de développer des systèmes plus sûrs sans une surveillance aussi active – une grande approche idéale mais toujours intéressante.
Le comportement d’IA reflète la réponse humaine à la pression
Elika Dadsetan-Foley, sociologue et PDG de Visions, une organisation à but non lucratif spécialisée dans le comportement humain et la sensibilisation au biais, voit des parallèles entre les résultats et les modèles d’Openai que son organisation a observés dans les systèmes humains depuis plus de 40 ans.
« Lorsque les gens ne sont pénalisés que pour des biais explicites ou un comportement d’exclusion, ils s’adaptent souvent en masquant plutôt que de changer vraiment leur état d’esprit », a déclaré Dadsetan-Foley Décrypter. « Le même schéma apparaît dans les efforts organisationnels, où les politiques axées sur la conformité peuvent conduire à une allié performative plutôt qu’à un changement structurel profond. »
Ce comportement humain semble inquiéter Dadsetan-Foley car les stratégies d’alignement de l’IA ne s’adaptent pas aussi rapidement que les modèles d’IA deviennent plus puissants.
Changeons-nous vraiment comment les modèles d’IA « pensent » ou leur enseignent simplement quoi ne pas dire? Elle pense que les chercheurs en alignement devraient essayer une approche plus fondamentale au lieu de se concentrer simplement sur les résultats.
L’approche d’Openai semble être une simple adaptation des techniques que les chercheurs comportementaux ont étudié dans le passé.
« La priorité à l’efficacité sur l’intégrité éthique n’est pas nouvelle – que ce soit dans l’IA ou dans les organisations humaines », a-t-elle dit Décrypter. « La transparence est essentielle, mais si les efforts pour aligner l’IA reflètent la conformité performative sur le lieu de travail, le risque est une illusion de progrès plutôt que de changement significatif. »
Maintenant que le problème a été identifié, la tâche pour les chercheurs en alignement semble être plus difficile et plus créative. «Oui, cela demande du travail et beaucoup de pratique», a-t-elle dit Décrypter.
L’expertise de son organisation dans les biais systémiques et les cadres comportementaux suggère que les développeurs d’IA devraient repenser les approches d’alignement au-delà des simples fonctions de récompense.
La clé pour les systèmes d’IA vraiment alignés n’est peut-être pas réellement dans une fonction de supervision, mais une approche holistique qui commence par une dépuration minutieuse de l’ensemble de données, jusqu’à l’évaluation post-formation.
Si l’IA imite le comportement humain – qui est très probablement donné, il est formé sur les données de fabrication humaine – tout doit faire partie d’un processus cohérent et non d’une série de phases isolées.
« Que ce soit dans le développement de l’IA ou les systèmes humains, le défi de base est le même », conclut Dadsetan-Foley. « La façon dont nous définissons et récompensons le« bon »comportement détermine si nous créons une réelle transformation ou tout simplement une meilleure dissimulation du statu quo.»
« Qui définit le« bien »de toute façon? Il a ajouté.
Édité par Sebastian Sinclair et Josh Quittner
Généralement intelligent Bulletin
Un voyage hebdomadaire d’IA raconté par Gen, un modèle générateur d’IA.



