
Les modèles de grands comportements pré-entraînés accélèrent l’apprentissage du robot
- Intelligence Artificielle
 Noesis News
Noesis News- 0
- 12 minutes de lecture


Deux cobots utilisant des déploiements d’évaluation autonomes à partir de LBM à finetuned pour effectuer des comportements à horizon long, comme l’installation d’un rotor de vélo. | Source: Toyota Research Institute
Le Toyota Research Institute (TRI) a publié cette semaine les résultats de son étude sur les grands modèles de comportement (LBM) qui peuvent être utilisés pour former des robots à usage général. L’étude a montré qu’un seul LBM peut apprendre des centaines de tâches et utiliser des connaissances antérieures pour acquérir de nouvelles compétences avec 80% de données de formation en moins.
Les LBM sont pré-entraînés sur de grands ensembles de données de manipulation diverses. Malgré leur popularité croissante, la communauté de la robotique en sait étonnamment peu de choses sur les nuances de ce que les LBM offrent réellement. Tri Les travaux visent à faire la lumière sur les progrès récents dans l’algorithme et la conception de l’ensemble de données avec cette étude.
En tout, TRI a déclaré que ses résultats soutiennent largement la récente augmentation de la popularité des modèles de fondation de robot de style LBM, ajoutant à des preuves que la pré-entraînement à grande échelle sur diverses données de robot est un chemin viable vers des robots plus capables, mais avec quelques points de prudence.
Les robots à usage général promettent un avenir où les robots des ménages peuvent fournir une assistance quotidienne. Cependant, nous ne sommes pas au point où un robot peut s’attaquer aux tâches du ménage moyen. Les LBM, ou les systèmes d’IA incarnés qui prennent des données de capteur de robot et les actions de sortie, pourraient changer cela, a déclaré Tri.
En 2024, Tri a remporté un RBR50 Robotics Innovation Award Pour son travail, le bâtiment LBMS pour l’enseignement rapide des robots.
Un aperçu des conclusions de Tri
https://www.youtube.com/watch?v=delpntgzjt4
TRI a formé une série de LBM basés sur la diffusion sur près de 1 700 heures de données robot et a effectué 1 800 déploiements d’évaluation du monde réel et plus de 47 000 déploiements de simulation pour étudier rigoureusement leurs capacités. Il a constaté que LBMS:
- Fournir des améliorations de performances cohérentes par rapport aux politiques à partir de la mise
- Permettre de nouvelles tâches à apprendre avec 3-5 × moins de données dans des contextes difficiles nécessitant une robustesse à une variété de facteurs environnementaux
- Améliorer régulièrement car les données de pré-formation augmentent
Même avec seulement quelques centaines d’heures diverses de données, et seulement quelques centaines de démos par comportement, les performances ont bondi de manière significative, a déclaré Tri. La pré-entraînement fournit des performances cohérentes soulèves aux échelles préalables que prévu. Il n’y a pas encore de valeur Internet de données robotiques, mais les avantages apparaissent bien avant cette échelle – un signe prometteur pour permettre des cycles vertueux d’acquisition de données et de performances bootstrapées, a affirmé Tri.
La suite d’évaluation de TRI comprend plusieurs tâches réelles à horizon à long horizon romanes et très difficiles; Finetuned et évalué dans ce contexte, la pré-formation de LBM améliore les performances malgré que ces comportements soient très distincts des tâches de pré-entraînement.
À l’intérieur de l’architecture et des données de TRI de TRI
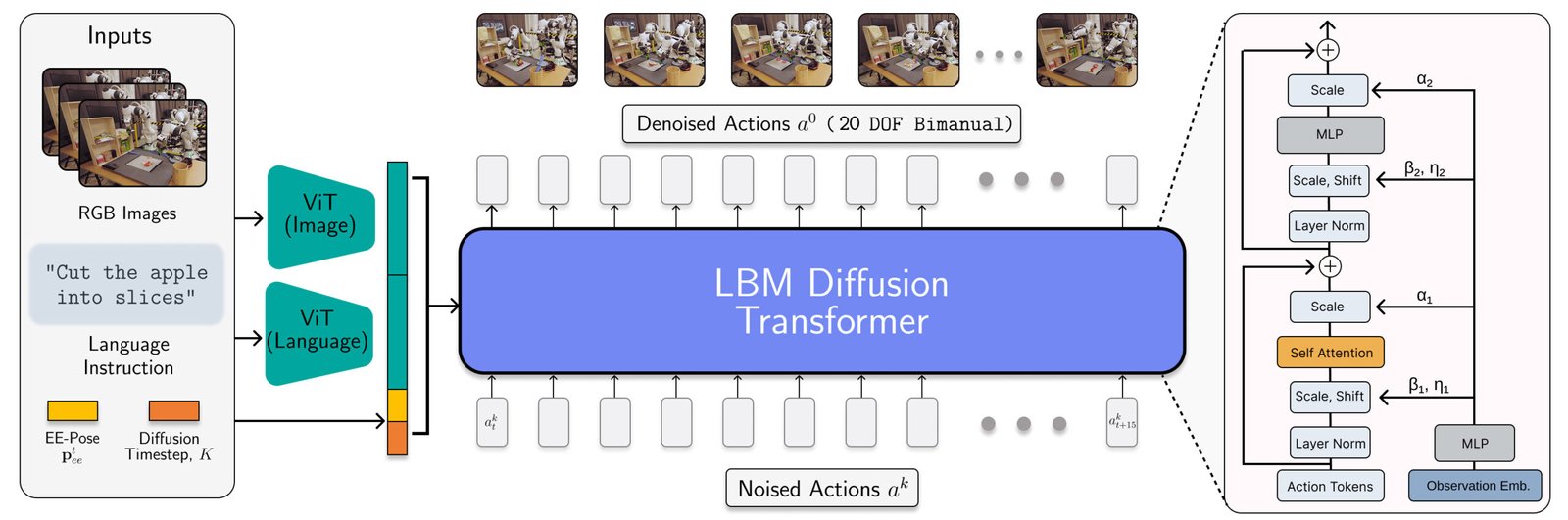
L’architecture LBM est instanciée comme un transformateur de diffusion qui prédit les actions du robot. | Source: Toyota Research Institute
Les LBM de TRI sont des politiques de diffusion multitâche à l’échelle avec des encodeurs multimodaux en langage de vision VIT et une tête de déniisation transformateur conditionnée sur des observations codées via ADALN. Ces modèles consomment des caméras de poignet et de scène, de proprioception robot et d’invites en langue et prédisent 16 morceaux d’action (1,6 seconde).
Les chercheurs ont formé le LBMS sur un mélange de 468 heures de données de téléopération de robot bimanuelle collectées en interne, 45 heures de données de téléopération collectées par la simulation, 32 heures de données d’interface de manipulation universelle (UMI) et environ 1 1550 heures de données Internet garanties à partir de l’ensemble de données X-EMBODiment ouverte.
Bien que la proportion de données de simulation soit petite, son inclusion dans le mélange de pré-formation de Tri garantit qu’elle peut évaluer le même point de contrôle LBM dans SIM et réel.
Méthodes d’évaluation de Tri
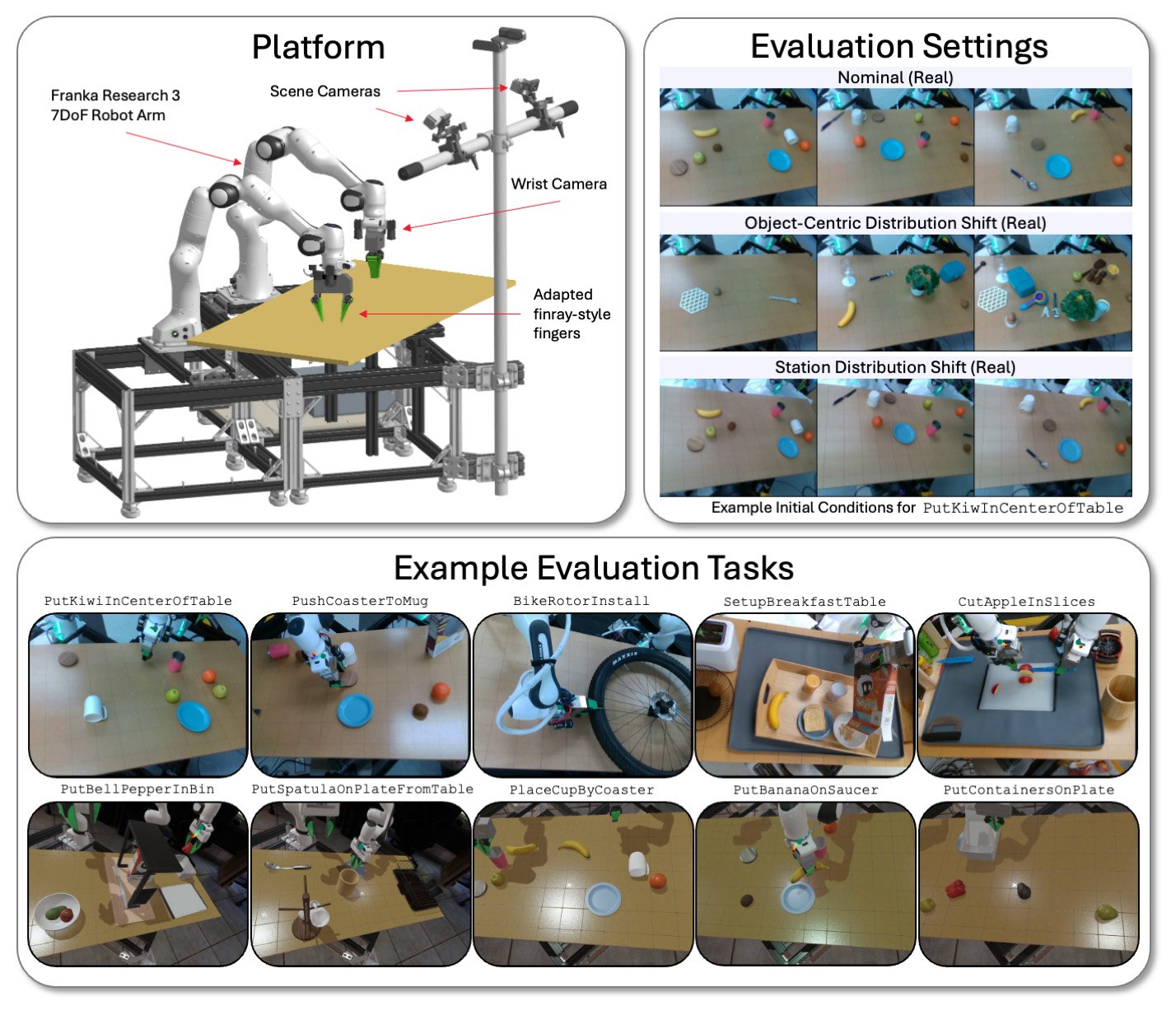
TRI évalue ses modèles LBM sur une plate-forme bimanuelle à travers une variété de tâches et de conditions environnementales en simulation et dans le monde réel. | Source: Toyota Research Institute
TRI évalue ses LBM sur les stations bimanuelles physiques et simulées drake utilisant des bras Franka Panda FR3 et jusqu’à six caméras – jusqu’à deux sur chaque poignet, et deux caméras de scène statique.
Il évalue les modèles sur les tâches observées (présentes dans les données de pré-formation) et les tâches invisibles (que TRI utilise pour affiner son modèle pré-entraîné). La suite d’évaluation de TRI se compose de 16 tâches simulées de prélèvement à l’abri, de 3 tâches réelles du monde du monde, de 5 tâches simulées à long-horizon auparavant invisibles, et 5 tâches complexes complexes invisibles à long-horizon.
Chaque modèle a été testé via 50 déploiements pour chaque tâche réelle et 200 déploiements pour chaque tâche de simulation. Cela permet un niveau élevé de rigueur statistique dans notre analyse, les modèles pré-entraînés évalués sur 4 200 déploiements sur 29 tâches.
Tri a déclaré qu’il contrôle soigneusement les conditions initiales pour être cohérentes à la fois dans le monde réel et la simulation. Il effectue également des tests aveugles de style A / B dans le monde réel avec une signification statistique calculée via un cadre de test d’hypothèse séquentiel.
De nombreux effets que les chercheurs ont observés n’étaient mesurables qu’avec des échantillons plus grands que standard et des tests statistiques minutieux non standard pour la robotique empirique. Il est facile pour le bruit en raison de la variation expérimentale pour nain les effets mesurés, et de nombreux articles robotiques peuvent mesurer le bruit statistique en raison de la puissance statistique insuffisante.
Les meilleurs plats de Tri de la recherche
L’un des principaux de l’équipe plats à emporter Est-ce que les performances financées s’améliorent en douceur avec l’augmentation des données de pré-formation. Aux échelles de données que nous avons examinées, Tri n’a vu aucune preuve de discontinuités de performance ou de points d’inflexion nets; IA La mise à l’échelle semble bien vivante en robotique.
TRI a cependant connu des résultats mitigés avec des LBM pré-entraînés non fintunés, cependant. En encourageant, il a constaté qu’un seul réseau est capable d’apprendre de nombreuses tâches simultanément, mais il n’observe pas une surperformance cohérente à partir de l’entraînement à la tâche unique sans réglage. Tri s’attend à ce que cela soit en partie dû à la direction du langage de son modèle.
Dans les tests internes, TRI a déclaré avoir vu des signes précoces prometteurs que des prototypes VLA plus importants surmontent une partie de cette difficulté, mais plus de travail est nécessaire pour examiner rigoureusement cet effet dans des modèles de capacité de langue plus élevée.
En ce qui concerne les points de prudence, Tri a déclaré que des choix de conception subtils comme la normalisation des données peuvent avoir de grands effets sur les performances, dominant souvent des changements architecturaux ou algorithmiques. Il est important que ces choix de conception soient soigneusement isolés pour éviter de confondre la source des changements de performance.
Source link



