
Déverrouiller vos données sur la plate-forme d’IA: IA générative pour l’analyse multimodale
- Intelligence Artificielle
 Noesis News
Noesis News- 0
- 21 minutes de lecture


Contenu sponsorisé
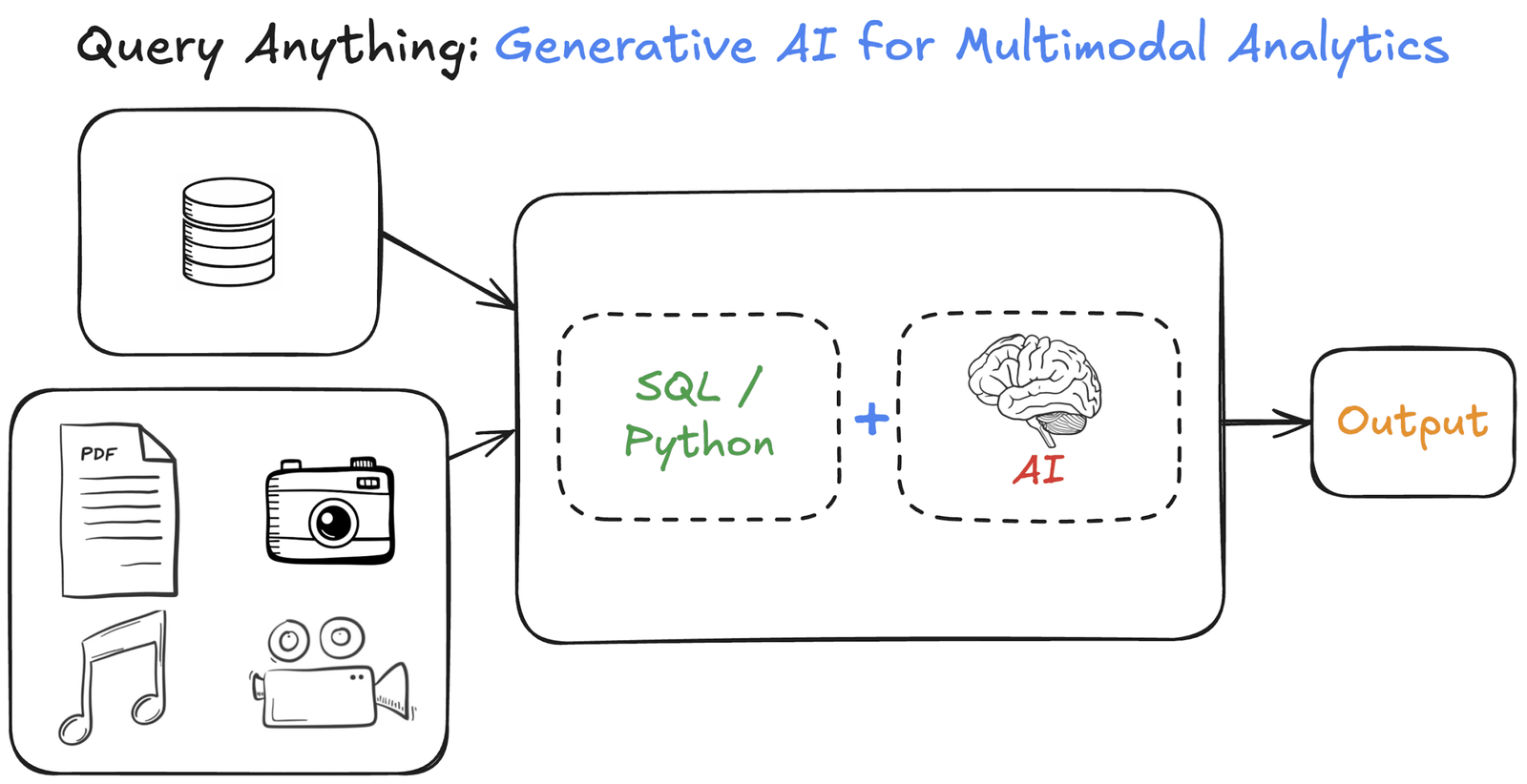
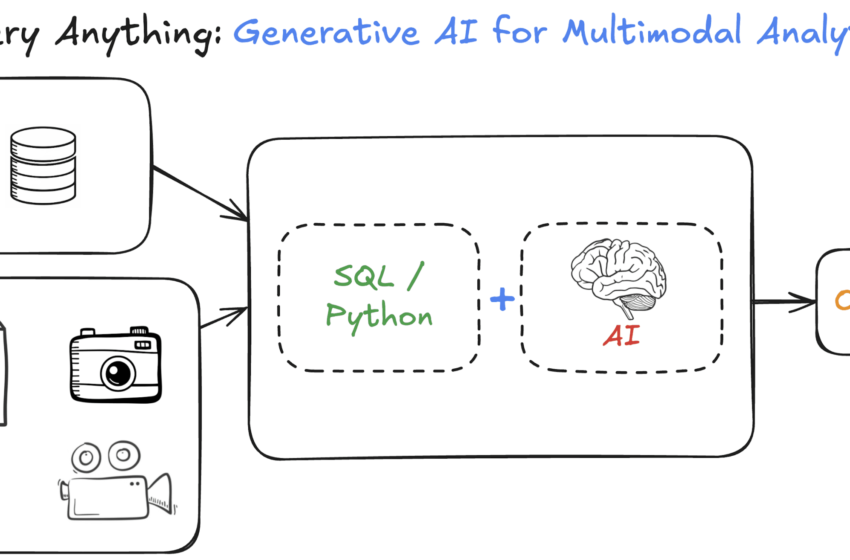
Les plateformes de données traditionnelles ont longtemps excellé dans les requêtes structurées sur les données tabulaires – pensez «Combien d’unités la région de l’Ouest a-t-elle vendu le trimestre dernier?» Cette base relationnelle sous-jacente est puissante. Mais avec le volume croissant et l’importance des données multimodales (par exemple, les images, l’audio, le texte non structuré), répondre aux questions sémantiques nuancées en s’appuyant sur des pipelines d’apprentissage automatique traditionnels et externes est devenu un goulot d’étranglement important.
Considérez un scénario de commerce électronique commun: «Identifiez les produits électroniques avec des taux de retour élevés liés aux photos des clients montrant des signes de dommages à l’arrivée.» Historiquement, cela signifiait l’utilisation de SQL pour les données de produits structurées, l’envoi d’images à un pipeline ML distinct pour l’analyse, et enfin tenter de combiner les résultats disparates. Un processus en plusieurs étapes et long où l’IA a été essentiellement boulonné sur le flux de données plutôt que nativement intégré dans l’environnement analytique.
Imaginez aborder cette tâche – combiner des données structurées avec des informations dérivées de supports visuels non structurés – en utilisant une seule instruction SQL élégante. Ce saut est possible en intégrant une IA générative directement dans le cœur de la plate-forme de données moderne. Il introduit une nouvelle ère où des analyses sophistiquées et multimodales peuvent être exécutées avec SQL familier.
Explorons comment l’IA génératrice remodèle fondamentalement les plates-formes de données et permet aux praticiens de fournir des informations multimodales avec la polyvalence de SQL.
L’algèbre relationnelle rencontre une AI générative
Les entrepôts de données traditionnels tirent leur pouvoir d’une fondation dans l’algèbre relationnelle. Cela fournit un cadre mathématiquement défini et cohérent pour interroger des données tabulaires structurées, excellant où les schémas sont bien définis.
Mais les données multimodales contiennent un contenu sémantique riche que l’algèbre relationnelle, en soi, ne peut pas interpréter directement. L’intégration générative de l’IA agit comme un pont sémantique. Cela permet des requêtes qui exploitent la capacité d’une IA à interpréter des signaux complexes intégrés dans des données multimodales, ce qui lui permet de raisonner comme les humains, transcendant ainsi les contraintes des types de données traditionnels et des fonctions SQL.
Pour apprécier pleinement cette évolution, explorons d’abord les composants architecturaux qui permettent ces capacités.
AI générative en action
Les données modernes sur les plates-formes d’IA permettent aux entreprises d’interagir avec les données en intégrant des capacités génératrices d’IA à la base. Au lieu de pipelines ETL aux services externes, fonctionne comme BigQuery AI.GENERATE et AI.GENERATE_TABLE Permettez aux utilisateurs de tirer parti de puissants modèles de langues (LLM) puissants à l’aide de SQL familière. Ces fonctions combinent les données d’un tableau existant, ainsi qu’une invite définie par l’utilisateur, vers un LLM, et renvoie une réponse.
Analyse de texte non structurée
Considérez une entreprise de commerce électronique avec un tableau contenant des millions d’examens de produits sur des milliers d’articles. L’analyse manuelle à ce volume pour comprendre l’opinion des clients prend beaucoup de temps. Au lieu de cela, les fonctions AI peuvent extraire automatiquement les thèmes clés de chaque revue et générer des résumés concises. Ces résumés peuvent offrir aux clients potentiels des aperçus rapides et perspicaces.
Analyse multimodale
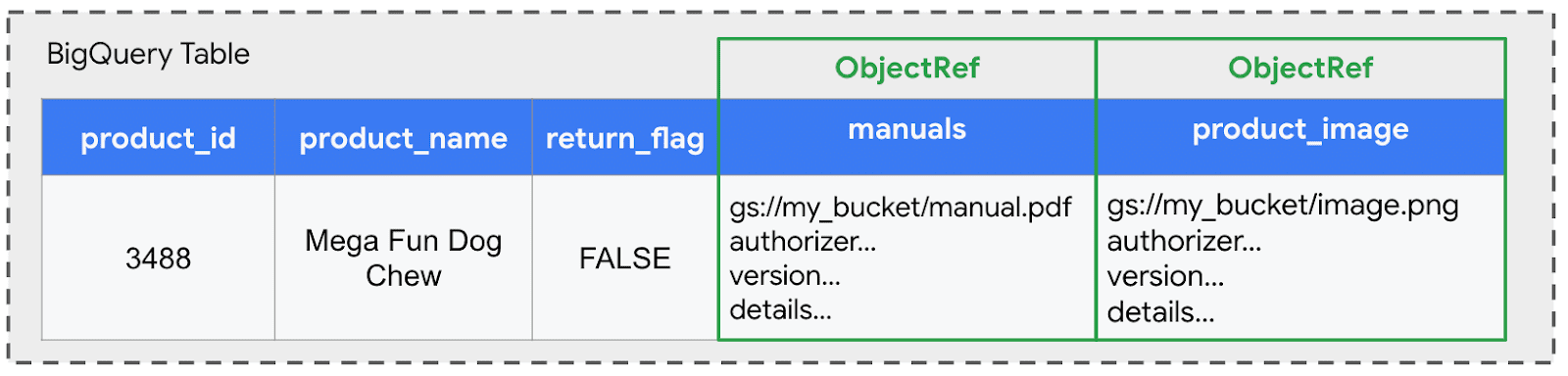
Et ces fonctions s’étendent au-delà des données non tabulaires. Les LLM modernes peuvent extraire des informations à partir de données multimodales. Ces données vivent généralement dans des magasins d’objets cloud comme Google Cloud Storage (GCS). BigQuery simplifie l’accès à ces objets avec ObjectRef. ObjectRef Les colonnes résident dans les tables BigQuery standard et référent en toute sécurité les objets dans GCS pour analyse.
Considérez les possibilités de combiner des données structurées et non structurées pour l’exemple de commerce électronique:
- Identifiez tous les téléphones vendus en 2024 avec des plaintes fréquentes de clients de «problèmes de couple Bluetooth» et référencez le manuel d’utilisation du produit (PDF) pour voir si des étapes de dépannage sont manquantes.
- Répertoriez les transporteurs d’expédition le plus fréquemment associés aux incidents «endommagés à l’arrivée» pour la région ouest en analysant des photos soumises par le client montrant des dommages liés au transit.
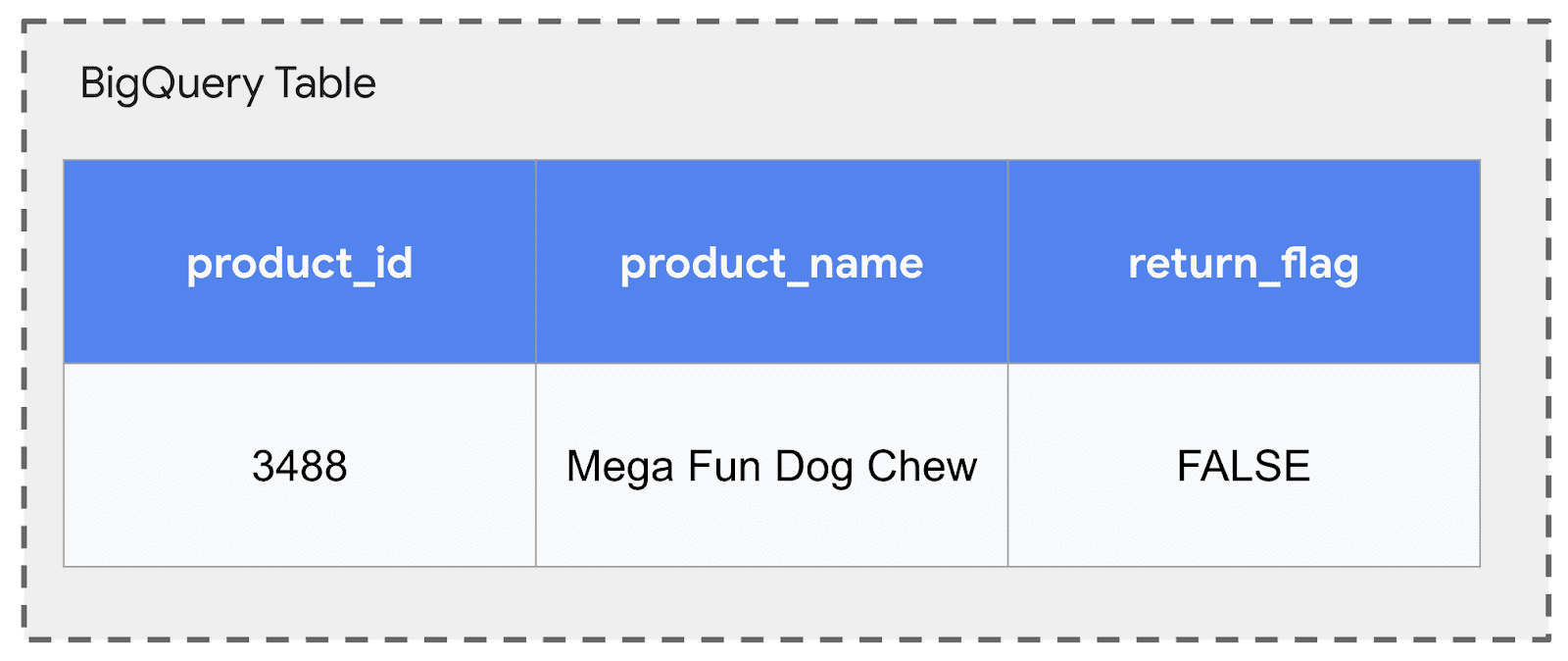
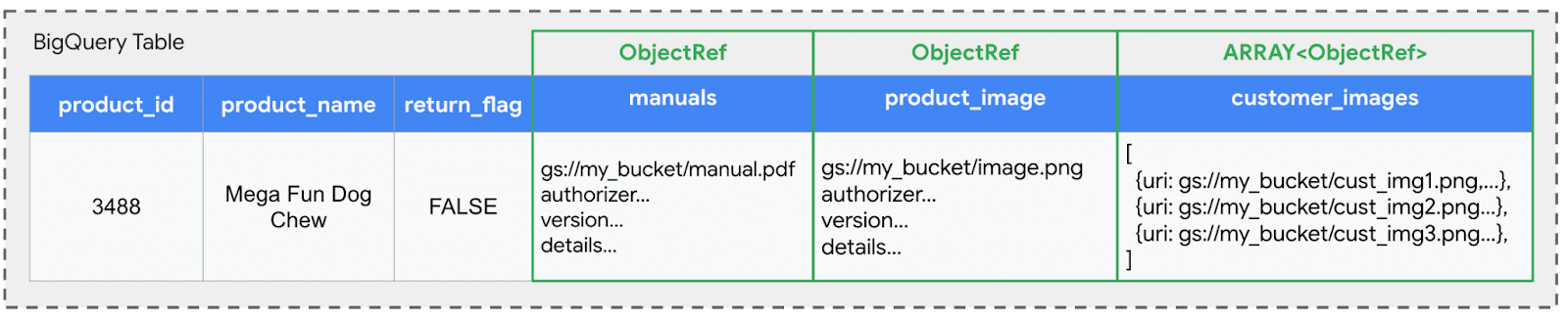
Pour aborder les situations où les idées dépendent de l’analyse de fichiers externe aux côtés des données de table structurées, BigQuery utilise ObjectRef. Voyons comment ObjectRef Améliore une table BigQuery standard. Considérez une table avec des informations de base du produit:
Nous pouvons facilement ajouter un ObjectRef colonne nommée manuals Dans cet exemple, pour référencer le manuel officiel du produit PDF stocké dans GCS. Cela permet au ObjectRef à vivre côte à côte avec des données structurées:
Cette intégration alimente l’analyse multimodale sophistiquée. Jetons un coup d’œil à un exemple où nous générons des paires de questions et réponses à l’aide des avis des clients (texte) et des manuels de produits (PDF):
SQL
SELECT
product_id,
product_name,
question_answer
FROM
AI.GENERATE_TABLE(
MODEL `my_dataset.gemini`,
(SELECT product_id, product_name,
('Use reviews and product manual PDF to generate common question/answers',
customer_reviews,
manuals
) AS prompt,
FROM `my_dataset.reviews_multimodal`
),
STRUCT("question_answer ARRAY" AS output_schema)
);
L’argument rapide de AI.GENERATE_TABLE Dans cette requête utilise trois entrées principales:
- Une instruction textuelle au modèle pour générer des questions communes fréquemment posées
- Le
customer_reviewscolonne (une chaîne avec commentaire textuel agrégé) - Le
manuals ObjectRefcolonne, liant directement au manuel du produit PDF
La fonction utilise une colonne de texte non structurée et Le PDF sous-jacent stocké en GCS pour effectuer l’opération AI. La sortie est un ensemble de paires de questions / réponses précieuses qui aident les clients potentiels à mieux comprendre le produit:
Extension de l’utilitaire d’Objecterf
Nous pouvons facilement incorporer des actifs multimodaux supplémentaires en ajoutant plus ObjectRef colonnes à notre table. Poursuivant avec le scénario de commerce électronique, nous ajoutons un ObjectRef colonne appelée product_imagequi fait référence à l’image du produit officiel affichée sur le site Web.
Et depuis ObjectRefS sont des types de données struct, ils prennent en charge la nidification avec des tableaux. Ceci est particulièrement puissant pour les scénarios où un enregistrement principal concerne plusieurs objets non structurés. Par exemple, un customer_images la colonne pourrait être un tableau de ObjectRefS, chacun pointant vers une autre image de produit téléchargée par le client stockée dans GCS.
Cette capacité à modéliser de manière flexible les relations un à un et un à plusieurs entre les enregistrements structurés et divers objets de données non structurés (dans BigQuery et en utilisant SQL!) Ouvre des possibilités analytiques qui nécessitaient auparavant plusieurs outils externes.
Fonctions AI spécifiques au type
AI.GENERATE Les fonctions offrent une flexibilité dans la définition des schémas de sortie, mais pour les tâches analytiques courantes qui nécessitent des sorties fortement typées, BigQuery offre des fonctions d’IA spécifiques au type. Ces fonctions peuvent analyser le texte ou ObjectRefs avec un LLM et retournez la réponse en tant que structure directement à BigQuery.
Voici quelques exemples:
- Ai.generate_booL: traite l’entrée (texte ou objectrefs) et renvoie une valeur bool, utile pour l’analyse des sentiments ou toute détermination vraie / fausse.
- Ai.generate_int: Renvoie une valeur entière, utile pour extraire des dénombrements numériques, des notes ou des attributs basés sur des entiers quantifiables à partir de données.
- Ai.generate_double: Renvoie un numéro de point flottant, utile pour extraire des scores, des mesures ou des valeurs financières.
Le principal avantage de ces fonctions spécifiques au type est leur application des types de données de sortie, garantissant des résultats scalaires prévisibles (par exemple booléens, entiers, doubles) à partir d’entrées non structurées en utilisant un SQL simple.
S’appuyant sur notre exemple de commerce électronique, imaginez que nous voulons signaler rapidement les avis sur les produits qui mentionnent les problèmes d’expédition ou d’emballage. Nous pouvons utiliser AI.GENERATE_BOOL Pour cette classification binaire:
SQL
SELECT *
FROM `my_dataset.reviews_table`
AI.GENERATE_BOOL(
prompt => ("The review mentions a shipping or packaging problem", customer_reviews),
connection_id => "us-central1.conn");
La requête filtre et renvoie les lignes qui mentionnent les problèmes avec l’expédition ou l’emballage. Notez que nous avons fait pas doivent spécifier des mots clés (par exemple, «cassé», «endommagé») – ce sens sémantique dans chaque revue est examiné par le LLM.
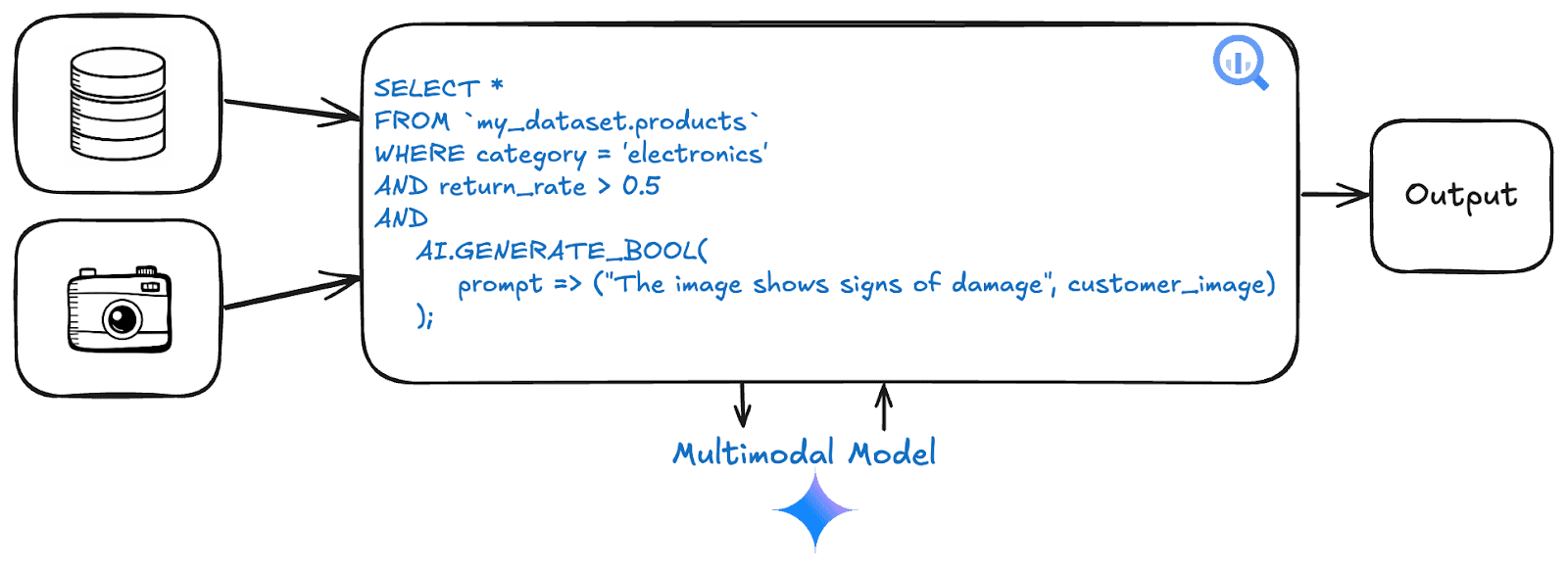
Rassembler tout cela: une requête multimodale unifiée
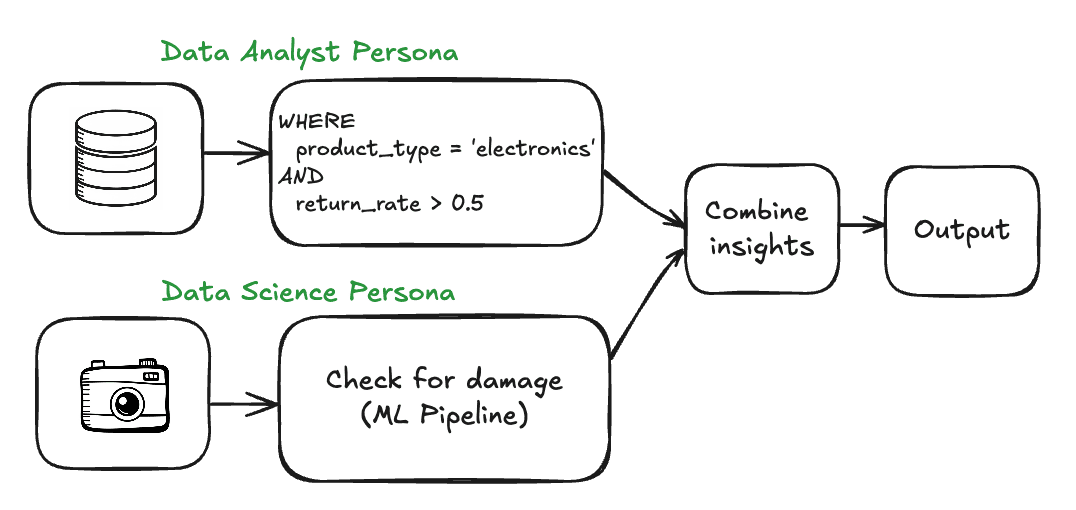
Nous avons exploré comment l’IA générative améliore les capacités de la plate-forme de données. Maintenant, révisons le défi du commerce électronique posé dans l’introduction: « Identifiez les produits électroniques avec des taux de retour élevés liés aux photos des clients montrant des signes de dommages à l’arrivée. » Historiquement, cela nécessitait des pipelines distincts et s’étendait souvent sur plusieurs personnages (data scientist, analyste de données, ingénieur de données).
Avec des capacités d’IA intégrées, une élégante requête SQL peut désormais répondre à cette question:
Cette requête unifiée montre une évolution significative du fonctionnement des plates-formes de données. Au lieu de simplement stocker et récupérer des types de données variés, la plate-forme devient un environnement actif où les utilisateurs peuvent poser des questions commerciales et retourner des réponses en analysant directement les données structurées et non structurées côte à côte, en utilisant une interface SQL familière. Cette intégration offre un chemin plus direct vers les informations qui nécessitaient auparavant une expertise et un outillage spécialisés.
Raisonnement sémantique avec moteur de requête IA (à venir bientôt)
Tandis que des fonctions comme AI.GENERATE_TABLE sont puissants pour le traitement de l’IA en ligne (enrichir les enregistrements individuels ou en générer de nouvelles données), BigQuery vise également à intégrer un raisonnement plus holistique et sémantique avec un moteur de requête AI (AIQE).
L’objectif de l’AIQE est de responsabiliser les analystes de données, même ceux sans expertise en IA profonde, d’effectuer un raisonnement sémantique complexe sur des ensembles de données entiers. L’AIQE y parvient en abstraction de complexités comme l’ingénierie rapide et permet aux utilisateurs de se concentrer sur la logique métier.
Les échantillons de fonctions AIQE peuvent inclure:
- Ai.si: pour le filtrage sémantique. Un LLM évalue si les données d’une ligne s’alignent sur une condition de langage naturel dans l’invite (par exemple, les «revues de retour des produits qui soulèvent des préoccupations concernant la surchauffe»).
- Join: rejoint des tables en fonction de la similitude sémantique ou des relations exprimées en langage naturel – pas seulement l’égalité explicitement clé (par exemple, «Lien des billets de support client vers des sections pertinentes dans la base de connaissances de votre produit»)
- Ai.score: classe ou commande des lignes selon la façon dont ils correspondent à une condition sémantique, utile pour les scénarios «top-k» (par exemple «Trouver les 10 meilleurs appels de support client»).
Conclusion: la plate-forme de données en évolution
Les plates-formes de données restent dans un état d’évolution continu. D’après les origines centrées sur la gestion des données relationnelles structurées, ils adoptent désormais les opportunités présentées par des données multimodales non structurées. L’intégration directe des opérateurs SQL alimentés par AI et la prise en charge des références à des fichiers arbitraires dans les magasins d’objets avec des mécanismes comme ObjectRef représentent un changement fondamental dans la façon dont nous interagissons avec les données.
Alors que les lignes entre la gestion des données et l’IA continuent de converger, l’entrepôt de données reste le centre central des données d’entreprise – désormais imprégnés de la capacité de comprendre de manière plus riche et plus humaine. Des questions multimodales complexes qui nécessitaient autrefois des outils disparates et une vaste expertise en IA peuvent désormais être abordées avec une plus grande simplicité. Cette évolution vers des plateformes de données plus capables continue de démocratiser des analyses sophistiquées et permet à une gamme plus large d’utilisateurs de SQL de dériver des informations profondes.
Pour explorer ces capacités et commencer à travailler avec des données multimodales dans BigQuery:
Auteur: Jeff Nelson, ingénieur des relations avec les développeurs, Google Cloud
Source link



