
Construisez un pipeline de nettoyage et de validation des données en moins de 50 lignes de Python
- Intelligence Artificielle
 Noesis News
Noesis News- 0
- 13 minutes de lecture

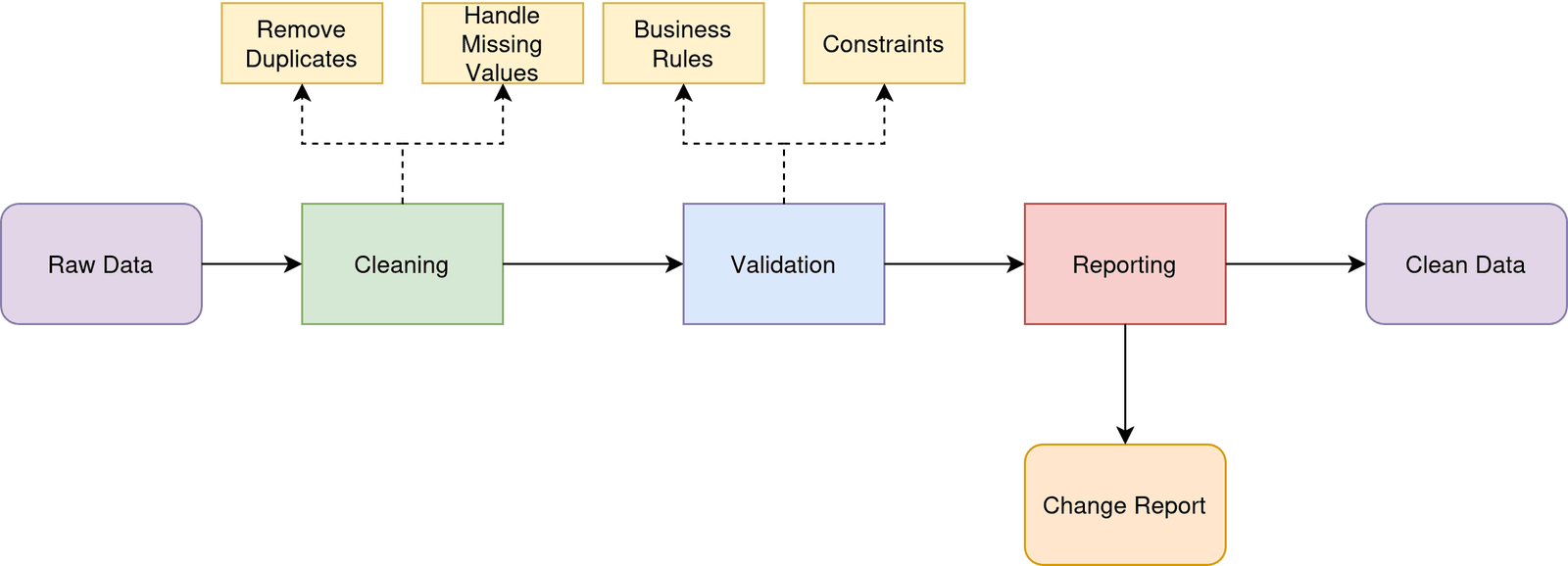

Image de l’auteur | Idéogramme
Les données sont désordonnées. Ainsi, lorsque vous tirez des informations des API, en analysant des ensembles de données du monde réel, etc., vous vous comprenez inévitablement en doublons, des valeurs manquantes et des entrées non valides. Au lieu d’écrire le même code de nettoyage à plusieurs reprises, un pipeline bien conçu fait gagner du temps et assure la cohérence dans vos projets de science des données.
Dans cet article, nous allons construire un pipeline de nettoyage et de validation réutilisable qui gère les problèmes communs de qualité des données tout en fournissant des commentaires détaillés sur ce qui a été corrigé. À la fin, vous aurez un outil qui peut nettoyer les ensembles de données et les valider contre les règles métier dans quelques lignes de code.
🔗 Lien vers le code sur github
Pourquoi les pipelines de nettoyage des données?
Pensez aux pipelines de données comme les lignes de montage dans la fabrication. Chaque étape remplit une fonction spécifique, et la sortie d’une étape devient l’entrée de la suivante. Cette approche rend votre code plus maintenable, testable et réutilisable sur différents projets.
Un pipeline de nettoyage de données simple
Image de l’auteur | diagrams.net (draw.io)
Notre pipeline s’occupera de trois responsabilités de base:
- Nettoyage: Retirez les doublons et gérez les valeurs manquantes (utilisez-le comme point de départ. Vous pouvez ajouter autant d’étapes de nettoyage au besoin.)
- Validation: Assurez-vous que les données répondent aux règles commerciales et aux contraintes
- Rapports: suivre les modifications apportées pendant le traitement
Configuration de l’environnement de développement
Veuillez vous assurer que vous utilisez une version récente de Python. Si vous utilisez localement, créez un environnement virtuel et installez les packages requis:
Vous pouvez également utiliser Google Colab ou des environnements de ordinateurs portables similaires si vous préférez.
Définition du schéma de validation
Avant de pouvoir valider les données, nous devons définir à quoi ressemble « valide ». Nous utiliserons Pydontic, une bibliothèque Python qui utilise des conseils de type pour valider les types de données.
class DataValidator(BaseModel):
name: str
age: Optional(int) = None
email: Optional(str) = None
salary: Optional(float) = None
@field_validator('age')
@classmethod
def validate_age(cls, v):
if v is not None and (v < 0 or v > 100):
raise ValueError('Age must be between 0 and 100')
return v
@field_validator('email')
@classmethod
def validate_email(cls, v):
if v and '@' not in v:
raise ValueError('Invalid email format')
return v
Ce schéma modélise les données attendues en utilisant la syntaxe de Pydontic. Pour utiliser le @field_validator décorateur, vous aurez besoin du @classmethod décorateur. La logique de validation garantit que l’âge tombe dans des limites raisonnables et les e-mails contiennent le symbole ‘@’.
Construire la classe de pipeline
Notre classe de pipeline principale résume toute logique de nettoyage et de validation:
class DataPipeline:
def __init__(self):
self.cleaning_stats = {'duplicates_removed': 0, 'nulls_handled': 0, 'validation_errors': 0}
Le constructeur initialise un dictionnaire statistique pour suivre les modifications apportées pendant le traitement. Cela aide à examiner de plus près la qualité des données et à garder une trace des étapes de nettoyage appliquées au fil du temps.
Écrire la logique de nettoyage des données
Ajoutons un clean_data Méthode pour gérer les problèmes communs de qualité des données comme les valeurs manquantes et les enregistrements en double:
def clean_data(self, df: pd.DataFrame) -> pd.DataFrame:
initial_rows = len(df)
# Remove duplicates
df = df.drop_duplicates()
self.cleaning_stats('duplicates_removed') = initial_rows - len(df)
# Handle missing values
numeric_columns = df.select_dtypes(include=(np.number)).columns
df(numeric_columns) = df(numeric_columns).fillna(df(numeric_columns).median())
string_columns = df.select_dtypes(include=('object')).columns
df(string_columns) = df(string_columns).fillna('Unknown')
Cette approche est intelligente pour gérer différents types de données. Les valeurs manquantes numériques sont remplies de la médiane (plus robuste que la moyenne contre les valeurs aberrantes), tandis que les colonnes de texte obtiennent une valeur d’espace réservé. La suppression en double se produit d’abord pour éviter de fausser nos calculs médians.
Ajout de validation avec suivi des erreurs
L’étape de validation traite chaque ligne individuellement, collectant à la fois des données valides et des informations d’erreur détaillées:
def validate_data(self, df: pd.DataFrame) -> pd.DataFrame:
valid_rows = ()
errors = ()
for idx, row in df.iterrows():
try:
validated_row = DataValidator(**row.to_dict())
valid_rows.append(validated_row.model_dump())
except ValidationError as e:
errors.append({'row': idx, 'errors': str(e)})
self.cleaning_stats('validation_errors') = len(errors)
return pd.DataFrame(valid_rows), errors
Cette approche Row-by Row garantit qu’un mauvais enregistrement ne bloque pas tout le pipeline. Les lignes valides se poursuivent tout au long du processus tandis que les erreurs sont capturées pour examen. Ceci est important dans les environnements de production où vous devez traiter ce que vous pouvez tout en signalant les problèmes.
Orchestrer le pipeline
Le process La méthode attache tout ensemble:
def process(self, df: pd.DataFrame) -> Dict(str, Any):
cleaned_df = self.clean_data(df.copy())
validated_df, validation_errors = self.validate_data(cleaned_df)
return {
'cleaned_data': validated_df,
'validation_errors': validation_errors,
'stats': self.cleaning_stats
}
La valeur de retour est un rapport complet qui comprend les données nettoyées, les erreurs de validation et les statistiques de traitement.
Mettre tout cela ensemble
Voici comment vous utiliseriez le pipeline en pratique:
# Create sample messy data
sample_data = pd.DataFrame({
'name': ('Tara Jamison', 'Jane Smith', 'Lucy Lee', None, 'Clara Clark','Jane Smith'),
'age': (25, -5, 25, 35, 150,-5),
'email': ('taraj@email.com', 'invalid-email', 'lucy@email.com', 'jane@email.com', 'clara@email.com','invalid-email'),
'salary': (50000, 60000, 50000, None, 75000,60000)
})
pipeline = DataPipeline()
result = pipeline.process(sample_data)
Le pipeline supprime automatiquement l’enregistrement en double, gère le nom manquant en le remplissant de «inconnu», remplit le salaire manquant de la valeur médiane et des erreurs de validation des signaux pour l’âge négatif et le courrier électronique non valide.
🔗 Tu peux trouver le script complet sur github.
Prolonger le pipeline
Ce pipeline sert de fondation sur lequel vous pouvez construire. Considérez ces améliorations pour vos besoins spécifiques:
Règles de nettoyage personnalisées: Ajouter des méthodes de nettoyage spécifique au domaine comme la normalisation des numéros de téléphone ou des adresses.
Validation configurable: Rendez le schéma pydante configurable afin que le même pipeline puisse gérer différents types de données.
Gestion des erreurs avancées: Implémentez la logique de réessayer pour les erreurs transitoires ou la correction automatique pour les erreurs courantes.
Optimisation des performances: Pour les grands ensembles de données, envisagez d’utiliser des opérations vectorisées ou un traitement parallèle.
Emballage
Les pipelines de données ne consistent pas seulement à nettoyer les ensembles de données individuels. Il s’agit de construire des systèmes fiables et maintenables.
Cette approche de pipeline garantit la cohérence entre vos projets et facilite l’ajustement des règles commerciales à mesure que les exigences changent. Commencez par ce pipeline de base, puis personnalisez-le pour vos besoins spécifiques.
La clé est d’avoir un système fiable et réutilisable qui gère les tâches banales afin que vous puissiez vous concentrer sur l’extraction d’informations à partir de données propres. Nucyer de données!
Bala Priya C est développeur et écrivain technique d’Inde. Elle aime travailler à l’intersection des mathématiques, de la programmation, de la science des données et de la création de contenu. Ses domaines d’intérêt et d’expertise incluent DevOps, la science des données et le traitement du langage naturel. Elle aime lire, écrire, coder et café! Actuellement, elle travaille sur l’apprentissage et le partage de ses connaissances avec la communauté des développeurs en créant des tutoriels, des guides pratiques, des pièces d’opinion, etc. Bala crée également des aperçus de ressources engageants et des tutoriels de codage.
Source link



