
Hé robot! Construisez votre propre compagnon AI
- Robotique
 Noesis News
Noesis News- 0
- 8 minutes de lecture

Les LLM ont traditionnellement été des modèles autonomes qui acceptent l’entrée de texte et répondent avec du texte. Au cours des deux dernières années, nous avons vu des LLM multimodales entrer dans la scène, comme GPT-4O, qui peuvent accepter et répondre avec d’autres formes de médias, telles que des images et des vidéos.
Mais au cours des derniers mois, certains LLM ont obtenu une nouvelle capacité puissante – à appeler des fonctions arbitraires – qui ouvre un énorme monde d’actions d’IA possibles. Chatgpt et Ollama appellent tous les deux cette capacité outils. Pour activer ces outils, vous devez définir les fonctions dans un dictionnaire Python et décrire pleinement leurs paramètres d’utilisation et disponibles. Le LLM essaie de déterminer ce que vous demandez et cartes qui demandent à l’un des outils / fonctions disponibles. Nous analysons ensuite la réponse avant d’appeler la fonction réelle.
Voyons ce concept avec une fonction simple qui allume et éteint une LED. Connectez une LED avec une résistance limite à PIN GPIO 17 sur votre Raspberry Pi 5.
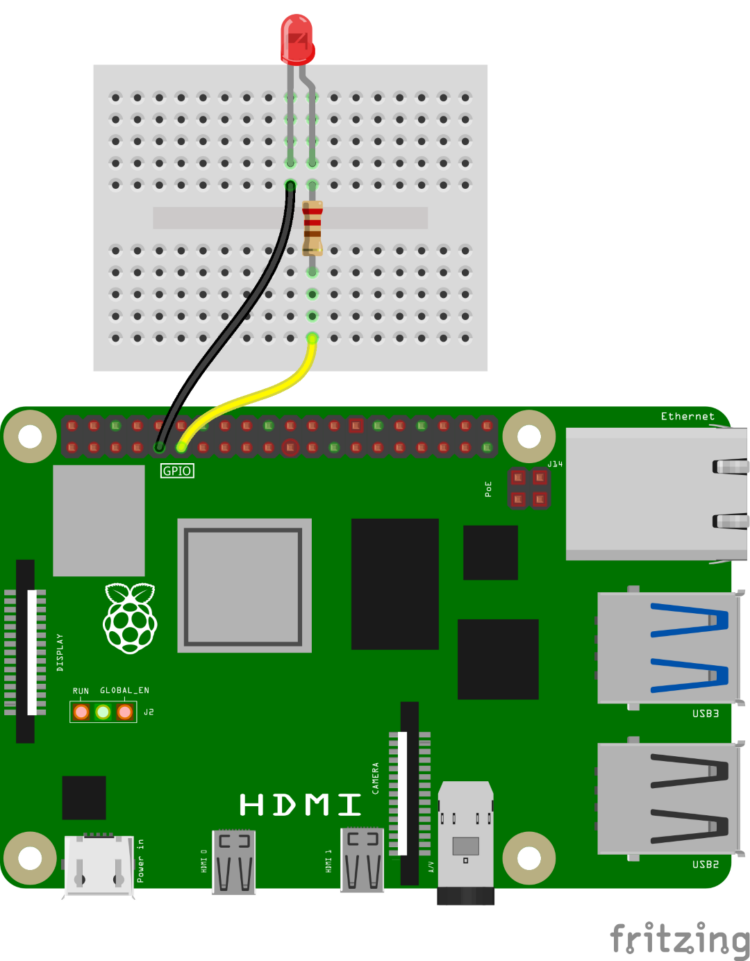
Assurez-vous que vous êtes dans le Venv-bienfais environnement virtuel que nous avons configuré plus tôt et installer certaines dépendances:
$ source venv-ollama/bin/activate $ sudo apt update $ sudo apt upgrade $ sudo apt install -y libportaudio2 $ python -m pip install ollama==0.3.3 vosk==0.3.45 sounddevice==0.5.0
Vous devrez télécharger un nouveau modèle LLM et le modèle VOSK Speech-Text (STT):
$ ollama pull allenporter/xlam:1b $ python -c "from vosk import Model; Model(lang='en-us')"
Comme cet exemple utilise la parole en texte pour transmettre des informations au LLM, vous aurez besoin d’un microphone USB, tel que Adafruit 3367. Avec le microphone connecté, exécutez la commande suivante pour découvrir le numéro de périphérique de microphone USB:
$ python -c "import sounddevice; print(sounddevice.query_devices())"
Vous devriez voir une sortie telle que:
0 USB PnP Sound Device: Audio (hw:2,0), ALSA (1 in, 0 out) 1 pulse, ALSA (32 in, 32 out) * 2 default, ALSA (32 in, 32 out)
Notez le numéro de périphérique du microphone USB. Dans ce cas, mon microphone est le numéro de périphérique 0, comme le montre le périphérique sonore PNP USB. Copie ce code à un fichier nommé olllama-light-assistant.py sur votre Raspberry Pi.
Vous pouvez également télécharger ce fichier directement avec la commande:
$ wget https://gist.githubusercontent.com/ShawnHymel/16f1228c92ad0eb9d5fbebbfe296ee6a/raw/6161a9cb38d3f3c4388a82e5e6c6c58a150111cc/ollama-light-assistant.py
Ouvrez le code et modifiez le Audio_input_index Valeur pour votre numéro de périphérique de microphone USB. Par exemple, le mien serait:
AUDIO_INPUT_INDEX = 0
Exécutez le code avec:
$ python ollama-light-assistant.py
Vous devriez voir le démarrage du système VOSK STT, puis le script dira «écouter…» À ce stade, essayez de demander au LLM de «allumer la lumière». Parce que le PI n’est pas optimisé pour les LLM, la réponse pourrait prendre 30 à 60 secondes. Avec un peu de chance, vous devriez voir que le LED_WRITE La fonction a été appelée, et la LED s’est activée!
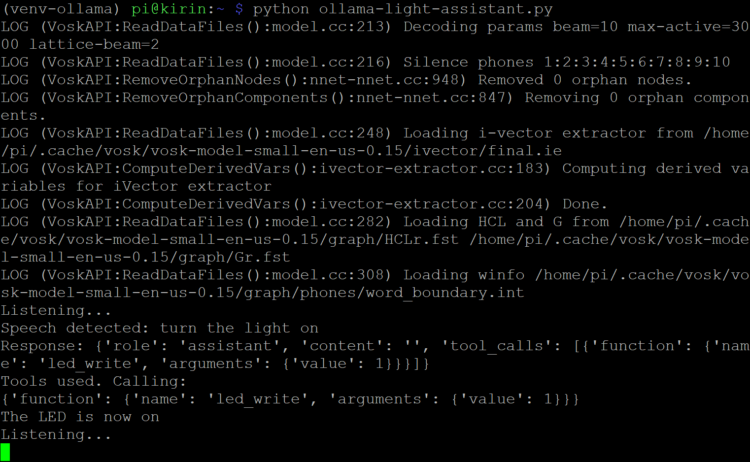
Le xlam modèle est un LLM open-source développé par l’équipe de recherche Salesforce AI. Il est formé et optimisé pour comprendre Demandes plutôt que de fournir nécessairement des réponses textuelles aux questions. Le allenporter La version a été modifiée pour travailler avec les outils Ollama. Le modèle de paramètre d’un milliard de milliards peut fonctionner sur le Raspberry Pi, mais comme vous l’avez probablement remarqué, il est assez lent et les requierts mal facilement.
Pour un LLM qui comprend mieux les demandes, je recommande le Lama3.1: 8b modèle. Dans la console de commande, téléchargez le modèle avec:
$ ollama pull llama3.1:8b
Notez que le modèle LLAMA 3.1: 8b est de près de 5 Go. Si vous manquez d’espace sur votre stockage flash, vous pouvez supprimer les modèles précédents. Par exemple:
$ ollama rm tinyllama
Dans le code, changez:
MODEL = "allenporter/xlam:1b"
à:
MODEL = "llama3.1:8b"
Exécutez à nouveau le script. Vous remarquerez que le modèle est moins pointilleux sur la formulation exacte de la demande, mais il faut beaucoup plus de temps pour répondre – jusqu’à 3 minutes sur un Raspberry Pi 5 (8 Go de RAM).
Lorsque vous avez terminé, vous pouvez quitter l’environnement virtuel avec la commande suivante:
$ deactivate



