
Lama 4 sent mal – Fastml
- Intelligence Artificielle
 Noesis News
Noesis News- 0
- 14 minutes de lecture


Meta s’est distinguée positivement en libérant trois générations de lama, un LLM semi-ouvert avec des poids disponibles si vous demandez bien (et fournissez votre nom juridique complet, votre date de naissance et votre nom d’organisation complet avec tous les identificateurs d’entreprise). Donc non, ce n’est pas open source. Quoi qu’il en soit, samedi (!) Le 5 mai, Cinco de Mayo, Meta a sorti Llama 4.
Ceci est un projet. Revenez plus tard pour la version finale.
Source: https://x.com/burkov/status/190908837554291049
Arena LM
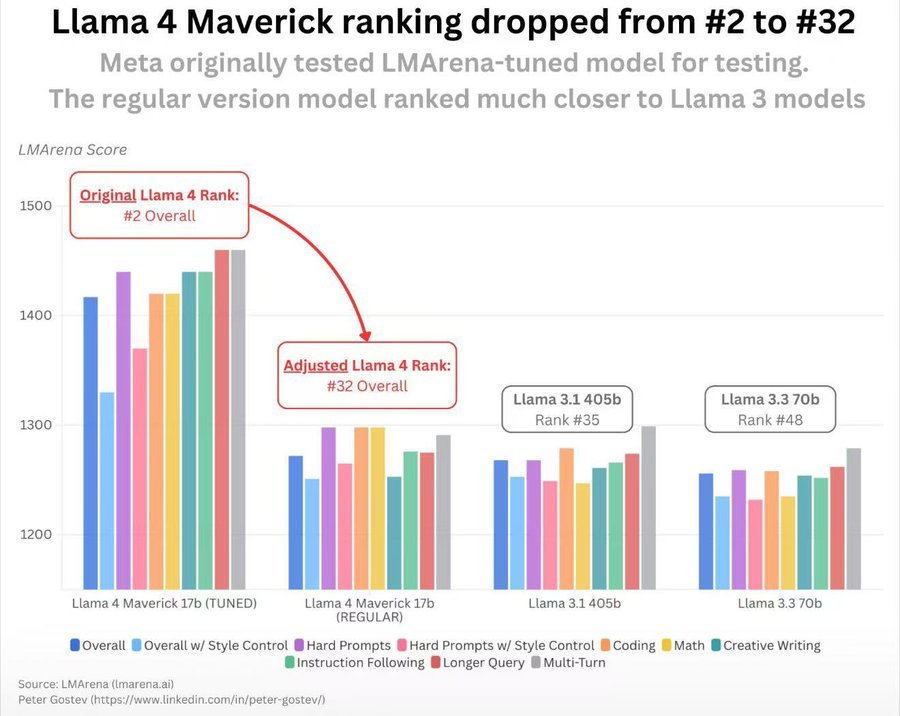
Comme il est devenu une pratique standard, méta a testé le modèle de manière anonyme sur Arena LM Avant la libération. Le modèle s’est retrouvé deuxième dans le classement, ce qui est génial, et c’est là que la controverse commence.
LM Arena est la référence en ligne la plus populaire, et ils publient certaines conversations ainsi que leurs préférences des utilisateurs associés. Ces deux faits signifient que les entreprises sont disposées et capables de sur-adapter la référence. Si vous regardez le classement, environ la moitié des modèles sont marqués comme «expérimentaux», «prévisualisation» ou quelque chose comme ça. Cela pourrait bien signifier que ce que vous utilisez normalement n’est pas ce que vous obtenez sur LM Arena. Les gens ne prêtent généralement pas beaucoup d’attention à cela lorsqu’un modèle livre. Llama 4 est exceptionnel en ce qu’il ne livre pas.
Soit dit en passant, cela ne veut pas dire que le Llama 4 «expérimental» est bon. C’est juste jappeur, Explique QKV dans les transformateurs à travers des réunions de familleet aussi halluner.
Des erreurs se produisent
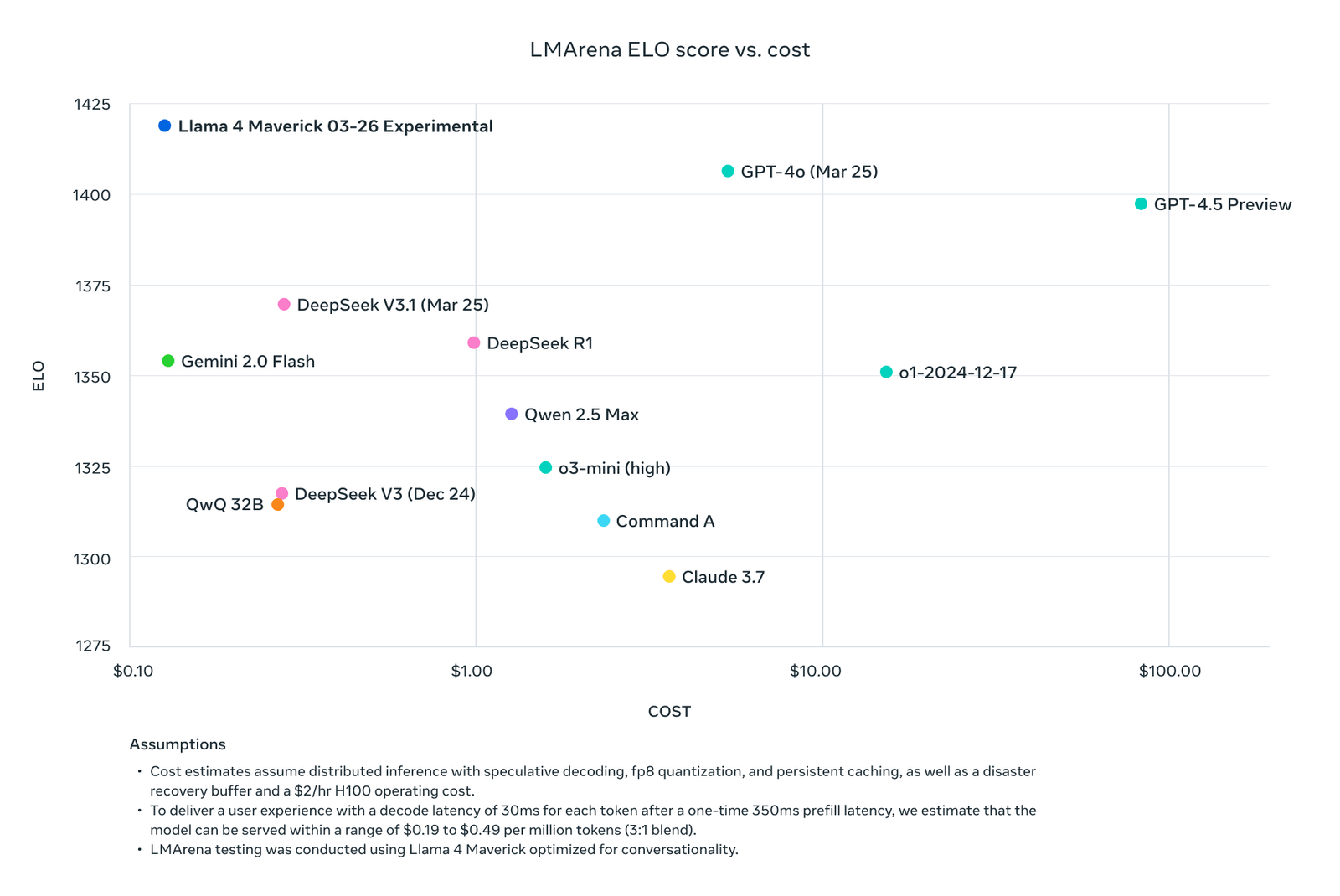
À la sortie, Meta a publié un tableau de diverses performances de modèle par rapport aux prix, avec LLAMA au-dessus. Ils ont cependant oublié de mettre Gemini 2.5 sur le graphique. Ils ont probablement manqué de l’espace vertical et Gemini 2.5 ne convenait tout simplement pas, étant à environ 20 points au-dessus de Llama. Des erreurs honnêtes comme celle-ci se produisent, honnêtement, même pour des gens honnêtes, vous savez.
Source: https://x.com/aiatmeta/status/1908618302676697317
Ongle précoce dans le cercueil
Le 8 avril, LM Arena tweeté ce:
L’interprétation de Meta de notre politique ne correspondait pas à ce que nous attendons des fournisseurs de modèles. Meta aurait dû être plus clair que «Llama-4-Maverick-03-26-Experimental» était un modèle personnalisé pour optimiser la préférence humaine. À la suite de cela, nous mettons à jour nos politiques de classement pour renforcer notre engagement envers les évaluations réduites et reproductibles afin que cette confusion ne se produise pas à l’avenir.
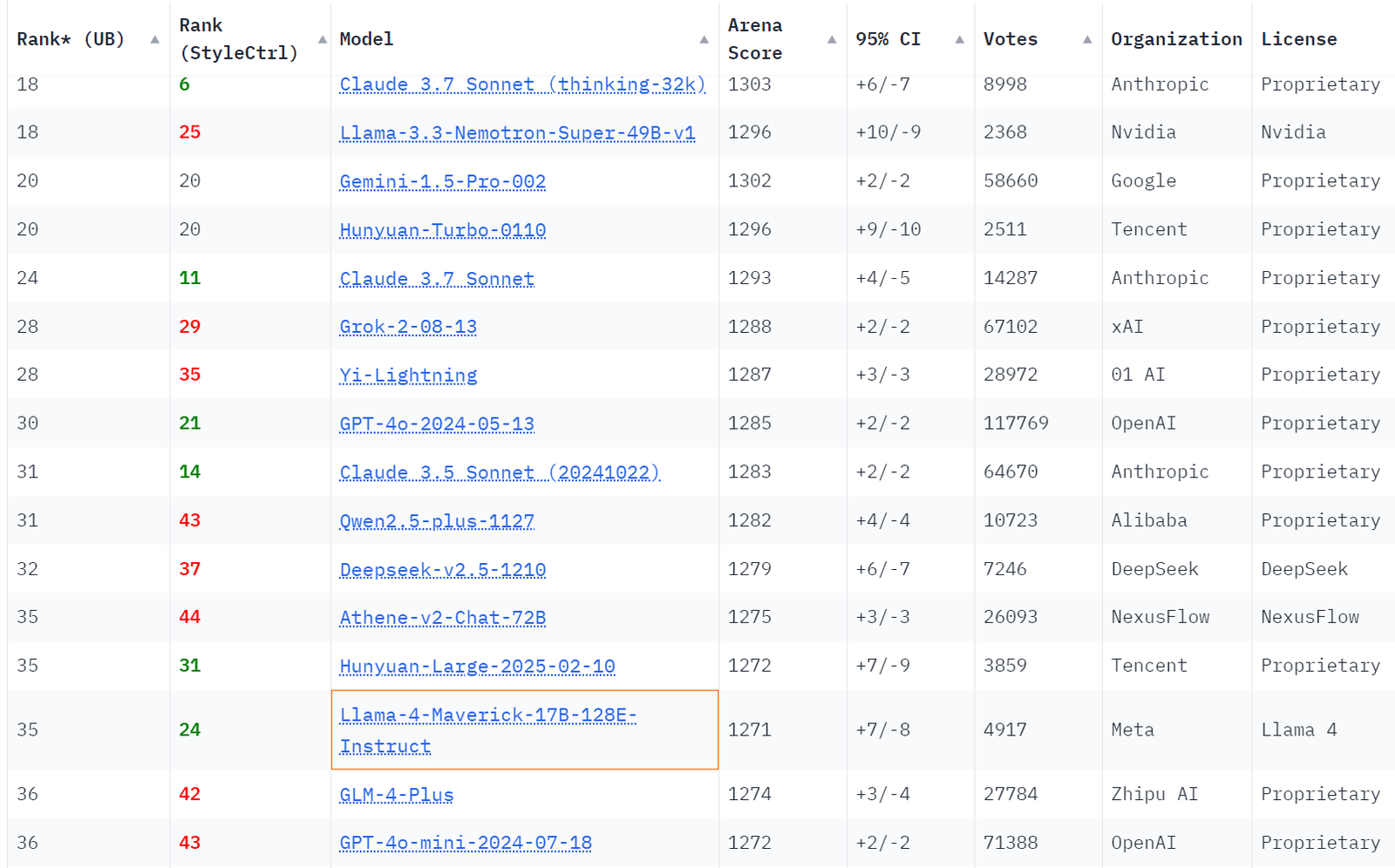
Autrement dit, Meta a tellement triché qu’il devait être officiellement giflé. Le «vrai» franc-tireur, 400B de taille, s’est retrouvé juste derrière Athene et Hunyan, les modèles dont personne n’a jamais entendu parler, et juste devant GPT-4O-MINI, qui est, selon lui, un modèle avec des paramètres de 1,3b ou 1,5b ou 1,7b, selon lorsque vous demandez.
Source: https://x.com/kalomaze/status/1911846553435967646
Mélange d’experts
Llama 4 est disponible en trois versions: Scout, Maverick et non encore libéré. Pourquoi ces noms au lieu de simplement llama 4 109b / 400b / 2t? Apparemment, Meta n’est pas trop fière de ces dénombrements de paramètres, ni peut-être de la performance par rapport à la taille, et tout simplement réside sur des étreintes:
Nous lançons deux modèles efficaces dans la série LLAMA 4, LLAMA 4 Scout, un modèle de paramètres de 17 milliards avec 16 experts, et Llama 4 Maverick, un modèle de paramètres de 17 milliards avec 128 experts.
Imaginez la formidable surprise que les visiteurs sans méfiance éprouvent lorsqu’ils vont au Llama-4-Maverick-17b-128e-Istruct Répu et voir 55 fichiers de pièce du modèle, la plupart d’entre eux 21,5 Go ou 10,7 Go. Bizarre!
En réalité, Maverick a 400B paramètres, 17B activés à tout moment.
Cela vient du fait que LLAMA 4, contrairement aux versions précédentes, est un modèle d’experts (MOE). Les modèles MOE n’utilisent qu’une partie des paramètres pendant l’inférence. Pour autant que nous comprenons, le MOE est à la fois théoriquement et pratiquement meilleur que les modèles denses. Le meilleur modèle open source, Deepseek V3 / R1 est également MOE. Deepseek, cependant, ne prétend pas que le modèle 685B soit un modèle 37B.
Mémoire vs moe et contexte long
En pratique, les modèles MOE fonctionnent plus rapidement à l’inférence, mais tous les paramètres doivent encore être dans la mémoire GPU. Vous savez ce qui doit être en mémoire? Contexte.
Llama 4 a une longueur de contexte impressionnante de 10m, dépassant théoriquement Google Gemini, qui dirigeait dans ce département. Cependant, il y a deux problèmes. La première est que le contexte doit s’adapter dans la mémoire, avec le modèle, et les fournisseurs d’API ne permettent pas un contexte aussi long pour des raisons pratiques.
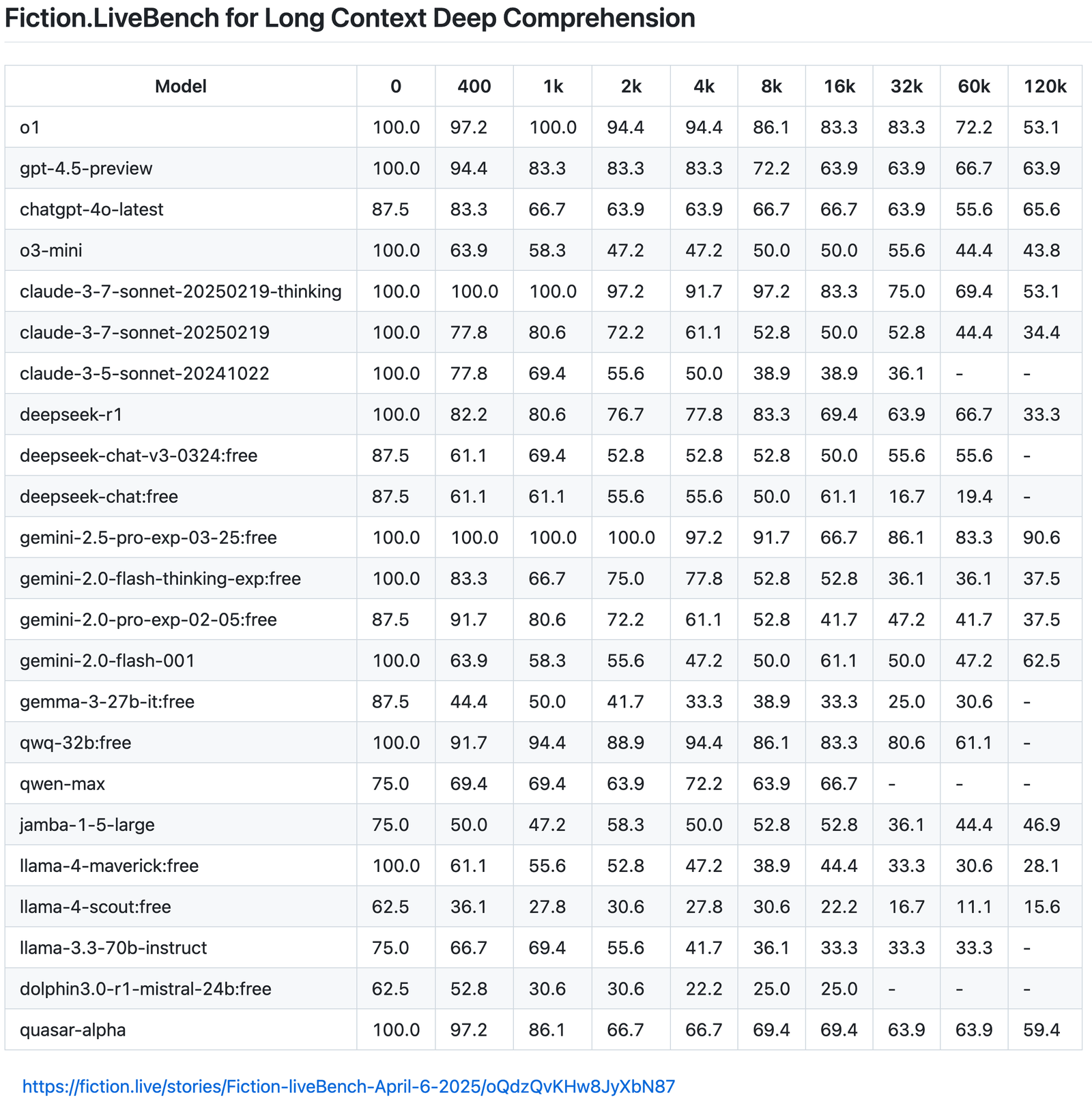
Un autre est que ce n’est pas parce qu’un modèle a un contexte long qu’il sera en mesure de l’utiliser efficacement. Une autre référence précoce suggère en effet que Llama 4 est remarquablement mauvais dans le traitement des contextes longs.
Source: https://fiction.live/stories/fiction-livebench-mar-25-2025/oqdzqvkhw8jyxbn87
Plus de repères
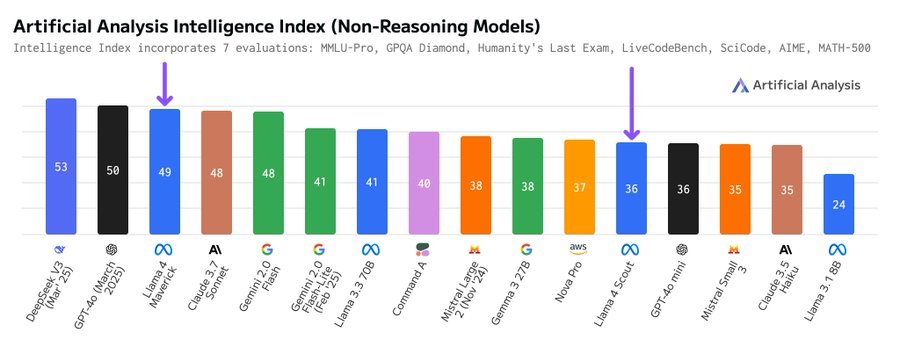
Sur l’analyse artificielle, le scout de référence a obtenu le même score que GPT 4O Mini. Un modèle 109b vs un modèle 1,5b (prétendument). C’est épouvantable. C’est gênant.
Source: https://x.com/artificialanlys/status/1908890796415414430
L’analyse artificielle a ensuite ajusté le format rapide et les modèles LLAMA 4 ont mieux obtenu un score.
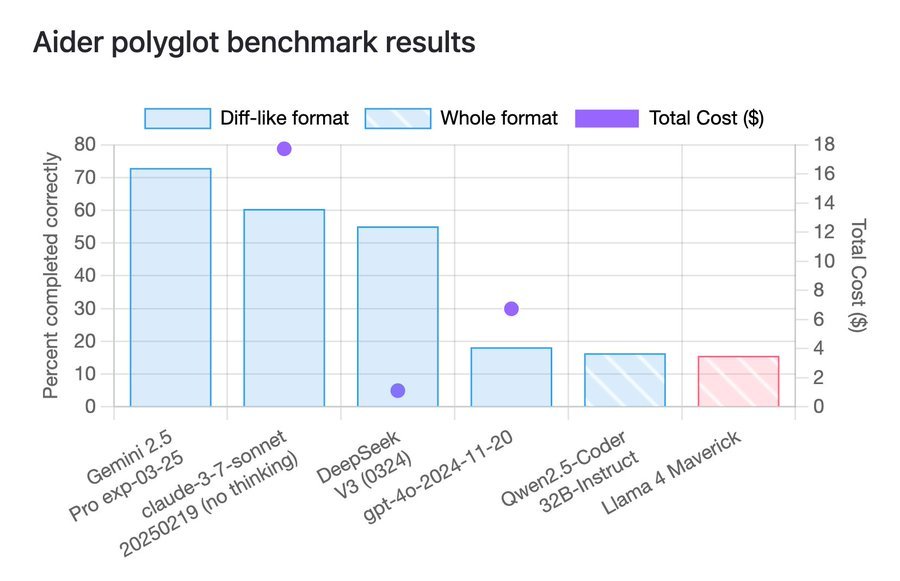
Sur la référence codante d’Aider, Maverick marque à peu près le même que Qwen 2.5 Coder 32B, un modèle dense relativement ancien inférieur à une dixième taille de franc-tireur.
Source: https://x.com/paulgauthier/status/1908976568879476843
Personnes
Quelqu’un sur reddit affiché ce (audacier le nôtre):
Malgré les efforts de formation répétés, les performances du modèle interne ne sont toujours pas en mesure de repères Sota open source, à la traîne de manière significative. Le leadership de l’entreprise a suggéré des ensembles de tests de mélange de divers repères pendant le processus de formation post-entraînementvisant à atteindre les cibles dans diverses mesures et à produire un résultat «présentable». L’absence de cet objectif d’ici la date limite de fin de avril entraînerait des conséquences désastreuses. Après la sortie d’hier de Llama 4, de nombreux utilisateurs sur X et Reddit ont déjà rapporté des résultats de tests réelles extrêmement médiocres.
En tant que personne actuellement dans le monde universitaire, je trouve cette approche totalement inacceptable. Par conséquent, j’ai soumis ma démission et j’ai explicitement demandé que mon nom soit exclu du rapport technique de Llama 4. Notamment, le vice-président de l’IA à Meta a également démissionné pour des raisons similaires.
Nous ne savons pas si c’est vrai. C’est peut-être un appât. Cependant, le vice-président de l’IA à Meta, Joelle Pineau, a en effet démissionné. Elle a annoncé son départ le 1er avril, déclarant que son dernier jour avec la société serait le 30 mai 2025. Pineau était avec Meta depuis près de huit ans, menant le groupe fondamental de recherche sur l’IA (FAIR) depuis 2023.
Source: https://x.com/davidsholz/status/1908603882118537709
Il y aura probablement Llama 5. Espérons que ce sera mieux que Llama 4.
Source link



