
La technologie Shengshu lance le modèle de formation physique multi-visualités Vidar
- Intelligence Artificielle
 Noesis News
Noesis News- 0
- 12 minutes de lecture




Le modèle IA incarné Vidar de Shengshu utilise des mondes simulés au lieu des données d’entraînement physique. Source: Adobe Stock, VectorHub by Ice
Shengshu Technology Co. a lancé hier son modèle de formation physique multi-visualités, Vidar – qui signifie «diffusion vidéo pour le raisonnement d’action». En utilisant les capacités de Vidu dans la compréhension sémantique et vidéo, Vidar utilise un ensemble limité de données physiques pour simuler la prise de décision d’un robot dans des environnements réels, a déclaré la société.
«Vidar offre une approche radicalement différente de la formation des modèles d’intelligence artificielle», a déclaré la technologie Shengshu. «Tout comme Tesla se concentre sur la formation basée sur la vision et Waymo se penche sur Lidar, l’industrie explore les chemins divergents vers l’IA physique.»
Fondée en mars 2023, Shengshu Technology est spécialisée dans le développement de modèles multimodaux en grande langue (LLMS). La société basée à Pékin a déclaré qu’elle livrait la mobilité en tant que service (MAAS) et les produits logiciels en tant que service (SaaS) pour la création de contenu plus intelligente, plus rapide et plus évolutive.
Avec sa plate-forme de génération vidéo phare ViduShengshu a déclaré avoir atteint les utilisateurs dans plus de 200 pays et régions du monde, couvrant des champs, notamment le divertissement interactif, la publicité, le cinéma, l’animation, le tourisme culturel, etc.
VIDAR Simulate Formation pour accélérer le développement des robots
«Alors que certaines entreprises forment IA En incorporant des modèles dans des robots du monde réel et en collectant des données à travers les interactions physiques que leurs robots rencontrent, c’est une méthode coûteuse, dépendante du matériel et difficile à évoluer », a déclaré la technologie Shengshu.« D’autres s’appuient sur une formation purement simulée, mais cela manque souvent de variabilité et de données de rasage vers le bas pour le travail réel. »
Vidar adopte une approche différente, a affirmé la société. Il combine des données d’entraînement physique limitées avec une vidéo générative pour faire des prédictions et générer de nouveaux scénarios hypothétiques, créant une multi-visualités simulation Avec des environnements d’entraînement réalistes, le tout dans un espace virtuel. Cela permet une formation plus robuste et évolutive sans temps, coût ou limitation de la collecte de données du monde physique, a expliqué Shengshu.
Construit au-dessus du modèle vidéo génératif de Vidu, Vidar peut effectuer des tâches de manipulation à double bras avec prédiction vidéo multi-visualités et même répondre aux commandes vocales en langage naturel après un réglage fin. Le modèle sert efficacement de cerveau numérique pour une action réelle, a déclaré la société.
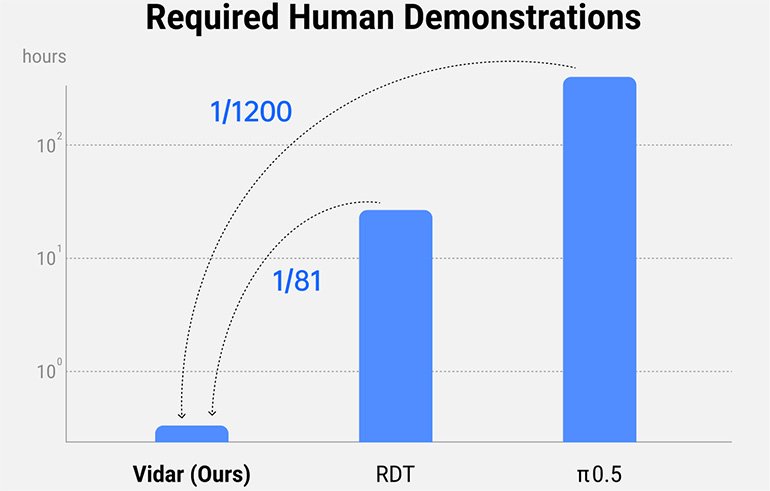
En utilisant le moteur vidéo génératif de Vidu, Vidar génère des simulations à grande échelle pour réduire la dépendance aux données physiques, tout en maintenant la complexité et la richesse nécessaires pour former des agents d’IA capables du monde réel. Shengshu a déclaré que Vidar peut extrapoler une série généralisée d’actions robotiques et de tâches à partir de seulement 20 minutes de données d’entraînement. La société a affirmé qu’il se situe entre 1/80 et 1/1200 des données nécessaires pour former des modèles de pointe, notamment RDT et π0,5.
Shengshu a déclaré que l’innovation principale de Vidar réside dans son architecture d’apprentissage modulaire en deux étapes. Contrairement aux méthodes traditionnelles qui fusionnent la perception et le contrôle, le vidar les découple en deux étapes distinctes pour une plus grande flexibilité et évolutivité.
Au stade en amont, les données vidéo générales à grande échelle et les données vidéo incarnées à l’échelle modérée sont utilisées pour former le modèle de Vidu pour la compréhension perceptuelle.
Dans le deuxième stade en aval, un modèle agnostique de tâche appelé AnyPOS transforme cette compréhension visuelle en commandes motrices exploitables pour les robots. Cette séparation rend beaucoup plus facile et plus rapide de former et de déployer l’IA sur différents types de robots, tout en réduisant les coûts et en augmentant l’évolutivité.
Vidar est conçu pour réduire la quantité de données de formation nécessaires pour former des modèles d’IA. Source: Technologie Shengshu.
Vidar un cadre pour une intelligence incarnée évolutive
Vidar suit un cadre de formation évolutif inspiré des modèles de fondation de langue et d’image de la dernière décennie de percées d’IA. Shengshu a déclaré que sa pyramide de données à trois niveaux, couvrant une vidéo générique à grande échelle, des données vidéo incarnées et des exemples spécifiques au robot, constitue un système plus flexible, réduisant le goulot d’étranglement des données traditionnelles.
Construit sur l’architecture U-VIT, qui explore la fusion des modèles de diffusion et des architectures de transformateurs pour un large assortiment de tâches de génération multimodales, vidar harnais la modélisation temporelle à long terme et la cohérence vidéo multi-angles pour alimenter la prise de décision physiquement ancrée.
Cette conception prend en charge un transfert rapide de la simulation au déploiement du monde réel, qui, selon Shengshu, est essentiel pour la robotique dans des environnements dynamiques. Il minimise également la complexité de l’ingénierie, selon la société,
Shengshu a déclaré que Vidar peut faciliter l’adoption de la robotique dans plusieurs secteurs. Des assistants à domicile et des soins des personnes âgées à la fabrication intelligente et à la robotique médicale, le modèle permet une adaptation rapide à de nouveaux environnements et des scénarios multi-tâches, tous avec des données minimales, a-t-il ajouté.
Vidar crée un chemin AI-Natif pour le développement de la robotique qui est efficace, évolutif et rentable, a affirmé Shengshu. En transformant la vidéo générale en intelligence robotique exploitable, la société a déclaré que son modèle pouvait combler l’écart entre la compréhension visuelle et l’agence incarnée.
Vidar a une architecture d’apprentissage modulaire. Source: Technologie Shengshu
Shengshu marque les jalons dans l’IA multimodale
Vidar s’appuie sur l’élan rapide du modèle de fondation vidéo Vidu, a déclaré Shengshu. La société a coté les statistiques depuis ses débuts:
- Vidu a atteint 1 million d’utilisateurs dans un délai d’un mois
- A dépassé 10 millions d’utilisateurs en seulement trois mois
- Généré plus de 100 millions de vidéos au mois 4
- La génération de référence à la vidéo a dépassé les 100 millions d’ici le mois 8
- Total des vidéos générées désormais les 300 millions de choses
Shengshu continue d’étendre les frontières de l’IA multimodale, le vidar représente la prochaine frontière: la généralisation, la génération et le mode de réalisation dans un système unifié.
Note de l’éditeur: Robobusiness 2025, qui aura lieu les 15 et 16 octobre à Santa Clara, en Californie, comprendra des pistes sur AI physique et humanoïde robots. L’inscription est maintenant ouverte.
Source link



