
Construire des LLM partageables personnalisés à l’aide de Node.js et Gemini 2.0 Flash API | par Chordiasahil | Mars 2025
- Intelligence Artificielle
 Noesis News
Noesis News- 0
- 35 minutes de lecture
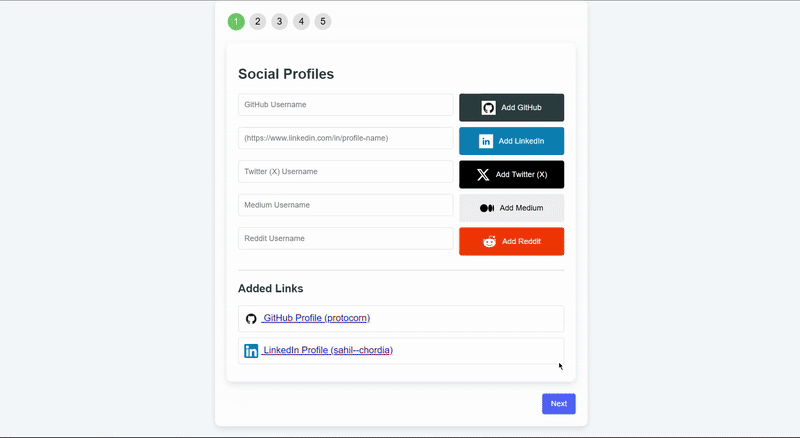
Dans cette section, je vais vous expliquer comment utiliser Mimikree, de l’inscription à l’interaction avec votre modèle d’IA personnalisé. Décomposons-le pas à pas.
1. Enregistrement et connexion
Pour commencer, la première chose que vous devez faire est registre sur la plate-forme. Une fois enregistré, vous pouvez facilement se connecter sur votre compte et commencez à créer votre modèle d’IA personnalisé. Cela garantit que vos données et votre modèle sont en toute sécurité liés à votre compte.
- Backend: Le processus d’enregistrement et de connexion de l’utilisateur est géré via un sécurisé Exprimer serveur (construit sur Node.js). Les données de l’utilisateur, y compris les mots de passe hachés et les informations de base des utilisateurs, sont stockés dans Mongodb pour la persistance.
- Authentification: J’ai exploité la gestion de session sécurisée pour m’assurer que seuls les utilisateurs authentifiés peuvent accéder à leurs modèles personnalisés. Les mots de passe sont en toute sécurité haché à l’aide de méthodes de chiffrement standard sur l’industrie avant le stockage
2. Ajouter vos données
Une fois connectés, les utilisateurs peuvent commencer à ajouter des données pour personnaliser leur modèle d’IA. Ces données peuvent provenir de plusieurs sources:
- Profils de médias sociaux: Les utilisateurs peuvent lier leurs profils de médias sociaux (LinkedIn, Twitter, etc.) pour permettre à leur modèle de se renseigner sur leurs antécédents professionnels.
- Forme d’auto-évaluation: Les formulaires simples permettent aux utilisateurs de fournir des informations sur leurs préférences personnelles, leurs qualifications, leurs intérêts, etc.
- Données PDF: Les utilisateurs peuvent télécharger une variété de documents, y compris les PDF, les curriculum vitae ou d’autres données de texte pertinentes, qui sont ensuite traitées pour extraire des informations significatives.
- Images avec des légendes: Les utilisateurs peuvent également télécharger des images ainsi que des descriptions fournies manuellement. De plus, un modèle de sous-titrage automatisé, Salesforce / Blip-Image-Captioning-Garg (Hébergé sur Visage étreint), est utilisé pour générer des descriptions textuelles pour chaque image. Ces descriptions, ainsi que les URL de l’image, sont stockées pour la récupération contextuelle.
Traitement du backend
- Traitement des documents: Les documents de texte téléchargés sont traités à l’aide du Ballon cadre et converti en intégres vectoriels pour une récupération efficace.
- Traitement d’image: Les images sont d’abord téléchargées sur Nuageuxoù ils sont stockés et leurs URL sont générées. Ces URL, ainsi que les descriptions fournies manuellement ou les légendes générées par l’AI, sont ensuite intégrées et stockées pour la récupération.
- Modèle d’incorporation: Nous utilisons Transformateurs de phrase / All-Mpnet-Base-V2 Pour générer des intégres pour des données textuelles (documents, légendes et descriptions manuelles). Ces intégres permettent une recherche sémantique efficace dans l’ensemble de données de l’utilisateur.
- Pinone pour le stockage vectoriel: Un élément clé du backend est Pignonqui stocke les incorporations vectorielles des légendes de texte et d’image. PineCone permet une recherche de vecteur rapide, permettant à l’IA de récupérer le contexte le plus pertinent lors de la réponse aux requêtes.
Cette approche garantit que les données de texte et visuelles sont parfaitement intégrées dans le modèle d’IA, améliorant sa capacité à générer des réponses pertinentes en fonction de divers formats d’entrée.
3. Interagir avec votre modèle d’IA
Une fois les données ajoutées, les utilisateurs peuvent commencer à interagir avec leur modèle d’IA. Le flux de conversation fonctionne comme suit:
- Interroger le modèle: Lorsqu’un utilisateur envoie une requête, la demande est acheminée via le Exprimer serveur, qui traite l’entrée et le transfère au Ballon backend.
- Récupération de contexte: Le Ballon requêtes de serveur Pignon Pour les intérêts de données pertinents en fonction de l’entrée de l’utilisateur. Pincecone effectue un Recherche de vecteur en utilisant la métrique de similitude du cosinus pour récupérer les documents ou informations les plus contextuellement pertinents.
- Intégration API: Le API Gemini Flash 2.0 est ensuite appelé pour générer une réponse. Cette API utilise le contexte fourni par PineCone, ainsi que les données de l’utilisateur, pour formuler une réponse qui s’aligne sur le ton, le style d’écriture et les préférences de l’utilisateur.
- Génération de réponse: La réponse de Gemini Flash 2.0 est renvoyée au frontend et affichée à l’utilisateur.
Flux backend:
- L’utilisateur envoie une requête.
- La requête est traitée par Exprimer et acheminé vers le Ballon serveur.
- Pignon Récupère le contexte pertinent des intégres vectoriels stockés.
- Gemini Flash 2.0 génère la réponse basée sur le contexte.
- La réponse est renvoyée au Exprimer serveur puis affiché dans le frontend.
3. ingénierie rapide
Un aspect crucial de la capacité de Mimikree à générer des réponses personnalisées et pertinentes réside dans son ingénierie rapide. En fabriquant soigneusement les instructions et le contexte fournis à l’IA, nous nous assurons qu’il comprend l’intention de l’utilisateur et fournit des sorties précises et de type humain. Notre modèle d’invite comprend ces éléments clés:
- Personnage: Définition de l’identité de l’IA (par exemple, ‘vous êtes {nom}’).
- Type d’interaction: Adapter la réponse en fonction de la relation de l’utilisateur avec le créateur du modèle.
- Contexte: Fourniture des données pertinentes récupérées à partir de Pinecone.
- Instructions: Guider le style et le format de réponse de l’IA.
- Arrière-plan: Fournir les données d’auto-évaluation.
- Histoire de la conversation: Fournir un contexte de conversation précédent.
- Question de l’utilisateur: La requête utilisateur actuelle.
- Manipulation de l’URL nuageuse: Instructions spéciales pour les liens d’image.
Voici un exemple du modèle d’invite:
prompt_template = ChatPromptTemplate.from_template(
"You are {name} responding as yourself.nn"
"### Interaction Type ### n"
"{interaction} nn""### Profile Information ###n"
"{context}nn"
"### Instructions ###n"
"- Introduce yourself as {name} whenever necessary.n"
"- Respond as a real person, not as an AI.n"
"- Match the user's tone, phrasing, and vocabulary naturally.n"
"- If the user specifies a tone, style, or format, strictly follow it.n"
"- Ensure accuracy and do not assume facts beyond the given data.n"
"- If relevant information is unavailable, respond naturally without making up details.n"
"- Use Markdown formatting where appropriate (e.g., for lists, headings, code blocks, etc.) to structure your response and improve readability.nn"
"### {name}'s Background ###n"
"{background}nn"
"### Previous Conversation ###n"
"{history}nn"
"### User's Current Question ###n"
"{question}nn"
"### Your Response ###"
)
if my_model:
interaction_type = (f"You are talking with your creator/owner. Respond in a more personal, familiar way since this is {username} who created you."
f"Note: When {username} says 'my' or 'mine', they are referring to their own things. "
)
else:
interaction_type = f"You are talking with someone who is not your creator. This is some user who is interacting with you"
4. discuter avec les modèles d’autres utilisateurs
Mimikree permet aux utilisateurs de partager leurs liens de modèle personnalisés, permettant aux autres d’interagir avec leur modèle d’IA. Voici comment cela fonctionne:
- Partage de modèles: Les utilisateurs peuvent partager un lien unique vers leur modèle d’IA, qui est lié à leurs données et préférences personnelles.
- Interagir avec des modèles partagés: Lorsqu’un autre utilisateur interagit avec le modèle partagé, le Ballon le serveur traite l’entrée, récupère le contexte pertinent à partir de Pignonet génère une réponse en utilisant le API Gemini Flash 2.0 – tout comme pour le propriétaire du modèle.
- Flux backend: Le processus d’interaction avec le modèle d’un autre utilisateur est identique à l’interaction avec son propre modèle, mais avec des données spécifiques au modèle partagé.
5. Intégration du calendrier Google
L’une des fonctionnalités les plus puissantes de Mimikree est la possibilité de se synchroniser avec Google Calendar pour répondre avec précision aux requêtes liées à la disponibilité.
- Intégration: Les utilisateurs peuvent connecter leur calendrier Google à leur profil Mimikree via Authentification OAuth 2.0assurer un accès sécurisé à leurs données de calendrier.
- Manipulation de la requête: Lorsqu’un utilisateur interroge son modèle sur la disponibilité, le Backend flacon fait un appel API à la API du calendrier Google Pour récupérer les événements de l’utilisateur et déterminer les plages horaires disponibles.
Défi de manipulation du fuseau horaire
- Un défi clé dans les requêtes de disponibilité est gérer différents fuseaux horaires.
- Par exemple, si un utilisateur dans le États-Unis (EDT) ajoute un événement à son calendrier, mais quelqu’un Inde (IST) requêtes leur disponibilité, les heures de l’événement doivent être converties de manière appropriée.
- Pour assurer la précision, Le fuseau horaire de l’utilisateur de requête et le fuseau horaire du propriétaire du modèle sont pris en compte.
- Cela empêche l’interprétation erronée des temps d’événements et garantit que la planification reste exacte dans différentes régions.
Considérations de confidentialité
- À maintenir la vie privéele modèle AI récupère seulement horaires des événements et fait pas divulguer les détails de l’événement ou les objectifs à d’autres utilisateurs.
- Cela garantit que bien que la disponibilité soit partagée, des informations sensibles sur les réunions ou les événements personnels restent confidentielles.
Flux backend
- L’utilisateur demande la disponibilité.
- La requête déclenche une demande au API du calendrier Google pour récupérer l’horaire de l’utilisateur.
- Le modèle traite les données du calendrier, en considérant différences de fuseau horaire entre l’utilisateur de requête et le propriétaire du modèle.
- Une réponse est générée, montrant les plages horaires disponibles tout en garantissant Confidentialité de l’événement.
- Les informations de disponibilité sont renvoyées au frontend pour l’affichage.
Cette fonction permet à Mimikree de servir d’assistant de planification intelligent, permettant une coordination transparente dans différents fuseaux horaires tout en hiérarchisant la confidentialité des utilisateurs.
Maintenant que vous comprenez le processus, voyez-le en action. Cette vidéo de démonstration vous montrera Mimikree v1.0 en action:
En résumé, Mimikree Vous permet de créer une IA personnalisée et partageable qui reflète vraiment votre identité unique. Avec des fonctionnalités comme sans couture intégration des donnéesintelligent Calendrier Google synchronisation et avancée ingénierie rapideMimikree propose une approche révolutionnaire de la présence en ligne.
Essayez Mimikree aujourd’hui et expérimentez l’avenir de AI personnalisé! Créez votre propre modèle Mimikree et partagez votre moi numérique unique avec le monde. Je travaille continuellement à améliorer Mimikree et à explorer de nouvelles possibilités d’IA personnalisée. Restez à l’écoute pour des mises à jour et des fonctionnalités passionnantes à l’avenir. Merci d’avoir pris le temps de se renseigner sur Mimikree. Nous sommes ravis de voir comment vous l’utilisez pour créer votre propre présence numérique unique.



