
Liquide AI libère le modèle de fondation sur les appareils LFM2
- Intelligence Artificielle
 Noesis News
Noesis News- 0
- 11 minutes de lecture
Liquid AI a déclaré qu’avec ses modèles de fondation, il espère atteindre l’équilibre optimal entre la qualité, la latence et la mémoire pour des tâches spécifiques et des exigences matérielles. | Source: liquide AI
Cette semaine, Liquid AI a publié LFM2, un modèle de fondation liquide (LFM) qui, selon la société, établit un nouveau déploiement de la qualité, de la vitesse et de l’efficacité de la mémoire.
Le déplacement de grands modèles génératifs de nuages éloignés à des LLMs maigres, sur les appareils, déverrouille la latence en millisecondes, la résilience hors ligne et la confidentialité des données de données. Ce sont des capacités essentielles pour les téléphones, les ordinateurs portables, les voitures, les robots, les appareils portables, les satellites et autres points de terminaison qui doivent raisonner en temps réel.
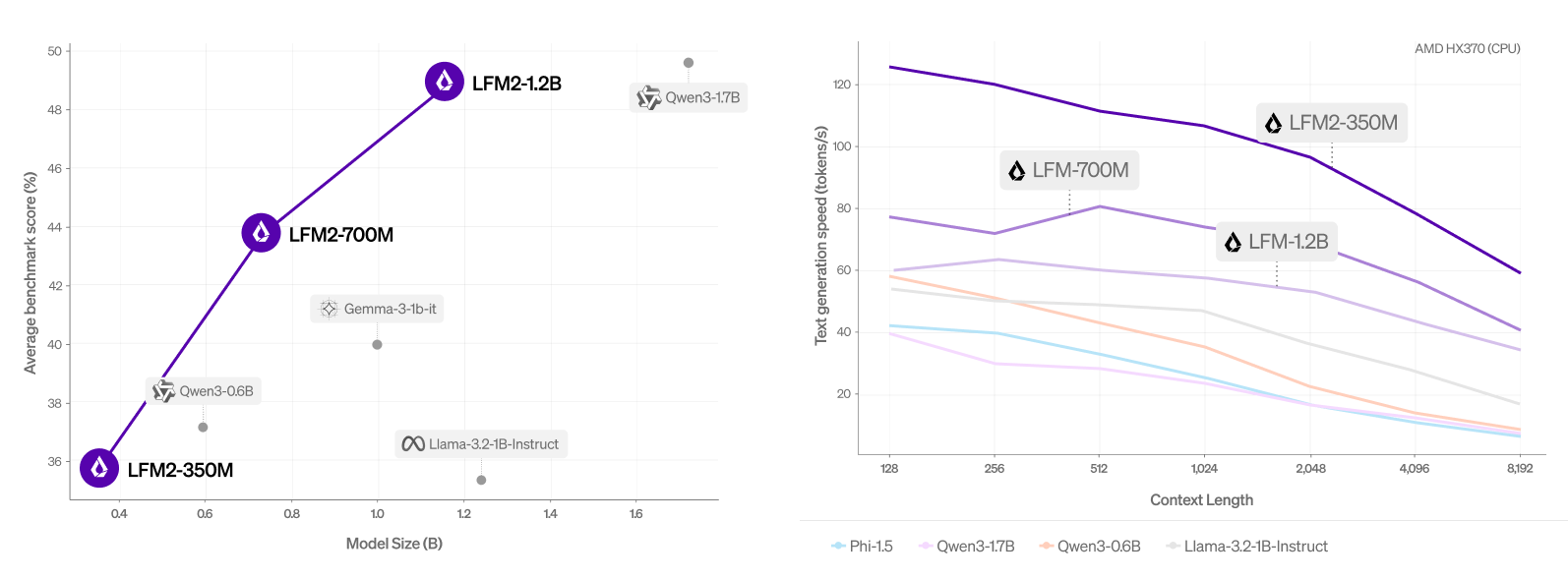
Liquid AI a conçu le modèle pour fournir une expérience Gen-AI rapide sur les appareils à travers l’industrie, débloquant un nombre massif de dispositifs pour génératif IA charges de travail. Construit sur une nouvelle architecture hybride, LFM2 fournit deux fois plus de performances de décodage et de préfusion rapide que QWEN3 sur CPU. Il surpasse également considérablement les modèles dans chaque classe de taille, ce qui les rend idéaux pour alimenter des agents d’IA efficaces, a indiqué la société.
The Cambridge, Mass. entreprise ont déclaré que ces gains de performance font de LFM2 le choix idéal pour les cas d’utilisation locale et de bord. Au-delà des prestations de déploiement, sa nouvelle infrastructure d’architecture et de formation offre une amélioration trois fois de l’efficacité de la formation par rapport à la génération LFM précédente.
Le co-fondateur de Liquid AI et directeur du laboratoire d’informatique et de renseignement artificiel du MIT (CSAIL), Daniela Rus, a livré un discours Robotics Summit & Expo 2025un événement de développement de la robotique produits par le rapport robot.
Les modèles LFM2 sont disponibles aujourd’hui sur un visage étreint. Liquid AI les publie sous une licence ouverte, qui est basée sur Apache 2.0. La licence permet aux utilisateurs d’utiliser librement les modèles LFM2 à des fins académiques et de recherche. Les entreprises peuvent également utiliser les modèles commercialement s’ils sont plus petits (moins de 10 millions de dollars).
Liquid AI propose de petits modèles de fondation multimodaux avec une pile de déploiement sécurisée de qualité d’entreprise qui transforme chaque appareil en un appareil AI, localement. Ceci, dit-il, lui donne la possibilité d’obtenir une part démesurée sur le marché alors que les entreprises passent de Cloud LLMS à des intelligences rentables, rapides, privées et sur les prémations.
https://www.youtube.com/watch?v=vmibynqrs9y
Que peut faire LFM2?
Ai liquide a dit LFM2 Atteint une formation trois fois plus rapide par rapport à sa génération précédente. Il bénéficie également d’un décodage et de la vitesse de décodage et de pré-remplies plus rapides sur CPU par rapport à QWEN3. De plus, la société a affirmé que LFM2 surpasse les modèles de taille similaire dans plusieurs catégories de référence, y compris les connaissances, les mathématiques, les suites d’instructions et les capacités multilingues.
LFM2 est équipé d’une nouvelle architecture. Il s’agit d’un modèle liquide hybride avec des portes multiplicatives et des convolutions courtes. Il se compose de 16 blocs: 10 blocs de convolution à court terme à double réparation et 6 blocs d’attention de la requête groupée.
Qu’il soit déployé sur des smartphones, des ordinateurs portables ou des véhicules, LFM2 fonctionne efficacement sur le matériel CPU, GPU et NPU. Le système complet de l’entreprise comprend des moteurs d’architecture, d’optimisation et de déploiement pour accélérer le chemin du prototype au produit.
L’IA liquide libère les poids de trois points de contrôle denses avec des paramètres de 0,35b, 0,7b et 1,2b. Les utilisateurs peuvent les essayer maintenant sur le terrain de jeu liquide, le visage étreint et OpenRouter.
Comment LFM2 fonctionne-t-il contre d’autres modèles?
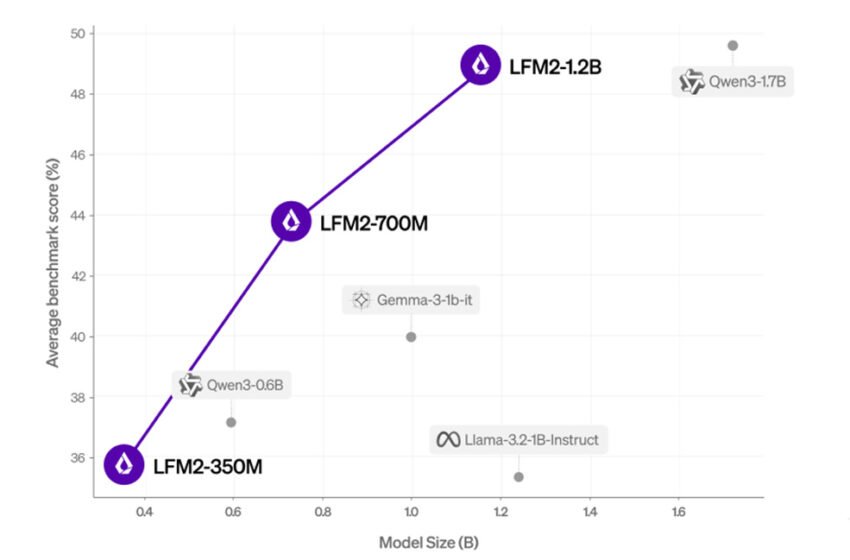
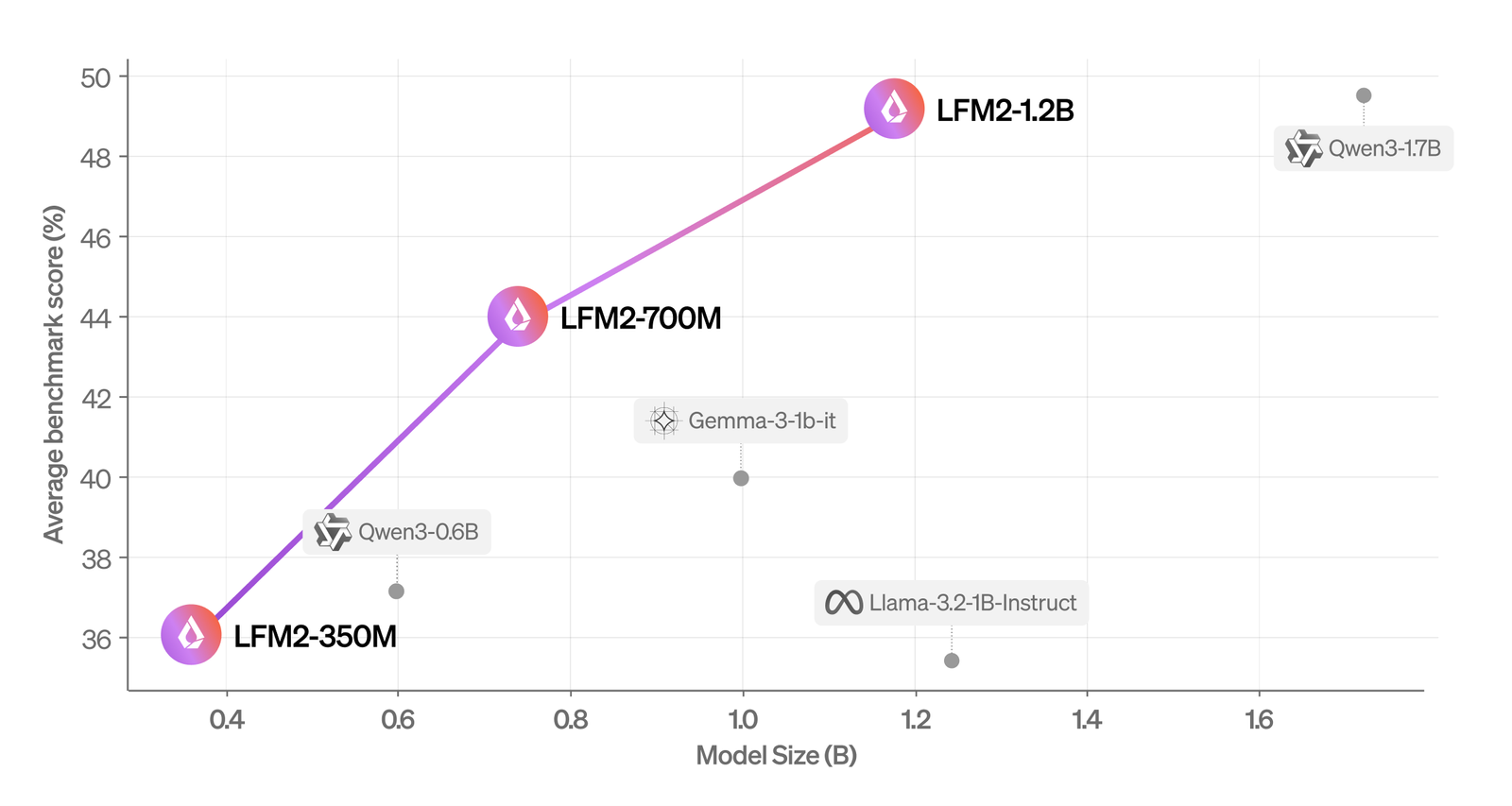
Score moyen (mmlu, ifeval, ifbench, gsm8k, mmmlu) par rapport à la taille du modèle. | Source: liquide AI
La société a évalué LFM2 à l’aide de repères automatisés et un cadre LLM-AS-A-A-Judge pour obtenir un aperçu complet de ses capacités. Il a constaté que le modèle surpasse les modèles de taille similaire dans différentes catégories d’évaluation.
Liquid AI a également évalué LFM2 sur sept repères populaires couvrant les connaissances (MMLU à 5 tirs, 0-shot gpqa), instruction suivant (ifeval, ifbench), mathématiques (0-shot GSM8K, 5-shot mgsm) et multilinguisme (5-shot openai mmmlu, 5-shot mgsm) à nouveau) avec sept langues (arabique, le français, le 5-shot, le mgsm Coréen et chinois).
Il a constaté que LFM2-1.2B fonctionne de manière compétitive avec QWEN3-1.7b, un modèle avec un nombre de paramètres de 47% plus grand. LFM2-700M surpasse Gemma 3 1b, et son plus petit point de contrôle, LFM2-350M, est compétitif avec QWEN3-0.6B et LLAMA 3.2 1B Instruct.
Comment liquide a été formé LFM2
Pour former et mettre à l’échelle LFM2, la société a sélectionné trois tailles de modèle (350m, 700m et paramètres 1,2b) ciblant les charges de travail du modèle de langage à faible latence. Tous les modèles ont été formés sur des jetons 10T tirés d’un corpus pré-formation comprenant environ 75% d’anglais, 20% multilingue et 5% de données de code provenant du web et du matériel sous licence.
Pour les capacités multilingues de LFM2, la société s’est principalement concentrée sur les langues japonaises, arabes, coréennes, espagnoles, françaises et allemandes.
Pendant la pré-formation, l’IA liquide a exploité son LFM1-7b existant en tant que modèle d’enseignant dans un cadre de distillation de connaissances. L’entreprise a utilisé l’entropie croisée entre les résultats des étudiants de LFM2 et les résultats de l’enseignant LFM1-7B comme signal de formation principal tout au long du processus de formation des jetons 10T. La longueur du contexte a été étendue pendant la pré-formation à 32k.
Le post-formation a commencé avec une étape de réglage fin supervisée (SFT) à très grande échelle sur un mélange de données diversifié pour débloquer les capacités généralistes. Pour ces petits modèles, l’entreprise a trouvé avantageux de s’entraîner directement sur un ensemble représentatif de tâches en aval, telles que des appels de chiffon ou de fonction. L’ensemble de données est composé de sources open-source, agréées, ainsi que de données synthétiques ciblées, où l’entreprise assure une haute qualité grâce à une combinaison de score d’échantillon quantitatif et d’heuristique qualitative.
Liquid AI applique en outre un algorithme d’optimisation des préférences directes personnalisé avec une normalisation de longueur sur une combinaison de données hors ligne et de données semi-en ligne. L’ensemble de données semi-online est généré en échantillonnant plusieurs compléments à partir de son modèle, basé sur un ensemble de données SFT Seed.
La société marque ensuite toutes les réponses avec les juges de LLM et crée des paires de préférences en combinant les compléments les plus élevés et les plus bas parmi les échantillons SFT et sur la politique. Les ensembles de données hors ligne et semi-online sont en outre filtrés en fonction d’un seuil de score. Liquid AI crée plusieurs points de contrôle des candidats en faisant varier les hyperparamètres et les mélanges d’ensembles de données. Enfin, il combine une sélection de ses meilleurs points de contrôle dans un modèle final via différentes techniques de fusion de modèles.
Source link



