
(D) Comment comparer équitablement les méthodes de formation de l’IA lorsqu’elles produisent différentes tailles de population?
- Intelligence Artificielle
 Noesis News
Noesis News- 0
- 5 minutes de lecture
|
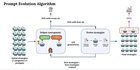
Hé! Je travaille sur un journal de conférence sur la formation des modèles d’IA et j’ai atteint un problème de conception expérimental délicat sur lequel j’aimerais votre contribution. Tl; dr: Je compare deux méthodes d’optimisation LLM qui produisent des populations finales de 35 vs 600. Comment puis-je mesurer équitablement le mieux? La vue d’ensemble J’utilise un algorithme évolutif qui évolue LLM invite à un objectif (persuassivité vs véracité dans mon cas). J’utilise un tournoi de débat pour déterminer l’aptitude des invites sur une tâche de compréhension en lecture, puis les évoluer pour être plus convaincants / véridiques via un mutateur. Implémentation de l’évolution: Formation de persuasion: Les stratégies de débat individuelles participent aux tournois. Les gagnants avancent, les perdants sont éliminés et remplacés par des versions évoluées. Formation à la vérité: Des paires de stratégies fonctionnent en équipe et se font marquer ensemble (leur objectif est de "surface" la vérité dans le débat). Ils gagnent lorsque le juge choisit la bonne réponse (pas seulement quand ils semblent convaincants). Les deux commencent par des graines identiques: 7 catégories de stratégies de débat (comme "Appel émotionnel," "Autorité," "Rationalité") avec 5 invites spécifiques dans chaque catégorie (35 au total). Le problème Pour exécuter mes tournois évolutifs, pour l’optimisation de la vérité, j’associe les stratégies les unes aux autres, ce qui se traduit par 2 tailles de population très différentes (35 pour la persuasion vs 595 pour la vérité). Dans l’étape d’évolution, les membres d’une paire sont mutés ensemble (le mutateur génère une invite + B). Maintenant, je veux comparer quelle approche produit de meilleurs résultats, mais comment comparez-vous équitablement 35 contre 600 stratégies? Solutions possibles auxquelles j’ai pensé: – Moyennes de catégorie: Comparez les performances moyennes de chaque catégorie de stratégie (l’attrait émotionnel optimisé par la persuasion vs l’attrait émotionnel optimisé de vérité, etc.). Pour la vérité, je prends la performance moyenne de toutes les stratégies jumelées dans une catégorie particulière. (semble compliqué, et je ne mesure pas les invites, ce que j’ai optimisé directement) – Top-K Performer: Comparez le K supérieur de chaque approche (k = 20 signifie 57% de la population de persuasion contre 3% de la population de vérité – semble injuste?) – genre de pommes à pommes: Faire des identifiants pour les stratégies d’origine et les utiliser pour en moyenne les performances du membre de la paire de vérité – cartographier efficacement les performances par paires à la performance individuelle. (Mais cela jette l’aspect collaboratif principal de la formation de vérité?) – autre chose entièrement? Mes questions: Quelle méthode de comparaison serait la plus saine méthodologique? Y a-t-il des pratiques établies pour comparer les résultats d’optimisation avec différentes structures de population? Y a-t-il une façon fondamentalement meilleure de cadrer cette comparaison qui me manque? Toutes les idées seraient extrêmement appréciées! soumis par / u / hot_letter5239 |




{kind=link}