
Détection de texte Ghostwritten par de grands modèles de langue – Le blog de recherche de Berkeley Artificial Intelligence Research
- Intelligence Artificielle
 Noesis News
Noesis News- 0
- 15 minutes de lecture
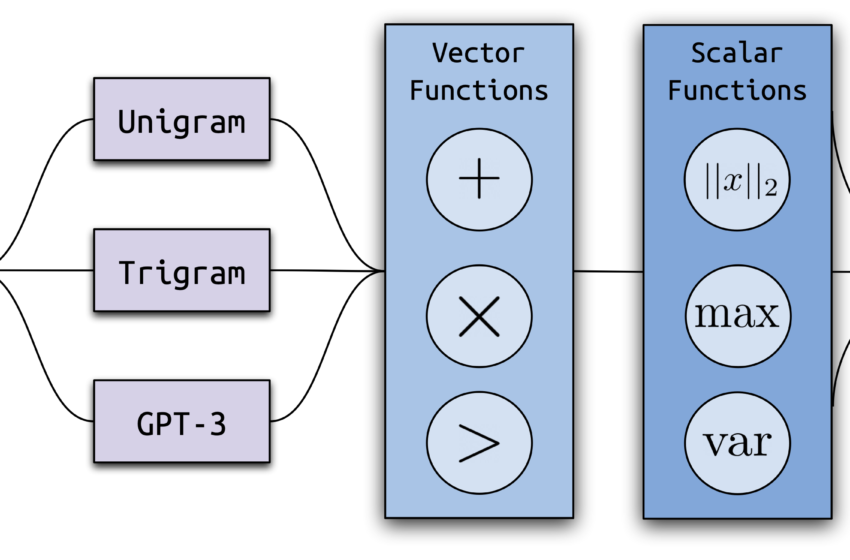




La structure de Ghostbuster, notre nouvelle méthode de pointe pour détecter le texte généré par l’IA.
De grands modèles de langue comme Chatgpt écrivent de manière impressionnante – bien, en fait, qu’ils sont devenus un problème. Les élèves ont commencé à utiliser ces modèles pour les affectations de Ghostwrite, amenant certaines écoles à interdire Chatgpt. En outre, ces modèles sont également sujets à la production de texte avec des erreurs factuelles, donc les lecteurs méfiants peuvent vouloir savoir si des outils d’IA génératifs ont été utilisés pour les articles de presse fantômes ou d’autres sources avant de leur faire confiance.
Que peuvent faire les enseignants et les consommateurs? Les outils existants pour détecter le texte généré par l’AI-Faire sont parfois mal sur des données qui diffèrent de ce sur quoi ils ont été formés. De plus, si ces modèles classent faussement l’écriture humaine réelle comme générée par l’AI, ils peuvent compromettre les étudiants dont le véritable travail est remis en question.
Notre article récent Présentation de Ghostbuster, une méthode de pointe pour détecter le texte généré par l’AI. Ghostbuster fonctionne en trouvant la probabilité de générer chaque jeton dans un document sous plusieurs modèles de langage plus faibles, puis en combinant des fonctions basées sur ces probabilités en entrée dans un classificateur final. Ghostbuster n’a pas besoin de savoir quel modèle a été utilisé pour générer un document, ni la probabilité de générer le document sous ce modèle spécifique. Cette propriété rend Ghostbuster particulièrement utile pour détecter le texte potentiellement généré par un modèle inconnu ou un modèle de boîte noire, tels que les modèles commerciaux populaires Chatgpt et Claude, pour lesquels les probabilités ne sont pas disponibles. Nous sommes particulièrement intéressés à garantir que Ghostbuster se généralise bien, nous avons donc évalué sur une gamme de façons dont le texte pourrait être généré, y compris différents domaines (en utilisant des ensembles de données nouvellement collectés d’essais, d’actualités et d’histoires), de modèles de langue ou d’invites.

Exemples de texte réduit par l’homme et généré par l’AI de nos ensembles de données.
Pourquoi cette approche?
De nombreux systèmes de détection de texte générés par l’AI-AI sont fragiles pour classer différents types de texte (par exemple, une écriture différente stylesou génération de texte différente modèles ou invite). Modèles plus simples qui utilisent perplexité Seul ne peut généralement pas capturer des fonctionnalités plus complexes et faire particulièrement mal sur de nouveaux domaines d’écriture. En fait, nous avons constaté qu’une ligne de base de perplexité était pire que le hasard dans certains domaines, y compris les données de haut-parleurs anglais non indigènes. Pendant ce temps, les classificateurs basés sur de grands modèles de langue comme Roberta capturent facilement des caractéristiques complexes, mais une surfiance sur les données d’entraînement et généralisant mal: nous avons constaté qu’une ligne de base de Roberta avait des performances de généralisation catastrophiques du pire des cas, parfois pire encore qu’une ligne de base perplexité uniquement. Méthodes zéro-shot qui classent le texte sans formation sur les données étiquetées, en calculant la probabilité que le texte ait été généré par un modèle spécifique, a également tendance à faire mal lorsqu’un modèle différent a été réellement utilisé pour générer le texte.
Comment fonctionne Ghostbuster
Ghostbuster utilise un processus de formation en trois étapes: calcul des probabilités, sélection des fonctionnalités et formation des classificateurs.
Probabilités informatiques: Nous avons converti chaque document en une série de vecteurs en calculant la probabilité de générer chaque mot dans le document sous une série de modèles de langage plus faibles (un modèle d’unigram, un modèle de trigramme et deux modèles GPT-3 non réglés sans instruction, ADA et Davinci).
Sélection des fonctionnalités: Nous avons utilisé une procédure de recherche structurée pour sélectionner les fonctionnalités, qui fonctionne en (1) définissant un ensemble d’opérations vectorielles et scalaires qui combinent les probabilités, et (2) la recherche de combinaisons utiles de ces opérations en utilisant la sélection des fonctionnalités avant, ajoutant à plusieurs reprises la meilleure fonctionnalité restante.
Formation du classificateur: Nous avons formé un classificateur linéaire sur les meilleures fonctionnalités basées sur la probabilité et certaines fonctionnalités supplémentaires sélectionnées manuellement.
Résultats
Lorsqu’elle est formée et testée sur le même domaine, Ghostbuster a atteint 99,0 F1 sur les trois ensembles de données, surpassant GPTZero par une marge de 5,9 F1 et DetectGPT par 41,6 F1. Hors du domaine, Ghostbuster a atteint 97,0 F1 en moyenne dans toutes les conditions, surpassant le détectgpt par 39,6 F1 et GPTZero par 7,5 F1. Notre base de Roberta a atteint 98,1 F1 lorsqu’il est évalué dans un domaine dans tous les ensembles de données, mais ses performances de généralisation étaient incohérentes. Ghostbuster a surpassé la ligne de base de Roberta sur tous les domaines, à l’exception de l’écriture créative hors du domaine, et a eu une bien meilleure performance hors du domaine que Roberta en moyenne (marge de 13,8 F1).


Résultats sur les performances dans le domaine et hors du domaine de Ghostbuster.
Pour s’assurer que Ghostbuster est robuste à la gamme des façons dont un utilisateur pourrait inviter un modèle, comme demander différents styles d’écriture ou niveaux de lecture, nous avons évalué la robustesse de Ghostbuster à plusieurs variantes rapides. Ghostbuster a surpassé toutes les autres approches testées sur ces variantes rapides avec 99,5 F1. Pour tester la généralisation entre les modèles, nous avons évalué les performances sur le texte généré par Claudeoù Ghostbuster a également surperformé toutes les autres approches testées avec 92,2 F1.
Les détecteurs de texte générés par l’AI ont été dupés en modifiant légèrement le texte généré. Nous avons examiné la robustesse de Ghostbuster aux modifications, telles que l’échange de phrases ou de paragraphes, de réorganiser les caractères ou de remplacer les mots par des synonymes. La plupart des changements au niveau de la phrase ou du paragraphe n’ont pas affecté de manière significative les performances, bien que les performances aient diminué en douceur si le texte a été modifié par paraphrase répété, en utilisant des évaders de détection commerciale tels que l’IA indétectable ou de nombreuses changements au niveau des mots ou des caractéristiques. Les performances étaient également les meilleures sur des documents plus longs.
Depuis les détecteurs de texte générés par AI peut classifier mal Le texte des anglophones non natifs en tant que généré par l’IA, nous avons évalué les performances de Ghostbuster sur l’écriture des anglophones non natifs. Tous les modèles testés avaient une précision de plus de 95% sur deux des trois ensembles de données testés, mais ont fait pire sur le troisième ensemble d’essais plus courts. Cependant, la longueur du document peut être le principal facteur ici, car Ghostbuster fait presque aussi bien sur ces documents (74,7 F1) que sur d’autres documents hors du domaine d’une longueur similaire (75,6 à 93,1 F1).
Les utilisateurs qui souhaitent appliquer Ghostbuster à des cas réels d’utilisation potentielle interdite de la génération de texte (par exemple, les essais étudiants-écrits par Chatgpt) devraient noter que les erreurs sont plus susceptibles pour des textes plus courts, des domaines loin des conférenciers non natifs de l’anglais, des modèles de modèles humains ou du texte généré par la promotion d’un modèle AI pour modifier un humain. Pour éviter de perpétuer les dommages algorithmiques, nous décourageons fortement la pénalisation automatiquement de l’utilisation présumée de la génération de texte sans supervision humaine. Au lieu de cela, nous recommandons une utilisation prudente et humaine en boucle de Ghostbuster si la classification de l’écriture de quelqu’un en tant que Génération AI pourrait leur faire du mal. Ghostbuster peut également aider avec une variété d’applications à risque à moindre risque, notamment le filtrage du texte généré par l’IA des données de formation du modèle de langue et la vérification si les sources d’informations en ligne sont générées par l’IA.
Conclusion
Ghostbuster est un modèle de détection de texte généré par l’AI-AI de pointe, avec des performances de 99,0 F1 à travers les domaines testés, représentant des progrès substantiels par rapport aux modèles existants. Il se généralise bien à différents domaines, invites et modèles, et il est bien adapté à l’identification du texte de la boîte noire ou des modèles inconnus car il ne nécessite pas d’accès aux probabilités du modèle spécifique utilisé pour générer le document.
Les orientations futures pour Ghostbuster comprennent la fourniture d’explications pour les décisions du modèle et l’amélioration de la robustesse aux attaques qui essaient spécifiquement de tromper les détecteurs. Les approches de détection de texte générées par l’AI-AI peuvent également être utilisées aux côtés d’alternatives telles que filigrane. Nous espérons également que Ghostbuster pourra aider à travers une variété d’applications, telles que le filtrage des données de formation du modèle de langue ou signaler le contenu généré par l’IA sur le Web.
Essayez Ghostbuster ici: ghostbuster.app
En savoir plus sur Ghostbuster ici: ( papier ) (code)
Essayez de deviner si le texte est généré par AI ici: ghostbuster.app/experiment
Source link



