
Implémentation de chiffon à partir de zéro à l’aide de transformateurs de visage étreintes et Faish
- Intelligence Artificielle
 Noesis News
Noesis News- 0
- 3 minutes de lecture
Auteur (s): Jayita Gulati
Publié à l’origine sur Vers l’IA.
Dans le monde de l’IA et des chatbots, il est excitant de voir des modèles de langue générer du texte humain. Mais il y a un gros problème: ces modèles ne savent pas toujours tout. Ils ne répondent qu’en fonction des données sur lesquelles ils ont été formés. Et si vous voulez que votre modèle réponde aux questions de vos documents personnalisés, de vos wikis d’entreprise ou d’articles récents?
C’est là que la génération (RAG) de la récupération est intervenue.
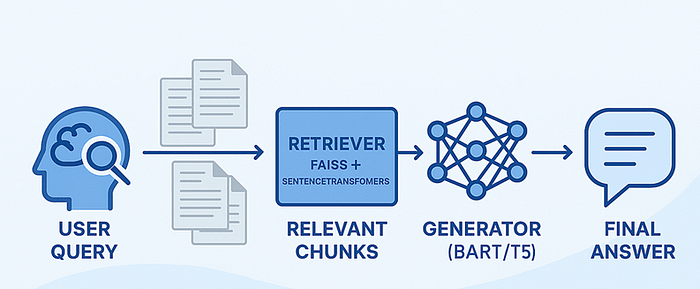
Le chiffon aide les modèles linguistiques à devenir plus intelligents et plus utiles en les laissant «chercher les choses» avant de répondre. Cet article vous guidera à travers la construction d’un pipeline de chiffons en utilisant des outils d’Open-source populaires: les transformateurs de visage étreintes, Fais pour la recherche de similitude et les conduisés pour le codage.
La génération de la récupération (RAG) est une méthode qui améliore la façon dont les modèles de langue répondent aux questions en les permettant de récupérer des informations pertinentes à partir de sources externes avant de générer une réponse.
Des modèles traditionnels comme GPT ou Bert génèrent du texte basé uniquement sur ce qu’ils ont appris pendant la formation, ce qui signifie qu’ils ne peuvent pas accéder aux données nouvelles ou dynamiques à moins que le recyclage. Il s’agit d’une limitation majeure, en particulier dans les applications du monde réel comme le support client ou les questions et réponses médicales.
Le chiffon résout cela en divisant le processus en deux parties:
Récupérer – Recherchez des morceaux de documents pertinents liés à la question de l’utilisateur. Lisez le blog complet gratuitement sur Medium.
Publié via Vers l’IA



