
Harnais dinov2 incorpores pour une classification d’image précise
- Intelligence Artificielle
 Noesis News
Noesis News- 0
- 35 minutes de lecture

Auteur (s): Lihi gur arie, doctorat
Publié à l’origine sur Vers l’IA.
Introduction
La formation d’un classificateur d’images hautement performant nécessite généralement de grandes quantités de données étiquetées. Mais que se passe-t-il si vous pouviez obtenir des résultats de haut niveau avec un minimum de données et une formation légère?
DINOV2 est un puissant modèle de fondation de vision qui génère de riches vecteurs de représentation d’image, également connus sous le nom d’Embeddings. Contrairement aux modèles de texte comme AGRAFEqui se concentre sur l’alignement sémantique, DINOV2 excelle à capturer la structure visuelle, la texture et les détails spatiaux – ce qui le rend idéal pour les tâches de classification d’images à grain fin dans des domaines spécialisés tels que l’imagerie médicale et biologique.
Dans ce didacticiel, nous explorerons comment utiliser DINOV2 pour construire un classificateur zéro-shot en utilisant Voisins les plus chers (K-NN), et comment augmenter considérablement les performances en entraînant une couche linéaire au-dessus des fonctionnalités extraites. Grâce aux intérêts de haute qualité de DINOV2, nous pouvons former un classificateur précis en utilisant seulement un petit nombre d’images étiquetées.
Le code complet est disponible dans le cahier Colab intégré ci-dessous, prêt à explorer et à s’adapter à vos propres données.
Arrière-plan
Dino (Bref pour Diablesolution avec NON Labels), développé par Meta, est une méthode pour former des modèles de vision de manière auto-supervisée, sans étiquettes. Les modèles Dino produits sont de puissants modèles de fondation Vision capables d’extraire des fonctionnalités riches d’images. En attachant différentes têtes au-dessus de l’épine dinov2, le modèle peut être ajusté à différentes tâches de vision, telles que la classification d’image, la segmentation, les estimations de profondeur et plus encore. Bien que dans ce tutoriel, nous n’entraînerons pas la colonne vertébrale de Dino, il est perspicace de comprendre comment il a été initialement formé. Si vous êtes impatient de sauter dans le code, vous pouvez sauter directement vers le Implémentation de code section.
𝐃𝐈𝐍𝐎𝐯𝟏
La première version de Dino a introduit une technique d’auto-distillation où un réseau étudiant apprend à prédire la sortie d’un réseau d’enseignants. L’enseignant et l’élève partagent la même architecture: une épine dorsale de transformateur de vision (VIT) et un MLP à 3 couches (multi-couches Perceptron) tête. Le réseau des enseignants a également été introduit avec le centrage et l’affûtage pour éviter l’effondrement. Pendant la formation, l’enseignant reçoit de grandes cultures (vues mondiales) d’une image, tandis que l’élève traite à la fois de petites (vues locales) et de grandes cultures de la même image. Les cultures sont traitées à travers les filets et l’élève essaie de prédire la sortie de l’enseignant aiguisé (basse température). L’affûtage est effectué en utilisant une valeur à basse température dans le softmax du filet de l’enseignant, pour élever la confiance de l’enseignant à une dimension dominante, pour permettre de meilleures conseils à l’élève.
Les poids des étudiants sont mis à jour avec la croixentropie fonction de coûtet les poids de l’enseignant sont mis à jour pour être la moyenne mobile exponentielle du réseau étudiant.
𝐃𝐈𝐍𝐎𝐯𝟐
Dinov2 Améliore ce cadre original en intégrant plusieurs améliorations clés. À la base, Dinov2 utilise deux objectifs doubles qui fonctionnent en tandem:
- Objectif au niveau de l’image – Hérité de Dino, cet objectif encourage le réseau étudiant à correspondre à la représentation mondiale de l’image de l’enseignant. Il fonctionne sur le jeton de classe pour capturer la vue holistique de l’image.
- Niveau de patch objectif – inspiré par ibotCet objectif consiste à masquer certains correctifs dans l’entrée de l’élève. L’élève tente ensuite de prédire ces régions masquées en utilisant les patchs visibles environnants comme contexte. Croix entropie est calculé entre l’élève et les fonctionnalités du patch des enseignants, favorisant la compréhension des fonctionnalités locales.
Cette approche à double objectif encourage à la fois une compréhension de haut niveau de l’image via l’objectif au niveau de l’image, et une perception locale détaillée via l’objectif au niveau du patch, entraînant des représentations visuelles plus riches.
La perte de formation finale est une somme pondérée de la perte de dino et de la perte IBOT, équilibrant efficacement les signaux d’apprentissage mondiaux et locaux.
De plus, plusieurs autres optimisations ont été introduites dans DINOV2, notamment une amélioration des stratégies de normalisation et de régularisation, un schéma de formation multi-résolution et une formation sur une image organisée de haute qualité et organisée ensemble de données. Vous pouvez en savoir plus à ce sujet (ici).
Implémentation de code
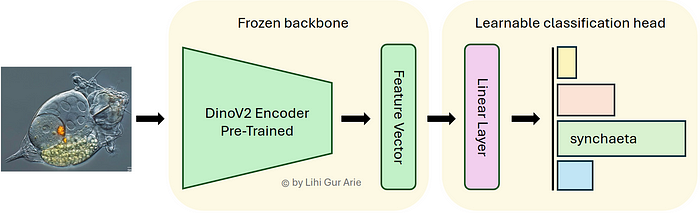
Après avoir exploré l’architecture Dino et son processus de formation de l’épine dorsale, dans ce didacticiel, nous ferons tirer parti d’une épine dinov2 pré-formée pour extraire les vecteurs de représentation d’image. Tout d’abord, nous évaluerons ses performances à tirs zéro en utilisant un knn classificateur. Ensuite, nous améliorerons les performances en formant une seule couche de classification linéaire sur le dessus.
Configuration de l’environnement
Puisque nous utilisons le visage étreint pour charger le modèle pré-formé, assurez-vous que votre jeton de face étreint est configuré dans votre Google Colab environnement.
Ensuite, installez et importez les bibliothèques requises.
Ensemble de données aperçu
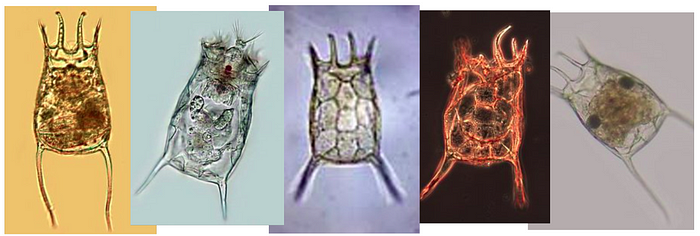
Nous utiliserons le EMDS-6 L’ensemble de données des micro-organismes, qui a été initialement conçu pour la segmentation, et l’adapter pour la classification dans ce tutoriel. L’ensemble de données contient 21 classes de micro-organismes qui partagent des fonctionnalités visuellement similaires, ce qui en fait une tâche de classification à grains fins. Avec seulement 40 images par classe et seulement 32 utilisés pour la formation, il pose également un réglage difficile de données faibles.
J’ai préparé les données dans des ensembles de formation 80% et 20% de validation. Vous pouvez télécharger la version préparée, structurée comme suit:
EMDS6_Data/
├── train/
│ ├── actinophrys/
│ ├── arcella/
│ └── ...
├── val/
│ ├── actinophrys/
│ ├── arcella/
│ └── ...
Chaque sous-fichier est nommé d’après une classe et contient des images PNG du micro-organisme respectif. Vous trouverez ci-dessous un échantillon aléatoire de l’ensemble de données, une image de chacune des 21 classes:
Maintenant que nous avons téléchargé et visualisé l’ensemble de données, nous allons configurer un pipeline de données pour charger et prétraiter les images.
Partie I – Classification zéro
Dans la première partie, nous examinerons les performances zéro-tir sur DINOV2 à l’aide d’un classificateur KNN.
Chargement des données d’image au modèle DINOV2
Pour préparer nos données pour extraction de caractéristiquesnous utilisons timmLes utilitaires pratiques pour définir les transformations d’image en fonction de la configuration de données du modèle. Nous créons ensuite des ensembles de données Pytorch de formation et de validation à l’aide du ImageDataset classe, appliquant les transformations à chaque ensemble. Enfin, DataLoaderS sont configurés pour alimenter les images dans le modèle DINOV2, garantissant un prétraitement cohérent et un lot efficace des images et des étiquettes.
def create_data_loaders(data_dir, batch_size=32, model_name='vit_small_patch14_dinov2', seed=42):
"""
Create data loaders using timm's transforms and dataset utilities.
"""# Set generator with seed for reproducible data loading
g = torch.Generator()
g.manual_seed(seed)
# Create transforms
data_config = timm.data.resolve_model_data_config(model_name)
data_config('input_size') = (3, 518, 518) # DINOv2's native resolution
train_transform = timm.data.create_transform(**data_config, is_training=True)
val_transform = timm.data.create_transform(**data_config, is_training=False)
# Create datasets using timm's Dataset class
train_dataset = ImageDataset(root=os.path.join(data_dir, 'train'), transform=train_transform)
val_dataset = ImageDataset(root=os.path.join(data_dir, 'val'), transform=val_transform)
# Create dataloaders
train_loader = DataLoader(
train_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=2,
pin_memory=True,
generator=g
)
val_loader = DataLoader(
val_dataset,
batch_size=batch_size,
shuffle=False,
num_workers=2,
pin_memory=True,
generator=g
)
# Get class mappings
class_names = train_dataset.reader.class_to_idx
id2label = {v: k for k, v in class_names.items()}
label2id = class_names
print(f"Created data loaders:")
print(f" Training: {len(train_dataset)} samples, {len(train_loader)} batches")
print(f" Validation: {len(val_dataset)} samples, {len(val_loader)} batches")
print(f" Number of classes: {len(class_names)}")
return train_loader, val_loader, id2label, label2id
# Create data loaders
train_loader, val_loader, id2label, label2id = create_data_loaders(
data_dir='/content/EMDS6_Data',
batch_size=32, seed=0
)
Extraction des fonctionnalités DINOV2
Avec nos objets de données prêts, l’étape suivante consiste à passer les images via un modèle DINOV2 pré-formé, pour extraire des intégres riches. Par établissement num_classes=0nous supprimons la tête de classification et obtenons des vecteurs de fonctions brutes de l’épine dorsale.
def extract_features(train_loader, val_loader, model_name='vit_small_patch14_dinov2'):
"""
Extract features using DINOv2 model from timm.
"""
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# Create a feature extractor using timm
model = timm.create_model(
model_name,
pretrained=True,
num_classes=0
).to(device)
model = model.eval()
# Function to extract features
def extract_batch_features(loader):
all_features = ()
all_labels = ()
with torch.no_grad():
for images, labels in tqdm(loader, desc="Extracting features"):
images = images.to(device)
features = model(images)
all_features.append(features.cpu())
all_labels.append(labels)
return torch.cat(all_features, dim=0), torch.cat(all_labels, dim=0)
# Extract features from train and validation sets
train_features, train_labels = extract_batch_features(train_loader)
print(f"Training features shape: {train_features.shape}")
val_features, val_labels = extract_batch_features(val_loader)
print(f"Validation features shape: {val_features.shape}")
return train_features, train_labels, val_features, val_labels
# Extract features
train_features, train_labels, val_features, val_labels = extract_features(
train_loader, val_loader
)
Classification zéro-shot avec KNN
Pour évaluer la qualité des intérêts DINOV2, nous appliquons un classificateur K-Nearest Neighbors (KNN) directement sur les caractéristiques extraites. Cette méthode simple n’implique aucune formation – elle classe chaque image de validation basée sur les intégres les plus proches de l’ensemble de formation. Le résultat: un knn précision de 83,9% Ce qui est un résultat assez décent étant donné le défi de distinguer entre 21 classes à grains fins. Cela dit, nous pouvons repousser les performances en entraînant un classificateur linéaire par-dessus.
Partie II – Formation d’une tête de classificateur linéaire
Bien que KNN classe en fonction de la distance entre les fonctionnalités, il ne s’adapte pas aux limites de décision spécifiques qui séparent les classes de notre ensemble de données. En formant un classificateur linéaire avec les intégres en tant qu’entrées, nous pouvons mieux façonner l’espace des fonctionnalités pour correspondre à notre ensemble de données et mieux séparer les classes.
Configuration de la caractéristique de dataloder
Pour charger efficacement les données par lots pendant la formation, nous créons un nouvel ensemble de DataLoaderS pour gérer les intégres DINOV2 précédemment extraits.
def create_feature_dataloaders(train_features, train_labels, val_features, val_labels, batch_size=64, seed=42):
"""
Create data loaders for pre-extracted features.
"""
# Set generator with seed for reproducible data loading
g = torch.Generator()
g.manual_seed(seed)# Use timm.data.Dataset for feature datasets
train_dataset = TensorDataset(train_features, train_labels)
val_dataset = TensorDataset(val_features, val_labels)
train_loader = DataLoader(
train_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=0,
pin_memory=True,
generator=g
)
val_loader = DataLoader(
val_dataset,
batch_size=batch_size,
shuffle=False,
num_workers=0,
pin_memory=True,
generator=g
)
print(f"Created feature dataloaders:")
print(f" Training: {len(train_dataset)} samples, {len(train_loader)} batches")
print(f" Validation: {len(val_dataset)} samples, {len(val_loader)} batches")
return train_loader, val_loader
# Create feature dataloaders
train_feature_loader, val_feature_loader = create_feature_dataloaders(
train_features, train_labels, val_features, val_labels, seed=0
)
Définir une tête de classification linéaire
Nous définissons un modèle Pytorch simple composé d’une couche d’abandon suivie d’une couche linéaire entièrement connectée. L’entrée du modèle est un vecteur de fonctionnalité DINOV2, et la sortie est un score de classe pour chaque catégorie de micro-organismes. Cette tête légère est facile à entraîner et suffisante pour obtenir des résultats solides.
class DINOv2Classifier(nn.Module):
"""Linear classifier for DINOv2 features."""
def __init__(self, input_dim, num_classes):
super().__init__()
self.classifier = nn.Sequential(
nn.Dropout(0.2),
nn.Linear(input_dim, num_classes)
)def forward(self, x):
return self.classifier(x)
# Create classifier model
feature_dim = train_features.shape(1)
num_classes = len(id2label)
classifier = DINOv2Classifier(feature_dim, num_classes).to(device)
Formation de la tête de classification
Dans cette étape, nous définissons les paramètres de boucle de formation et formons la tête de classification linéaire. La boucle garde une trace des meilleurs poids de modèle en fonction de la précision de validation.
def train_model(classifier, train_loader, val_loader, num_epochs, lr):
"""Train the classifier on extracted DINOv2 features."""# Setup training
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(classifier.parameters(), lr=lr, weight_decay=1e-5)
scheduler = CosineAnnealingLR(optimizer, T_max=num_epochs, eta_min=1e-6)
history = {'train_loss': (), 'train_acc': (), 'val_loss': (), 'val_acc': (), 'lr': ()}
best_val_acc = 0.0
for epoch in range(num_epochs):
# Training phase
classifier.train()
train_loss, train_correct = 0.0, 0
for features, labels in tqdm(train_loader, desc=f"Epoch {epoch+1}/{num_epochs} - Train"):
features, labels = features.to(device), labels.to(device)
# Forward & backward pass
outputs = classifier(features)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# Track metrics
train_loss += loss.item() * features.size(0)
_, predicted = torch.max(outputs, 1)
train_correct += (predicted == labels).sum().item()
# Validation phase
classifier.eval()
val_loss, val_correct = 0.0, 0
with torch.no_grad():
for features, labels in tqdm(val_loader, desc=f"Epoch {epoch+1}/{num_epochs} - Val"):
features, labels = features.to(device), labels.to(device)
outputs = classifier(features)
loss = criterion(outputs, labels)
val_loss += loss.item() * features.size(0)
_, predicted = torch.max(outputs, 1)
val_correct += (predicted == labels).sum().item()
# Calculate epoch metrics
train_size, val_size = len(train_loader.dataset), len(val_loader.dataset)
train_loss, train_acc = train_loss / train_size, train_correct / train_size
val_loss, val_acc = val_loss / val_size, val_correct / val_size
# Update the learning rate
scheduler.step()
current_lr = optimizer.param_groups(0)('lr')
# Store metrics
for key, value in zip(
('train_loss', 'train_acc', 'val_loss', 'val_acc', 'lr'),
(train_loss, train_acc, val_loss, val_acc, current_lr)):
history(key).append(value)
# Print results & save best model
print(f"nEpoch {epoch+1}/{num_epochs}: train_acc={train_acc:.4f}, val_acc={val_acc:.4f}, lr={current_lr:.6f}")
if val_acc > best_val_acc:
best_val_acc = val_acc
torch.save(classifier.state_dict(), "/content/best_dinov2_classifier.pth")
print(f"✓ New best model saved: {val_acc:.4f}")
return history
# Train the classifier
history = train_model(classifier, train_feature_loader, val_feature_loader, num_epochs=20, lr=0.5)
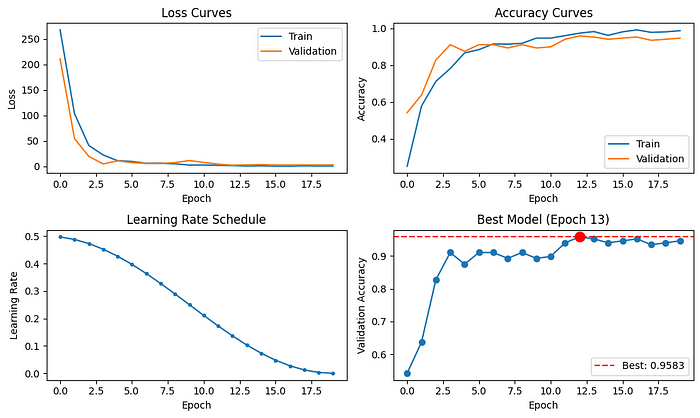
En regardant les parcelles de formation ci-dessous, nous observons une baisse claire de la perte et une forte augmentation de la précision au cours des premières époques, ce qui indique que le modèle apprend efficacement. Au fur et à mesure que la formation progresse et que le taux d’apprentissage diminue, le modèle converge progressivement et se stabilise. Le modèle le plus performant est enregistré à l’époque 13, réalisant une validation impressionnante précision de 95,8%une amélioration significative par rapport à la ligne de base KNN à tirs zéro!
Remarques de clôture
Dans ce tutoriel, nous avons utilisé les riches intégrés de Dinov2 pour construire un classificateur de micro-organismes précis. Malgré l’ensemble de données petit et difficile, nous avons atteint une précision de 83,9% de tirs zéro avec KNN et 95,8% en formant une tête linéaire simple. DINOV2 est bien adapté pour des scénarios avec des étiquettes limitées et des détails visuels à grain fin. Cependant, son épine dorsale lourde le rend moins adapté aux applications en temps réel ou au déploiement sur des périphériques de bord à faible ressource. Pour les tâches qui nécessitent une compréhension sémantique plus profonde, des modèles en langue visuelle comme CLIP peuvent fournir des intérêts plus contextuellement appropriés.
Merci d’avoir lu!
Félicitations pour avoir fait tout le chemin ici! Si vous avez apprécié le tutoriel, appuyez sur 👍x50 pour augmenter l’estime de soi de l’algorithme et aider plus de lecteurs à le trouver 🤓
Vous voulez en savoir plus?
Code complet comme cahier Colab:
Publié via Vers l’IA
Source link



