
Génération d’images comme LLMS: L’approche autorégressive | par Pietro Bolcato | Avril 2025
- Intelligence Artificielle
 Noesis News
Noesis News- 0
- 29 minutes de lecture
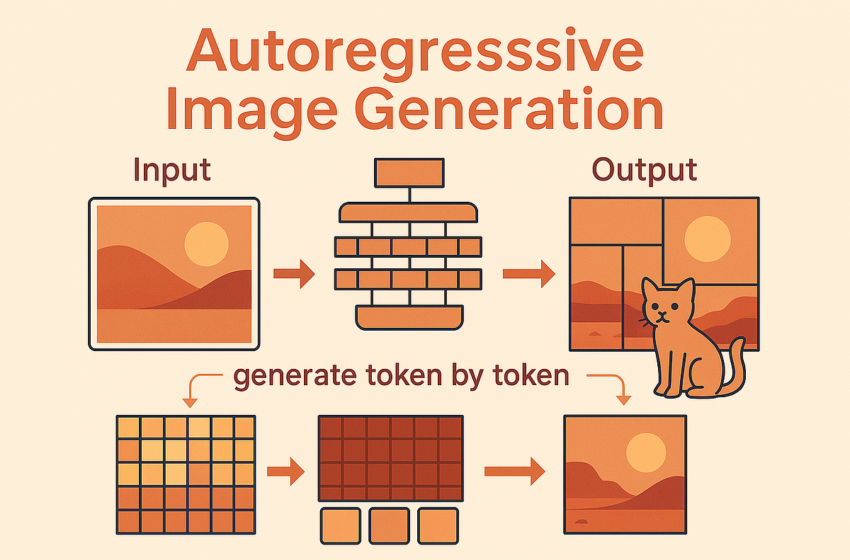
Un aperçu de la façon dont des modèles comme GPT-4O pourraient générer des images, de la tokenisation aux lois à l’échelle
Je travaille avec des modèles génératifs depuis longtemps et la forte performance de GPT-4O m’a vraiment intrigué. Ils ont partagé dans la carte modèle qui est un autorégressif (AR) Méthode, rien de plus. Contrairement aux modèles de diffusion dominants, les modèles AR génèrent des images jeton par jetonun peu comme les grands modèles de langue (LLMS) génèrent du texte. Cette approche séquentielle est fascinante, en particulier pour les systèmes multimodaux, car il offre un moyen unifié de modéliser à la fois des jetons de texte et d’image dans l’entrée et espace de sortie.
Ce post plonge dans la mécanique de la génération d’images autorégressive. Nous allons tomber en panne:
- Le concept de base de modélisation d’image AR.
- Comment sont les images transformé en séquences de jetons.
- Clé choix architecturaux et stratégies de formation.
- Preuve de lois à l’échelle Similaire aux LLM.
- Le capacités émergentes et limitations actuelles de ces modèles.
Bien qu’Openai n’ait pas publié de rapport technique pour la génération d’images de GPT-4O, des recherches récentes comme Liquide Partage probablement des similitudes en architecture et en formation, nous donnant des informations précieuses sur cette approche très intéressante.
En son cœur, la modélisation autorégressive concerne Prédire l’élément suivant d’une séquence basée uniquement sur les éléments qui l’ont précédé. Pour le texte, cela signifie prédire le jeton de mot ou de sous-mot suivant. Pour les images, l’idée principale est la même, mais nous prédisons le suivant jeton d’image xᵢ basé sur la séquence précédente x <ᵢ.
Le défi? Les images sont intrinsèquement des grilles 2D, pas des séquences 1D. Pour appliquer des modèles AR, nous devons imposer une commande 1D:
- Scan raster: L’approche classique. Aplatir l’image (ou sa représentation de jeton) ligne par rang ou colonne par colonne, puis prédire les jetons séquentiellement, comme la lecture du texte. Imagegpt a été le pionnier.
- Prédiction à l’échelle suivante: Une approche plus récente, venant de Var. Au lieu de prédire les jetons simples, le modèle prédit Cartes entières entières à l’augmentation des résolutions. La génération se produit séquentiellement à travers les échelles (grossier à fin) mais souvent en parallèle dans une échelle.
Ces prédictions séquentielles sont généralement gérées par Décodeurs de transformateurs en utilisant Masques d’attention causaleassurant qu’un modèle ne s’occupe que des jetons précédents, identique à la façon dont les LLM fonctionnent. Cette similitude architecturale permet d’adapter les LLM pré-formés pour la génération d’images et la modélisation conjointe des jetons de texte et d’image.
Les LLM fonctionnent sur des vocabulaires discrets (par exemple, des mots ou des sous-mots définis par un tokenizer de texte). Pour rendre les images compatibles avec ces transformateurs AR, nous devons les convertir en séquences de «jetons d’image». Ce processus, Tokenisation d’imagetombe principalement en deux catégories:
Il s’agit de l’approche la plus courante, analogue à la tokenisation de texte.
- Encodeur: Carte les patchs d’image à des vecteurs latents continus f.
- Quantiseur: L’étape cruciale. Mappe chaque vecteur f au Vector le plus proche dans un livre de codes fini et appris (comme un dictionnaire de motifs visuels). Il sort des indices entiers discrets (ID de jeton).
- Décodeur: Reconstruit l’image de la séquence des vecteurs de livre de codes choisis.
Avantages: Les jetons de sortie sont des entiers discrètes, directement utilisables avec une perte de transformation inter-entropie standard. Modèles comme Liquide Utilisez ce.
Inconvénients:
- Perte d’information: La quantification élimine inévitablement certaines informations, blessant potentiellement la fidélité de reconstruction et les détails fins.
- Instabilité de formation: Apprendre le livre de codes peut être difficile.
- Goulot d’étranglement de représentation: Les livres de codes VQ standard peuvent manquer de capacité à la fois pour la reconstruction à grains fins et la compréhension sémantique, un problème résolu par des méthodes comme UnitokLa quantification multi-Codebook (MCQ).
Cette approche évite les livres de codes discrets pour potentiellement conserver plus d’informations.
- Encodeur: Carte les patchs d’image sur des vecteurs latents continue x. Ces vecteurs sont les jetons.
- Next Token Prédiction: Le modèle AR prédit un vecteur de conditionnement Z basé sur des jetons continus précédents.
- Modélisation des distributions continues: Étant donné que les jetons ne sont pas des indices discrets, nous ne pouvons pas utiliser une entropie croisée simple. Nous devons modéliser la distribution de probabilité P (x | z) pour le jeton suivant continu x. MAR utilise intelligemment un petit Tête de modèle de diffusion Conditionné sur Z pour définir la perte et activer l’échantillonnage. Métamorphe prédit directement les incorporations de siglip continu.
- Décodeur: Un réseau séparé reconstruit l’image de la séquence de jetons continus.
Avantages: Évite la perte de quantification, une fidélité potentiellement plus élevée.
Inconvénients: Nécessite une modélisation plus complexe (comme les têtes de diffusion) pour la distribution de probabilité.
Tendance actuelle → Tokenisation discrète Reste dominant, en particulier pour les modèles unifiés tirant parti des architectures LLM existantes. Cependant, des innovations comme Unitok (améliorant le VQ discret) et Infini (Modélisation dans le sens du bit) Essayez de combler l’écart de fidélité.
Les modèles de génération d’images AR exploitent souvent les architectures de transformateurs, adaptant parfois les LLM pré-formées (Liquide, Métamorphe) ou entraîner de grands transformateurs à partir de zéro (Var, Infini). Certaines approches restent purement autorégressives, tandis que d’autres incorporent des éléments de diffusion, peut-être pour le décodage des jetons continus (Métamorphe Visualizer) ou dans le cadre du processus de prédiction des jetons (MAR).
Une promesse clé des modèles visuels AR est leur potentiel à exposer lois à l’échelle Similaire aux LLM:
- Amélioration prévisible: Papiers comme Liquide, Varet Métamorphe Montrez de fortes corrélations entre une taille / calcul accrue du modèle et des mesures de performances améliorées (la perte de validation, FID, IS, scores VQA).
- Capacité unifiée: À mesure que les modèles évoluent, le compromis entre les performances visuelles et linguistiques diminue (Liquide), suggérant que de grands modèles peuvent gérer efficacement les deux modalités.
Si la génération visuelle AR évolue aussi prévisible que les LLM, cela rend les efforts d’entraînement à grande échelle plus efficaces et justifiables.
Étant donné que les modèles Visual AR partagent souvent des architectures et des paradigmes de formation avec des LLM (en particulier lorsqu’ils ont affiné les LLM pré-formés), ils peuvent hériter de capacités puissantes:
- Généralisation zéro / petit coup: Les modèles peuvent effectuer des tâches qui ne sont pas explicitement visibles pendant l’entraînement, comme la peinture, la peinture ou le conditionnement spatial, souvent guidé par des instructions en langue naturelle.
- Raisonnement émergent: Les capacités de raisonnement de la LLM sous-jacente peuvent être transférées à la génération d’images. Métamorphe montrant que les modèles pouvaient générer une image d’un violon Lorsqu’il est invité avec «Un instrument de musique, cet instrument est souvent joué par le scientifique qui a formulé la théorie de la relativité spéciale» En raisonnant implicitement Einstein → Violon. Liquide met en évidence des capacités similaires, en tirant parti des connaissances mondiales absentes dans les encodeurs de texte standard.
- Connexion entre la compréhension et la génération: La formation conjointe sur la compréhension visuelle et les tâches de production en profite souvent les deux. Une meilleure compréhension de l’image semble conduire à une meilleure génération d’images, et vice-versa, en particulier dans les architectures unifiées.
Malgré la promesse, la génération d’images AR fait face à des obstacles:
Échelle à haute résolution
La réalisation de la qualité au niveau de la diffusion à des résolutions très élevées (par exemple, 1024×1024 et au-delà) est toujours un domaine de recherche actif pour les modèles AR, bien que des travaux récents (Infini) montre des progrès significatifs.
Vitesse de génération
- Traditionnel raster-scan ar est intrinsèquement lent en raison de sa nature séquentielle.
- Méthodes plus rapides comme Var (séquentiel à travers les échelles) et MAR (prédiction parallèle) ont des compromis. MAR peut perdre des avantages en cache de KV et la perte de diffusion ajoute des étapes d’échantillonnage par token. Bien que potentiellement plus rapide que la diffusion en plusieurs étapes, les comparaisons directes nécessitent un examen attentif des optimisations.
Complexité de formation
Les méthodes basées sur VQ impliquent une formation délicate en livres de codes (Unitok vise à améliorer cela). Les méthodes continues pourraient nécessiter une formation conjointe sur la perte de diffusion (MAR). Var Nécessite une pré-formation en jetons à plusieurs étapes.
Contrôleur
L’écosystème riche pour un contrôle à grain fin observé dans les modèles de diffusion (par exemple, ControlNets) est moins développé pour les modèles AR actuellement.
Dépendance des composants
Les performances peuvent être goulottes d’étranglement par la qualité du jetons d’image pré-formé ou du LLM de base utilisé.
Contexte mondial
La prédiction du pixel par pixel peut rendre la capture de dépendances à longue portée et la cohérence globale de l’image difficile par rapport aux méthodes avec plus de conditionnement global, telles que les modèles de diffusion. La prédiction à l’échelle suivante (VAR, Infinity) atténue cela.
Les modèles autorégressifs représentent un paradigme intéressant et de plus en plus compétitif pour la génération d’images, offrant une alternative ou un complément à la diffusion. Leur Compatibilité native avec des données séquentielles les rend idéales pour Systèmes multimodaux unifiés qui traitent et génèrent de manière transparente du texte et des images entrelacés, comme indiqué par GPT-4O.
Les avantages clés se trouvent dans leur potentiel pour Échelle de type LLM, Capacités de raisonnement émergentset simplicité architecturale (Tirant souvent des transformateurs standard). Cependant, des défis restent vitesse de génération, fidélité à haute résolution, complexité de formationet développant contrôleur.
Avec de nouvelles méthodes comme la prédiction à l’échelle suivante (Var), quantification avancée (Unitok), la modélisation du bit (Infini), et une prédiction de jeton continue directe (Mar, métamorphe), l’écart entre AR et les modèles de diffusion se ferme rapidement.
Il est probable que nous assisterons à une vague de recherche dans cette direction – quel temps pour être en vie!



