
(D) Appliquer un raisonnement continu de noix de coco dans une couche linéaire apprise qui produit des paramètres d’échantillonnage (TEMP, TOP-K, TOP-P, etc.) pour le jeton actuel?
- Intelligence Artificielle
 Noesis News
Noesis News- 0
- 7 minutes de lecture
|
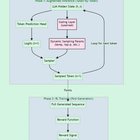
Salut les gens, une nouvelle expérience de pensée a détourné mon cerveau et j’espère obtenir vos commentaires avant d’aller trop loin dans le terrier du lapin et de me sentir isolé. Mon dernier article sur l’utilisation de RL pour la compression sans perte a été accueilli avec un grand engagement qui m’a aidé à me sentir moins comme si je criais dans le vide. En espérant que vous pourrez m’aider à nouveau. L’idée principale est la suivante: que se passe-t-il si un LLM pouvait apprendre à moduler dynamiquement ses propres paramètres d’échantillonnage (température, Top-P, Top-K) pendant La génération d’une seule réponse? Au lieu d’une température statique et prédéfinie, le modèle apprendrait à décider, jeton par-token, quand être créatif et quand être précis. Le concept: le déclenchement d’apprentissage de l’échantillonnage Nous avons vu des progrès incroyables du raisonnement continu de manière en boucle (noix de coco) où les états cachés finaux sont la contribution pour le jet suivant, permettant au modèle d’élaborer des politiques sur la gestion de son état. Ma proposition s’appuie sur cela en proposant que la pensée continue a également la capacité de prédire et de gouverner les paramètres d’échantillonnage qui s’ensuivent à la fin de chaque passe avant, plutôt que de le laisser à des valeurs fixes. Processus / méthode de formation proposée Cela pourrait être formulé comme un problème RL, en tirant parti de GRPO. Cela pourrait ressembler à ceci:
Cela ne met pas à niveau la puissance d’un modèle de base, mais en particulier de RL lui-même. Le modèle reçoit essentiellement un nouvel outil et peut apprendre à l’utiliser afin d’explorer de manière optimale l’espace latent au cours des déploiements, une plus grande couverture pour le moins de déploiement. L’effet possible de RL devient considérablement plus intéressant. De plus, lorsque le modèle est ramené sur une nouvelle tâche avec un tel échantillonneur de noix de coco déjà formé, il peut alors apprendre de nouvelles tâches de façon spectaculaire car elle effectue une exploration plus diversifiée sur son espace latent. Cette méthode peut également permettre aux modèles de fonctionner beaucoup mieux dans les tâches créatives ou d’être plus créatives à l’inférence, en développant une dynamique d’échantillonnage plus complexe. Pourquoi cela pourrait fonctionner (et les liens avec la recherche existante) Ce n’est pas entièrement hors du champ gauche. Il résonne avec quelques concepts existants, tels que Échantillonnage de température dynamique basé sur l’entropie (ArXIV: 2403.14541) a exploré la température d’ajustement dynamique en fonction de l’entropie de la distribution de jetons pour équilibrer la qualité et la diversité. Ma proposition suggère de faire de ceci un Politique apprise et orientée vers les objectifs plutôt qu’une heuristique fixe et heuristique. En entraînant le modèle pour contrôler sa propre inférence, nous pourrions débloquer une forme de raisonnement plus efficace et nuancée – une forme qui peut se déplacer fluide entre l’exploration et l’exploitation dans un seul processus de pensée cohérent. Je pense que cela devrait fonctionner et cela semble sauvage si cela fonctionne! Plus de réglage hyperparamètre, laissez le modèle déterminer une politique, alignée sur son espace latent à travers la méthode de la noix de coco. Cela semble être un chemin viable pour moi! Qu’en penses-tu? Discutons et voyons si nous pouvons construire sur cela. soumis par / u / psychonucks |




{kind=link}