
(D) Mise en œuvre des instantanés GPU pour couper les départs à froid pour les grands modèles de 12x
- Intelligence Artificielle
 Noesis News
Noesis News- 0
- 3 minutes de lecture
|
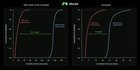
Les instantanés GPU sont enfin une chose! Nvidia a récemment publié leur API CUDA Checkpoint / Restore Et nous, chez Modal (plate-forme de calcul sans serveur), réduisons considérablement les heures de début à froid GPU. Ceci est particulièrement pertinent pour servir de grands modèles, où il peut prendre des minutes (pour les LLM les plus froides) pour déplacer les poids du modèle du disque à la mémoire. Les instantanés de mémoire GPU peuvent réduire les temps de démarrage à froid jusqu’à 12x. Il vous permet d’étendre les ressources GPU de haut en bas en fonction de la demande sans compromettre la latence destinée aux utilisateurs. Vous trouverez ci-dessous quelques résultats comparatifs montrant des améliorations pour divers modèles! En savoir plus sur le fonctionnement des instantanés GPU plus des références supplémentaires dans cet article de blog: https://modal.com/blog/gpu-mem-snapshots soumis par / u / Crookedstairs |




{kind=link}