
Les bases des problèmes de python de débogage
- Intelligence Artificielle
 Noesis News
Noesis News- 0
- 44 minutes de lecture




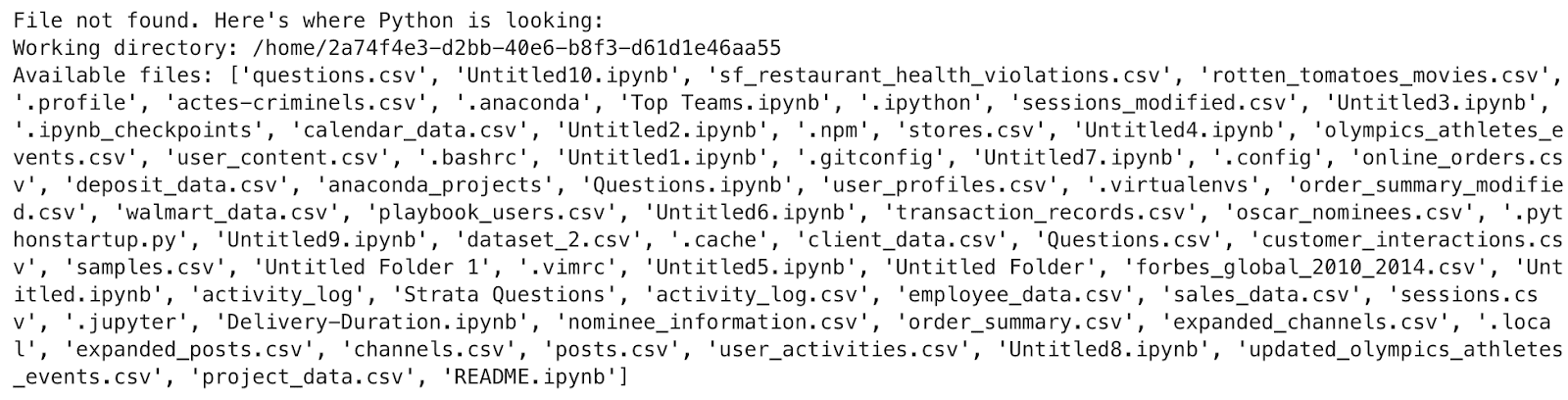


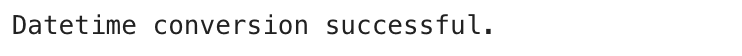


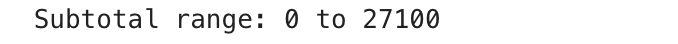
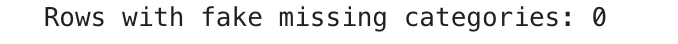



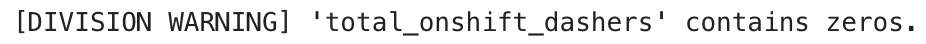







Image de l’auteur | Toile
Avez-vous déjà exécuté un script Python et vous souhaitez immédiatement que vous n’ayez pas appuyé sur Entrée?
Le débogage de la science des données n’est pas seulement un acte; C’est une compétence de survie – en particulier lorsqu’il s’agit de jeux de données désordonnés ou de concevoir des modèles de prédiction sur lesquels les personnes réelles comptent.
Dans cet article, nous explorerons les bases du débogage, en particulier dans vos workflows de science des données, en utilisant un ensemble de données réel à partir d’un travail de livraison Doordash, et surtout, comment déboguer comme un pro.
Prédiction de la durée de la livraison Doordash: à quoi traitons-nous?
Dans ces données projetDoordash a demandé à ses candidats en science des données de prédire la durée de la livraison. Regardons d’abord les informations sur l’ensemble de données. Voici le code:
Voici la sortie:
Il semble qu’ils n’aient pas fourni la durée de livraison, vous devez donc le calculer ici. C’est simple, mais pas de soucis si vous êtes un débutant. Voyons comment il peut être calculé.
import pandas as pd
from datetime import datetime
# Assuming historical_data is your DataFrame
historical_data("created_at") = pd.to_datetime(historical_data('created_at'))
historical_data("actual_delivery_time") = pd.to_datetime(historical_data('actual_delivery_time'))
historical_data("actual_total_delivery_duration") = (historical_data("actual_delivery_time") - historical_data("created_at")).dt.total_seconds()
historical_data.head()
Voici la tête de la sortie; vous pouvez voir le actual_total_delivery_duration.
Bien, maintenant nous pouvons commencer! Mais avant cela, voici le langage de définition des données pour cet ensemble de données.
Colonnes dans historical_data.csv
Caractéristiques du temps:
- Market_id: une ville / région dans laquelle Doordash opère, par exemple, Los Angeles, donnée dans les données comme identifiant.
- créé_at: horodatage dans UTC lorsque la commande a été soumise par le consommateur à Doordash. (Remarque: cet horodatage est en UTC, mais au cas où vous en auriez besoin, le fuseau horaire réel de la région était américain / Pacifique).
- réel_delivery_time: horodatage dans UTC lorsque la commande a été livrée au consommateur.
Caractéristiques du magasin:
- Store_id: une pièce d’identité représentant le restaurant pour lequel la commande a été soumise.
- Store_primary_category: Catégorie de cuisine du restaurant, par exemple, italien, asiatique.
- ORDER_PROTOCOL: Un magasin peut recevoir des commandes de Doordash via de nombreux modes. Ce champ représente un ID indiquant le protocole.
Caractéristiques de commande:
- Total_items: nombre total d’éléments dans la commande.
- Sous-total: valeur totale de la commande soumise (en cents).
- NUM_DISTIND_ITEMS: Nombre d’éléments distincts inclus dans l’ordre.
- min_item_price: prix de l’article avec le moins de coût de l’ordre (en cents).
- MAX_ITEM_PRICE: Prix de l’article avec le coût le plus élevé de l’ordre (en cents).
Caractéristiques du marché:
Doordash étant un marché, nous avons des informations sur l’état du marché lorsque la commande est passée, qui peut être utilisée pour estimer le délai de livraison. Les fonctionnalités suivantes sont des valeurs au moment de created_at (Temps de soumission de la commande):
- TOTAL_ONSHIFT_DASHERS: Nombre de dasters disponibles à moins de 10 miles du magasin au moment de la création de commande.
- total_busy_dashers: sous-ensemble de ce qui précède
total_onshift_dashersqui travaillent actuellement sur une commande. - TOTAL_OUTANNIEMS_ORDERS: Nombre de commandes à moins de 10 miles de cette commande qui sont actuellement en cours de traitement.
Prédictions des autres modèles:
Nous avons des prévisions d’autres modèles pour différentes étapes du processus de livraison que nous pouvons utiliser:
- ESTIMATED_ORDE_PLACE_DURATION: Temps estimé pour que le restaurant reçoive la commande de Doordash (en quelques secondes).
- ESTIMATED_STORE_TO_CONSUMER_DRIVING_DURANT: Temps de déplacement estimé entre le magasin et le consommateur (en secondes).
Super, alors commençons!
Erreurs de python communes dans les projets de science des données
Dans cette section, nous découvrirons les erreurs de débogage communs dans l’un des Projets de science des donnéesà commencer par la lecture de l’ensemble de données et à passer à la partie la plus importante: la modélisation.
Lire l’ensemble de données: FileNotFoundErrorAvertissement dtype et corrects
Cas 1: fichier introuvable – classique
En science des données, votre premier bug vous salue souvent read_csv. Et pas avec un bonjour. Débogons ce moment exact ensemble, ligne par ligne. Voici le code:
import pandas as pd
try:
df = pd.read_csv('Strata Questions/historical_data.csv')
df.head(3)
except FileNotFoundError as e:
import os
print("File not found. Here's where Python is looking:")
print("Working directory:", os.getcwd())
print("Available files:", os.listdir())
raise e
Voici la sortie.
Vous ne soulevez pas seulement une erreur – vous l’interrogez-vous. Cela montre où le code pense qu’il est et ce qu’il voit autour de lui. Si votre fichier n’est pas sur la liste, vous le savez maintenant. Pas de devinettes. Juste des faits.
Remplacez le chemin par le plein et voilà!
Cas 2: DTYPE MISION CONTRÉTATION – Python est silencieusement erroné devine
Vous chargez l’ensemble de données, mais quelque chose est éteint. Le bogue se cache à l’intérieur de vos types.
# Assuming df is your loaded DataFrame
try:
print("Column Types:n", df.dtypes)
except Exception as e:
print("Error reading dtypes:", e)
Voici la sortie.
Cas 3: Parsing Date – Le saboteur silencieux
Nous avons découvert que nous devons d’abord calculer la durée de livraison et nous l’avons fait avec cette méthode.
try:
# This code was shown earlier to calculate the delivery duration
df("created_at") = pd.to_datetime(df('created_at'))
df("actual_delivery_time") = pd.to_datetime(df('actual_delivery_time'))
df("actual_total_delivery_duration") = (df("actual_delivery_time") - df("created_at")).dt.total_seconds()
print("Successfully calculated delivery duration and checked dtypes.")
print("Relevant dtypes:n", df(('created_at', 'actual_delivery_time', 'actual_total_delivery_duration')).dtypes)
except Exception as e:
print("Error during date processing:", e)
Voici la sortie.
Bon et professionnel! Maintenant, nous évitons ces erreurs rouges, ce qui soulèvera notre humeur – je sais que les voir peut atténuer votre motivation.
Gestion des données manquantes: KeyErrors, NaNset les pièges logiques
Certains bogues ne plantent pas votre code. Ils vous donnent simplement les mauvais résultats, silencieusement, jusqu’à ce que vous vous demandiez pourquoi votre modèle est des ordures.
Cette section creuse dans les données manquantes – pas juste comment les nettoyer, mais comment les déboguer correctement.
Cas 1: Keyerror – vous pensiez que la colonne existait
Voici notre code.
try:
print(df('store_rating'))
except KeyError as e:
print("Column not found:", e)
print("Here are the available columns:n", df.columns.tolist())
Voici la sortie.
Le code ne s’est pas cassé à cause de la logique; Il a brisé à cause d’une hypothèse. C’est précisément là que le débogage vit. Énumérez toujours vos colonnes avant d’y accéder aveuglément.
Cas 2: Nan Count – Valeurs manquantes auxquelles vous ne vous attendiez pas
Vous supposez que tout est propre. Mais les données réelles cachent toujours les lacunes. Vérifions-les.
try:
null_counts = df.isnull().sum()
print("Nulls per column:n", null_counts(null_counts > 0))
except Exception as e:
print("Failed to inspect nulls:", e)
Voici la sortie.
Cela expose les fauteurs de troubles silencieux. Peut être store_primary_category manque dans des milliers de lignes. Peut-être que les horodatages ont échoué la conversion et sont maintenant NaT.
Vous ne l’auriez pas connu à moins que vous ne vérifiiez. Débogage – confirmant chaque hypothèse.
Cas 3: Pièges logiques – données manquantes qui ne manquent pas réellement
Disons que vous essayez de filtrer les ordres où le sous-total est supérieur à 1 000 000, attendant des centaines de lignes. Mais cela vous donne zéro:
try:
filtered = df(df('subtotal') > 1000000)
print("Rows with subtotal > 1,000,000:", filtered.shape(0))
except Exception as e:
print("Filtering error:", e)
Ce n’est pas une erreur de code – c’est une erreur logique. Vous vous attendiez à des ordres de grande valeur, mais peut-être aucun n’existe au-dessus de ce seuil. Déboguez-le avec une vérification de la plage:
print("Subtotal range:", df('subtotal').min(), "to", df('subtotal').max())
Voici la sortie.
Cas 4: isna() ≠ zéro ne signifie pas que c’est propre
Même si isna().sum() Affiche zéro, il peut y avoir des données sales, comme Whitespace ou «Aucun» en tant que chaîne. Exécutez un chèque plus agressif:
try:
fake_nulls = df(df('store_primary_category').isin(('', ' ', 'None', None)))
print("Rows with fake missing categories:", fake_nulls.shape(0))
except Exception as e:
print("Fake missing value check failed:", e)
Cela attrape des poubelles cachées isnull() manques.
Caractéristiques des problèmes d’ingénierie: TypeErrorsAnalyse de datte, et plus
L’ingénierie des fonctionnalités semble amusante au début, jusqu’à ce que votre nouvelle colonne casse chaque modèle ou lance un TypeError mi-pipeline. Voici comment déboguer cette phase comme quelqu’un qui a été brûlé auparavant.
Cas 1: Vous pensez que vous pouvez diviser, mais vous ne pouvez pas
Créons une nouvelle fonctionnalité. Si une erreur se produit, notre try-except Block l’attrapera.
try:
df('value_per_item') = df('subtotal') / df('total_items')
print("value_per_item created successfully")
except Exception as e:
print("Error occurred:", e)
Voici la sortie.
Pas d’erreurs? Bien. Mais regardons de plus près.
print(df(('subtotal', 'total_items', 'value_per_item')).sample(3))
Voici la sortie.
Cas 2: La date d’analyse a mal tourné
Maintenant, changez votre dtype est important, mais que se passe-t-il si vous pensez que tout a été fait correctement, mais les problèmes persistent?
# This is the standard way, but it can fail silently on mixed types
df("created_at") = pd.to_datetime(df("created_at"))
df("actual_delivery_time") = pd.to_datetime(df("actual_delivery_time"))
Vous pourriez penser que tout va bien, mais si votre colonne a des types mixtes, il pourrait échouer en silence ou casser votre pipeline. C’est pourquoi, au lieu de faire directement des transformations, il est préférable d’utiliser une fonction robuste.
from datetime import datetime
def parse_date_debug(df, col):
try:
parsed = pd.to_datetime(df(col))
print(f"(SUCCESS) '{col}' parsed successfully.")
return parsed
except Exception as e:
print(f"(ERROR) Failed to parse '{col}':", e)
# Find non-date-like values to debug
non_datetimes = df(pd.to_datetime(df(col), errors="coerce").isna())(col).unique()
print("Sample values causing issue:", non_datetimes(:5))
raise
df("created_at") = parse_date_debug(df, "created_at")
df("actual_delivery_time") = parse_date_debug(df, "actual_delivery_time")
Voici la sortie.
Cela vous aide à tracer des lignes défectueuses lorsque DateTime Analyse se bloque.
Cas 3: Division naïve qui pourrait induire en erreur
Cela ne lancera pas une erreur dans notre DataFrame car les colonnes sont déjà numériques. Mais voici le problème: certains ensembles de données se faufilent dans les types d’objets, même lorsqu’ils ressemblent à des chiffres. Cela mène à:
- Ratios trompeurs
- Mauvais comportement du modèle
- Aucune avertissement
df("busy_dashers_ratio") = df("total_busy_dashers") / df("total_onshift_dashers")
Valissons les types avant de calculer, même si l’opération ne lancera pas une erreur.
import numpy as np
def create_ratio_debug(df, num_col, denom_col, new_col):
num_type = df(num_col).dtype
denom_type = df(denom_col).dtype
if not np.issubdtype(num_type, np.number) or not np.issubdtype(denom_type, np.number):
print(f"(TYPE WARNING) '{num_col}' or '{denom_col}' is not numeric.")
print(f"{num_col}: {num_type}, {denom_col}: {denom_type}")
df(new_col) = np.nan
return df
if (df(denom_col) == 0).any():
print(f"(DIVISION WARNING) '{denom_col}' contains zeros.")
df(new_col) = df(num_col) / df(denom_col)
return df
df = create_ratio_debug(df, "total_busy_dashers", "total_onshift_dashers", "busy_dashers_ratio")
Voici la sortie.
Cela donne une visibilité sur les problèmes potentiels de division par zéro et empêche les bogues silencieux.
Modélisation des erreurs: inadéquation de forme et confusion d’évaluation
Cas 1: les valeurs NAN dans les fonctionnalités provoquent un plan du modèle
Disons que nous voulons construire un modèle de régression linéaire. LinearRegression() ne prend pas en charge les valeurs NAN nativement. Si une ligne dans X a une valeur manquante, le modèle refuse de s’entraîner.
Voici le code, qui crée délibérément un décalage de forme pour déclencher une erreur:
from sklearn.linear_model import LinearRegression
X_train = df(("estimated_order_place_duration", "estimated_store_to_consumer_driving_duration")).iloc(:-10)
y_train = df("actual_total_delivery_duration").iloc(:-5)
model = LinearRegression()
model.fit(X_train, y_train)
Voici la sortie.
Déboglons cette question. Tout d’abord, nous vérifions NANS.
print(X_train.isna().sum())
Voici la sortie.
Bon, vérifions également l’autre variable.
print(y_train.isna().sum())
Voici la sortie.
Les valeurs de décalage et de NAN doivent être résolues. Voici le code pour le réparer.
from sklearn.linear_model import LinearRegression
# Re-align X and y to have the same length
X = df(("estimated_order_place_duration", "estimated_store_to_consumer_driving_duration"))
y = df("actual_total_delivery_duration")
# Step 1: Drop rows with NaN in features (X)
valid_X = X.dropna()
# Step 2: Align y to match the remaining indices of X
y_aligned = y.loc(valid_X.index)
# Step 3: Find indices where y is not NaN
valid_idx = y_aligned.dropna().index
# Step 4: Create final clean datasets
X_clean = valid_X.loc(valid_idx)
y_clean = y_aligned.loc(valid_idx)
model = LinearRegression()
model.fit(X_clean, y_clean)
print("✅ Model trained successfully!")
Et voilà! Voici la sortie.
Cas 2: Colonnes d’objet (dates) Crasser le modèle
Disons que vous essayez de former un modèle à l’aide d’un horodatage comme actual_delivery_time.
Mais – oh non – c’est toujours un type objet ou DateTime, et vous le mélangez accidentellement avec des colonnes numériques. La régression linéaire n’aime pas cela un peu.
from sklearn.linear_model import LinearRegression
X = df(("actual_delivery_time", "estimated_order_place_duration"))
y = df("actual_total_delivery_duration")
model = LinearRegression()
model.fit(X, y)
Voici le code d’erreur:
Vous combinez deux types de données incompatibles dans la matrice X:
- Une colonne (
actual_delivery_time) estdatetime64. - L’autre (
estimated_order_place_duration) estint64.
Scikit-Learn s’attend à ce que toutes les fonctionnalités soient la même DTYPE numérique. Il ne peut pas gérer les types mixtes comme DateTime et Int. Résolvons-le en convertissant la colonne DateTime en une représentation numérique (horodatage UNIX).
# Ensure datetime columns are parsed correctly, coercing errors to NaT
df("actual_delivery_time") = pd.to_datetime(df("actual_delivery_time"), errors="coerce")
df("created_at") = pd.to_datetime(df("created_at"), errors="coerce")
# Recalculate duration in case of new NaNs
df("actual_total_delivery_duration") = (df("actual_delivery_time") - df("created_at")).dt.total_seconds()
# Convert datetime to a numeric feature (Unix timestamp in seconds)
df("delivery_time_timestamp") = df("actual_delivery_time").astype("int64") // 10**9
Bien. Maintenant que les DTypes sont numériques, appliquons le modèle ML.
from sklearn.linear_model import LinearRegression
# Use the new numeric timestamp feature
X = df(("delivery_time_timestamp", "estimated_order_place_duration"))
y = df("actual_total_delivery_duration")
# Drop any remaining NaNs from our feature set and target
X_clean = X.dropna()
y_clean = y.loc(X_clean.index).dropna()
X_clean = X_clean.loc(y_clean.index)
model = LinearRegression()
model.fit(X_clean, y_clean)
print("✅ Model trained successfully!")
Voici la sortie.
Excellent travail!
Réflexions finales: déboguez plus intelligemment, pas plus difficile
Les accidents du modèle ne découlent pas toujours de bogues complexes – parfois, c’est juste une nan errante ou une colonne de date non convertie se faufilant dans votre pipeline de données.
Plutôt que de lutter avec des traces de pile cryptique ou de lancer try-except Des blocs comme les fléchettes dans l’obscurité, creusez dans votre dataframe tôt. Jeter un coup d’œil .info()vérifier .isna().sum()et ne pas hésiter à .dtypes. Ces étapes simples dévoilent les mines terrestres cachées avant même de frapper fit().
Je vous ai montré que même un type d’objet négligé ou une valeur manquante sournoise peut saboter un modèle. Mais avec un œil plus net, une préparation plus propre et une extraction des caractéristiques intentionnelles, vous passez du débogage de manière réactive à la construction intelligente.
Nate Rosidi est un scientifique des données et en stratégie de produit. Il est également professeur auxiliaire qui enseigne l’analyse et est le fondateur de Stratascratch, une plate-forme aidant les scientifiques des données à se préparer à leurs entretiens avec de véritables questions d’entrevue de grandes entreprises. Nate écrit sur les dernières tendances du marché de la carrière, donne des conseils d’entrevue, partage des projets de science des données et couvre tout SQL.
Source link



