
L’apprentissage automatique peut-il prédire la qualité de l’air avant qu’elle ne devienne dangereuse?
- Intelligence Artificielle
 Noesis News
Noesis News- 0
- 22 minutes de lecture

Auteur (s): S Aishwarya
Publié à l’origine sur Vers l’IA.
L’apprentissage automatique peut-il prédire la qualité de l’air avant qu’elle ne devienne dangereuse?
Ces dernières années, la pollution atmosphérique est passée d’un problème environnemental abstrait à une réalité quotidienne pour des millions à travers le monde. Des villes remplies de smog aux avis alarmants en santé, la mauvaise qualité de l’air affecte la façon dont nous vivons, respirons et bougeons.
Mais que se passe-t-il si nous pouvions le voir venir?
Et si nous pouvions prédire l’indice de qualité de l’air de demain (AQI) tout comme nous prédisons la météo – et agissons avant l’air devient toxique?
C’est là que apprentissage automatique Étape.
🌍 Pourquoi devrions-nous prédire la qualité de l’air?
La pollution atmosphérique n’est pas seulement un inconvénient – c’est une crise de santé. Selon l’OMS, c’est responsable de presque 7 millions de décès prématurés chaque année. Des niveaux élevés d’AQI sont associés aux crises d’asthme, aux maladies respiratoires, aux problèmes cardiovasculaires et même au déclin cognitif.
Si nous pouvons prédire AQI avec précision:
- 🚨 Les communautés peuvent recevoir des avertissements précoces.
- 🏙️ Les planificateurs urbains peuvent concevoir des villes plus intelligentes et plus propres.
- 🧍️ Les individus peuvent décider quand il est sûr d’aller faire du jogging ou d’envoyer des enfants jouer à l’extérieur.
Ainsi, la question à un million de dollars est:
Peut apprentissage automatique Aidez-nous à prédire la qualité de l’air à temps pour protéger notre santé?
Découvons.
Présentation de l’ensemble de données
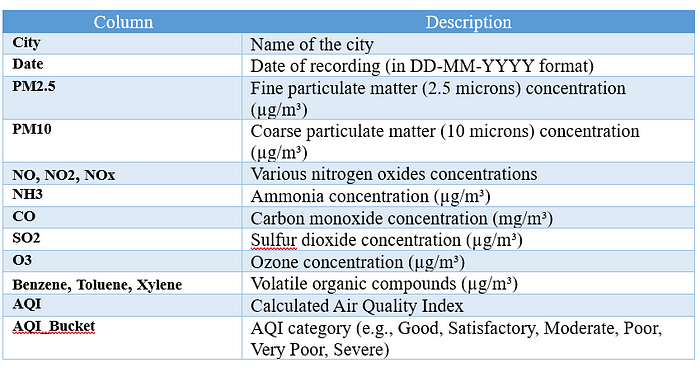
🌫️ Données de qualité de l’air en Inde (2015-2020)
📌 Lien: Ensemble de données
📝 Présentation
Ce ensemble de données contient Données quotidiennes de qualité de l’air des grandes villes de l’Inde, collectées entre 2015 et 2020. Il comprend des concentrations de divers polluants, des paramètres météorologiques et des valeurs AQI calculées.
📁 Fichiers inclus
city_day.csv: Données quotidiennes de qualité de l’air par villestation_day.csv: Données quotidiennes de qualité de l’air par stationstations.csv: Métadonnées pour chaque station de surveillance
Nous allons utiliser City_day.csv
Chaque ligne de ce fichier correspond à un Données d’une seule journée de qualité de l’air pour une ville spécifique.
Absolument! Voici une réécriture plus engageante et humaine de l’article avec une ambiance de narration – parfait pour les articles de blog ou les plateformes comme Medium ou Geeksforgeeks:
🧠 Notre approche: Classical ML vs Ensemble Learning
Voyons un flux de travail ML complet en utilisant Python pour prévoir AQI, en comparant deux modèles: Régression linéaire et Forêt aléatoire Régresseur.
🔹 Régression linéaire – Simple, rapide et interprétable.
🔹 Forêt aléatoire Régresseur – puissant, robuste et précis.
Étape 1: Chargement des données
Nous utilisons le Qualité de l’air en Inde ensemble de données De Kaggle, qui suit les niveaux de polluants et les valeurs AQI dans les villes indiennes de 2015 à 2020.
import pandas as pd
df = pd.read_csv("/content/city_day.csv")
Cet ensemble de données comprend des mesures pour PM2,5, PM10, NO₂, CO et d’autres polluants majeurs – en gros, ce qui flotte dans les airs dans les airs.
🧹 Étape 2: nettoyer les choses
Comme la plupart des données réelles, celle-ci est un peu désordonnée. Alors, rangeons-le:
df = df.dropna(subset=('AQI')) # Drop rows with missing target
df('Date') = pd.to_datetime(df('Date'), dayfirst=True)
df.fillna(df.median(numeric_only=True), inplace=True)
df = df.drop(columns=('Date', 'City', 'AQI_Bucket'))
Laissement des valeurs AQI manquantes
Combler les lacunes avec des médianes de colonne
Suppression des colonnes que nous n’utiliserons pas (comme les noms de la ville ou les catégories)
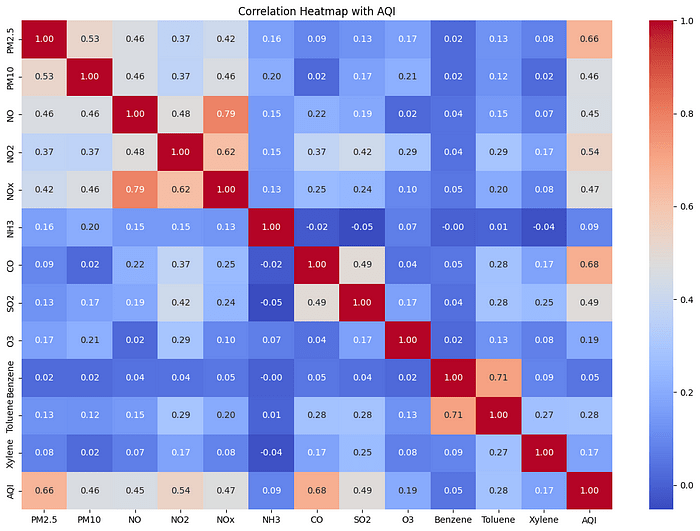
🔍 Étape 3: trouver ce qui affecte vraiment AQI
Il est maintenant temps d’explorer – qu’est-ce qui influence réellement la qualité de l’air?
import seaborn as sns
import matplotlib.pyplot as plt
correlation_matrix = df.corr()
plt.figure(figsize=(15, 10))
sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm', fmt=".2f")
plt.title("Correlation Heatmap with AQI")
plt.show()
🧪 Alerte de spoiler: PM2.5, PM10, NO₂, NO, CO – Ce sont quelques-uns des plus grands fauteurs de troubles.
🎯 Étape 4: Sélection des fonctionnalités
Nous nous concentrerons sur les polluants supérieurs qui ont un haut corrélation avec aqi.
selected_features = ('CO', 'PM2.5', 'NO2', 'SO2', 'NOx', 'PM10', 'NO')
X = df(selected_features)
y = df('AQI')
Cela aide à garder le modèle maigre et concentré.
🧪 Étape 5: Train-test divisé et échelle
Préplions nos données pour les modèles ML:
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
🔄 Nous avons divisé nos données en ensembles de formation et de test
📏 Nous adaptons les fonctionnalités afin que des modèles comme la régression linéaire ne soient pas confus par de grands nombres
🤖 Étape 6: Il est temps de former nos modèles!
Voyons ce que nos deux modèles peuvent faire.
from sklearn.linear_model import LinearRegression
from sklearn.ensemble import RandomForestRegressor
lr = LinearRegression()
lr.fit(X_train_scaled, y_train)
lr_preds = lr.predict(X_test_scaled)
rf = RandomForestRegressor(n_estimators=100, random_state=42)
rf.fit(X_train, y_train)
rf_preds = rf.predict(X_test)
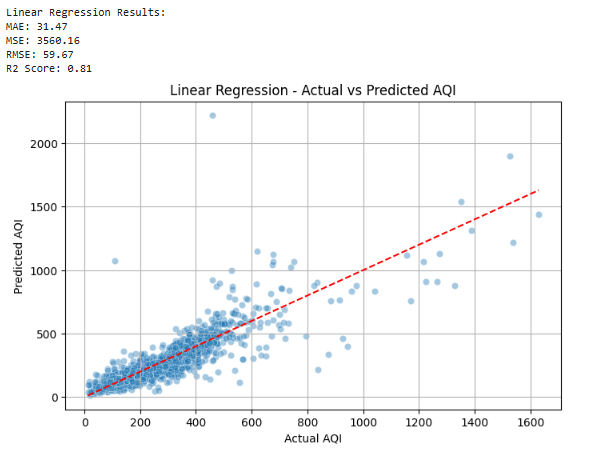
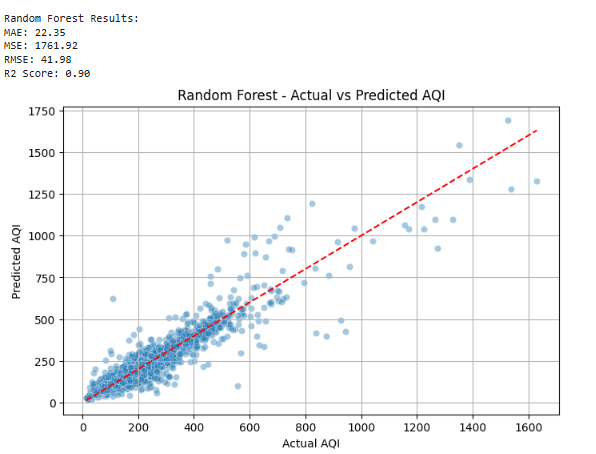
📊 Étape 7: Dans quelle mesure ils ont-ils bien fait?
Mesurer à quel point les prédictions sont proches des valeurs AQI réelles.
from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score
import numpy as np
def evaluate_model(name, y_true, y_pred):
print(f"n{name} Results:")
print(f"MAE: {mean_absolute_error(y_true, y_pred):.2f}")
mse = mean_squared_error(y_true, y_pred)
print(f"MSE: {mse:.2f}")
print(f"RMSE: {np.sqrt(mse):.2f}")
print(f"R2 Score: {r2_score(y_true, y_pred):.2f}")plt.figure(figsize=(8, 5))
sns.scatterplot(x=y_true, y=y_pred, alpha=0.4)
plt.plot((y_true.min(), y_true.max()), (y_true.min(), y_true.max()), 'r--')
plt.xlabel("Actual AQI")
plt.ylabel("Predicted AQI")
plt.title(f"{name} - Actual vs Predicted AQI")
plt.grid(True)
plt.show()
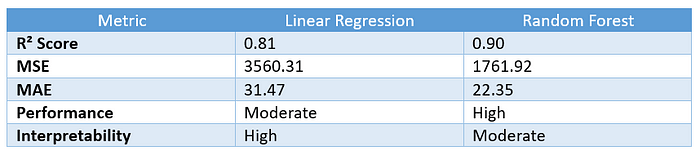
evaluate_model("Linear Regression", y_test, lr_preds)
evaluate_model("Random Forest", y_test, rf_preds)
Analyse comparative: régression linéaire vs forêt aléatoire
⚖️ Quand utiliser quoi?
Choisissez une régression linéaire si:
- Vous voulez des résultats interprétables
- Votre ensemble de données est petit ou propre
- Vous voulez un modèle rapide et léger
Choisissez une forêt aléatoire si:
- Vous avez besoin d’une grande précision
- Vos données ont des relations non linéaires
- Vous êtes d’accord avec une approche de boîte noire
💡 Réflexions finales
L’apprentissage automatique ne concerne pas seulement les chiffres sur un écran – il s’agit de déverrouiller les informations qui peuvent changer de vie.
En exploitant les données environnementales, nous ne prédisons pas seulement la qualité de l’air – nous permettons aux gens d’agir avant qu’il ne devienne dangereux. Que ce soit pour aider les parents à décider s’il est sûr pour leurs enfants de jouer à l’extérieur ou d’aider les planificateurs de la ville pour réduire les points chauds de pollution, chaque aperçu nous rapproche des communautés plus saines.
Des modèles simples et transparents comme la régression linéaire aux forêts aléatoires hautement performantes, nous avons vu comment différents algorithmes peuvent répondre à différents besoins. Mais à la fin, l’objectif est le même:
De meilleures données → Décisions plus intelligentes → Air plus propre.
Alors que nous regardons vers l’avenir, imaginez la combinaison avec des flux de capteurs en temps réel, des données satellites ou des prévisions météorologiques. Les possibilités sont vastes – et ils commencent par des projets comme celui-ci.
Continuons à innover – une prédiction, une respiration et une ligne de code à la fois. 🌿💻🌍
Publié via Vers l’IA
Source link



