
Configuration d’un pipeline d’apprentissage automatique sur Google Cloud Platform
- Intelligence Artificielle
 Noesis News
Noesis News- 0
- 19 minutes de lecture

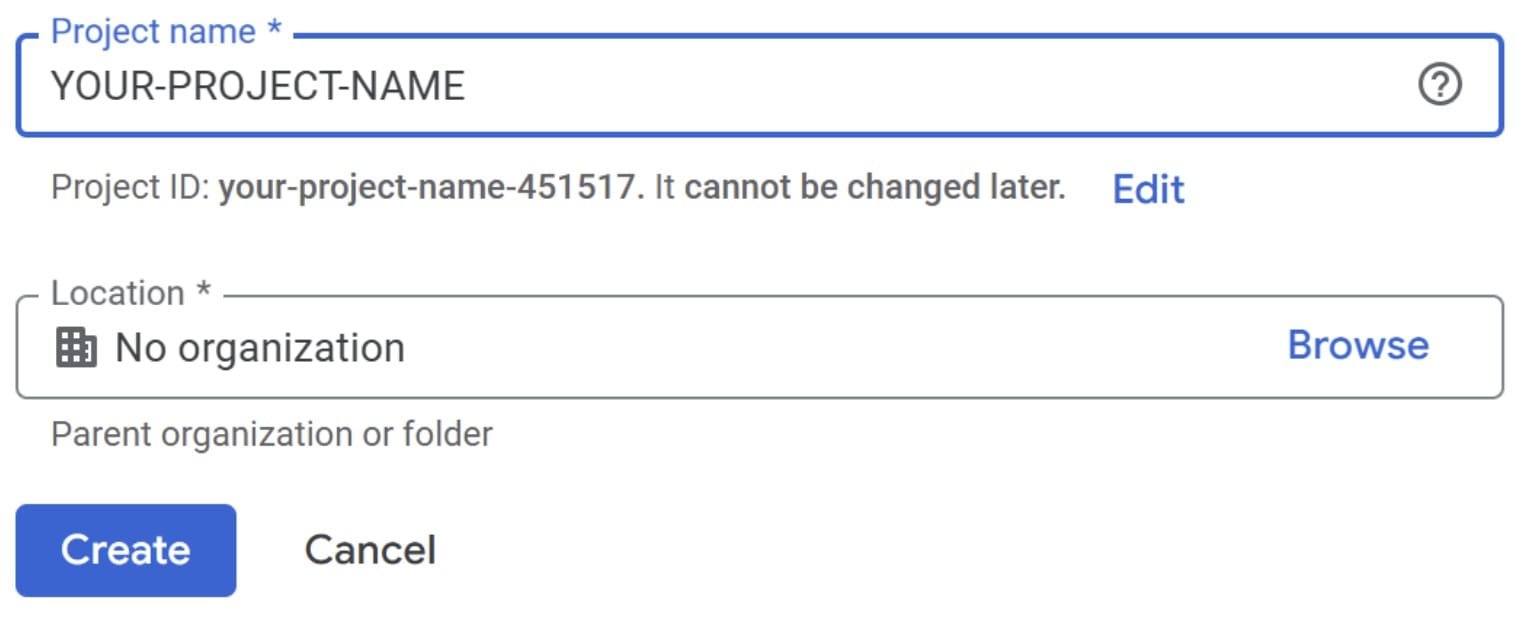

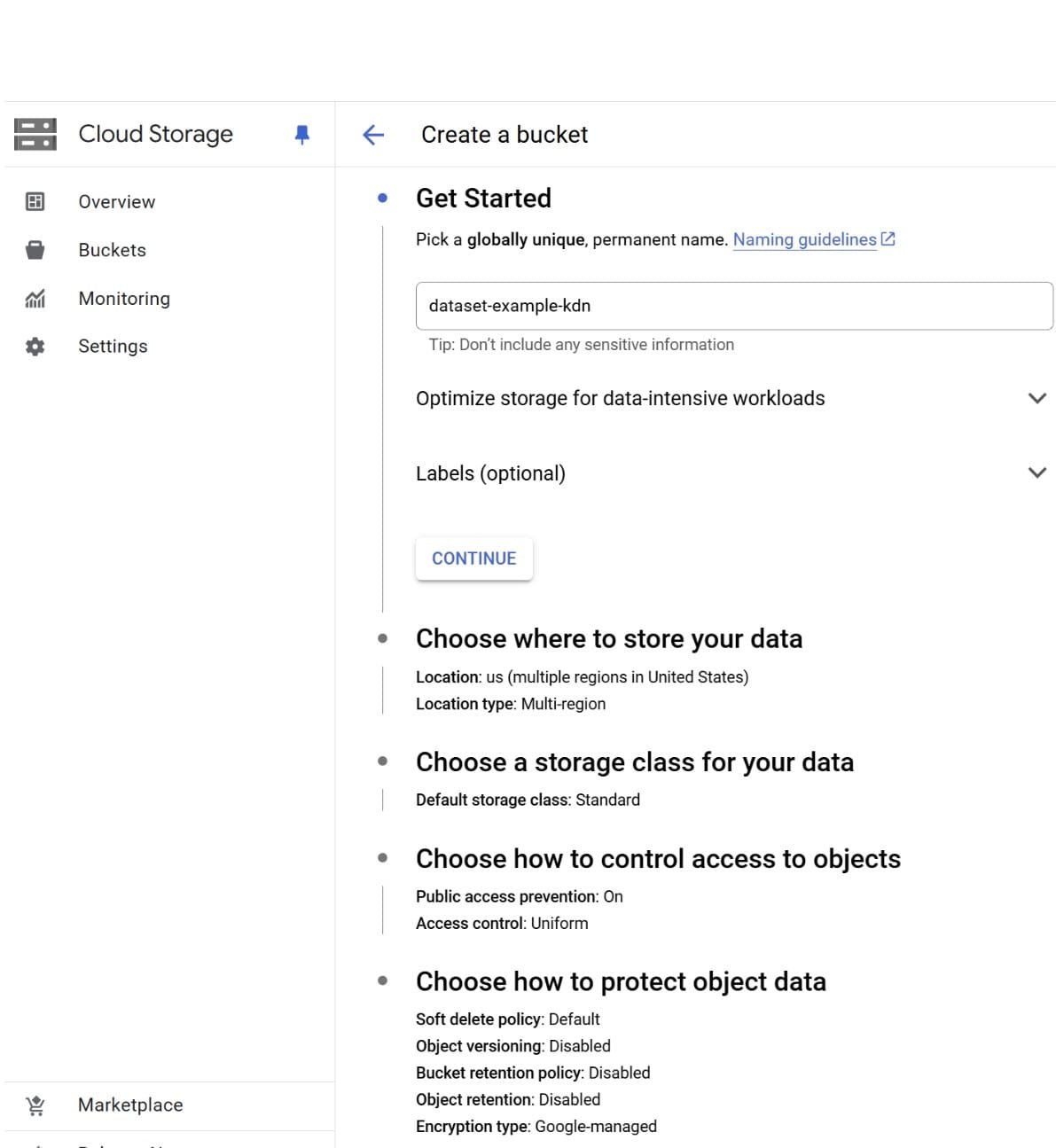
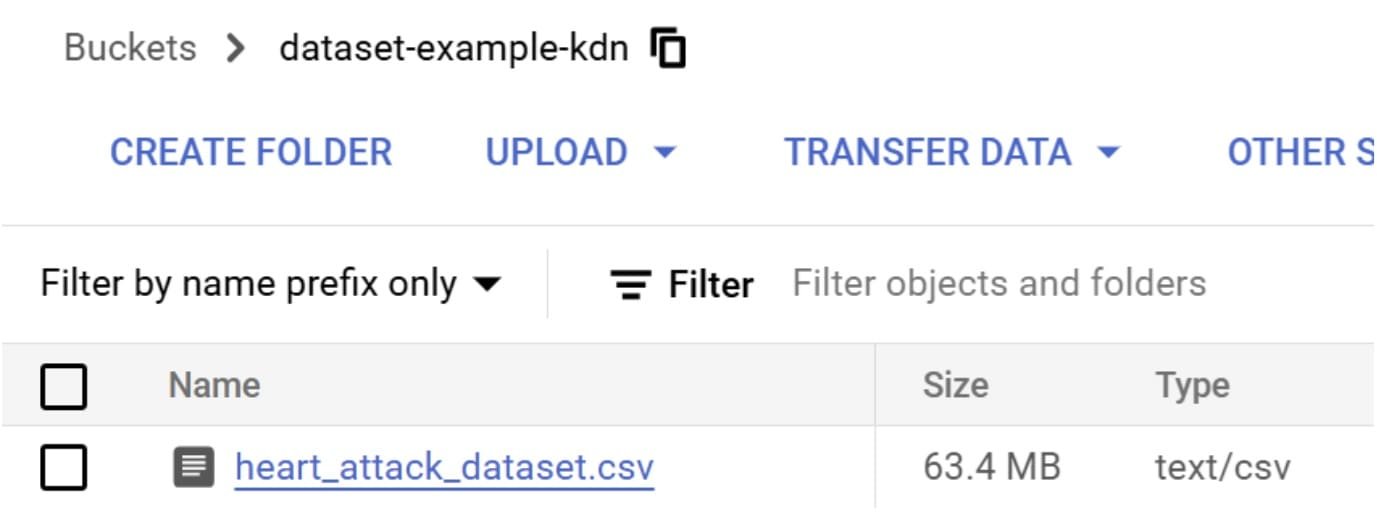
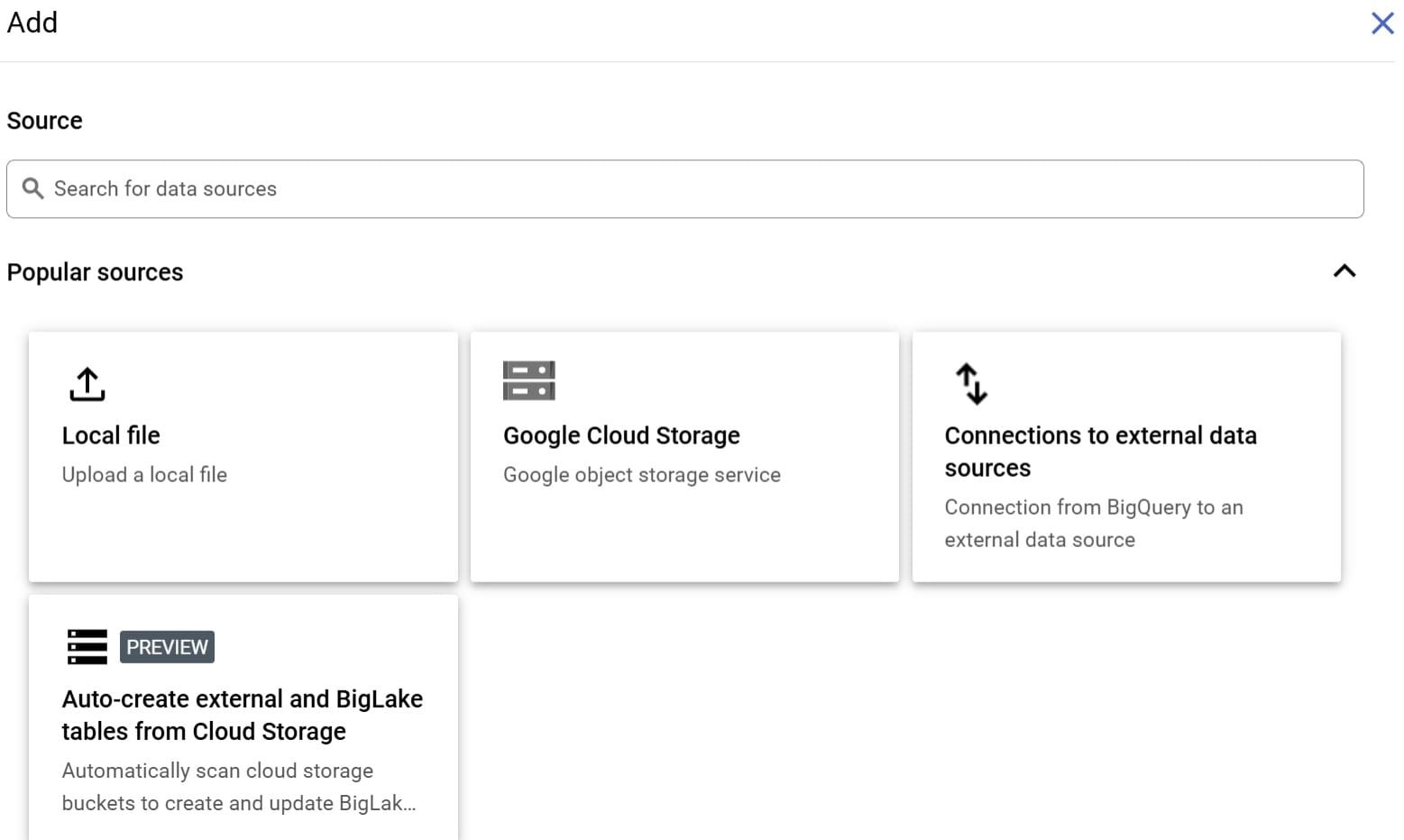
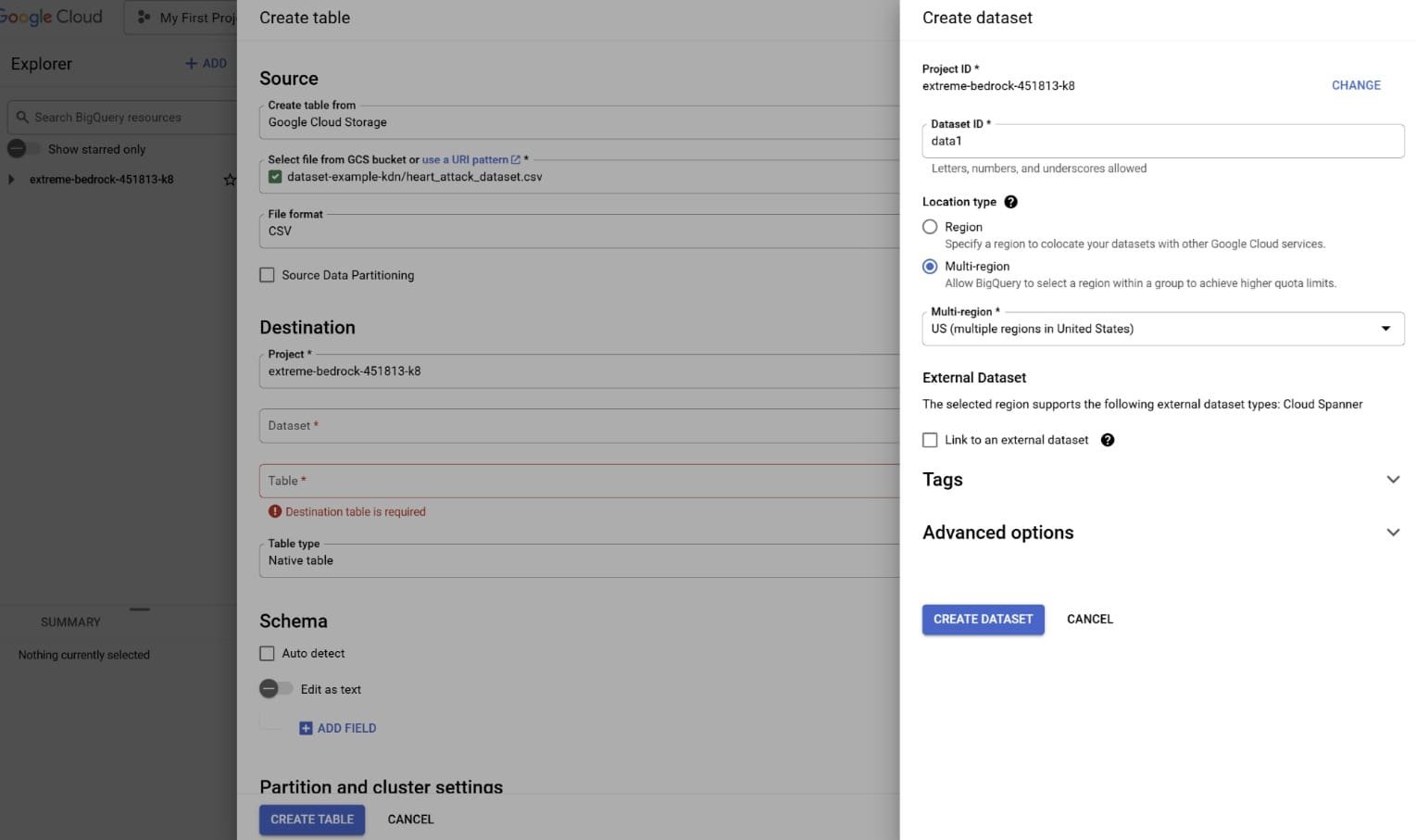
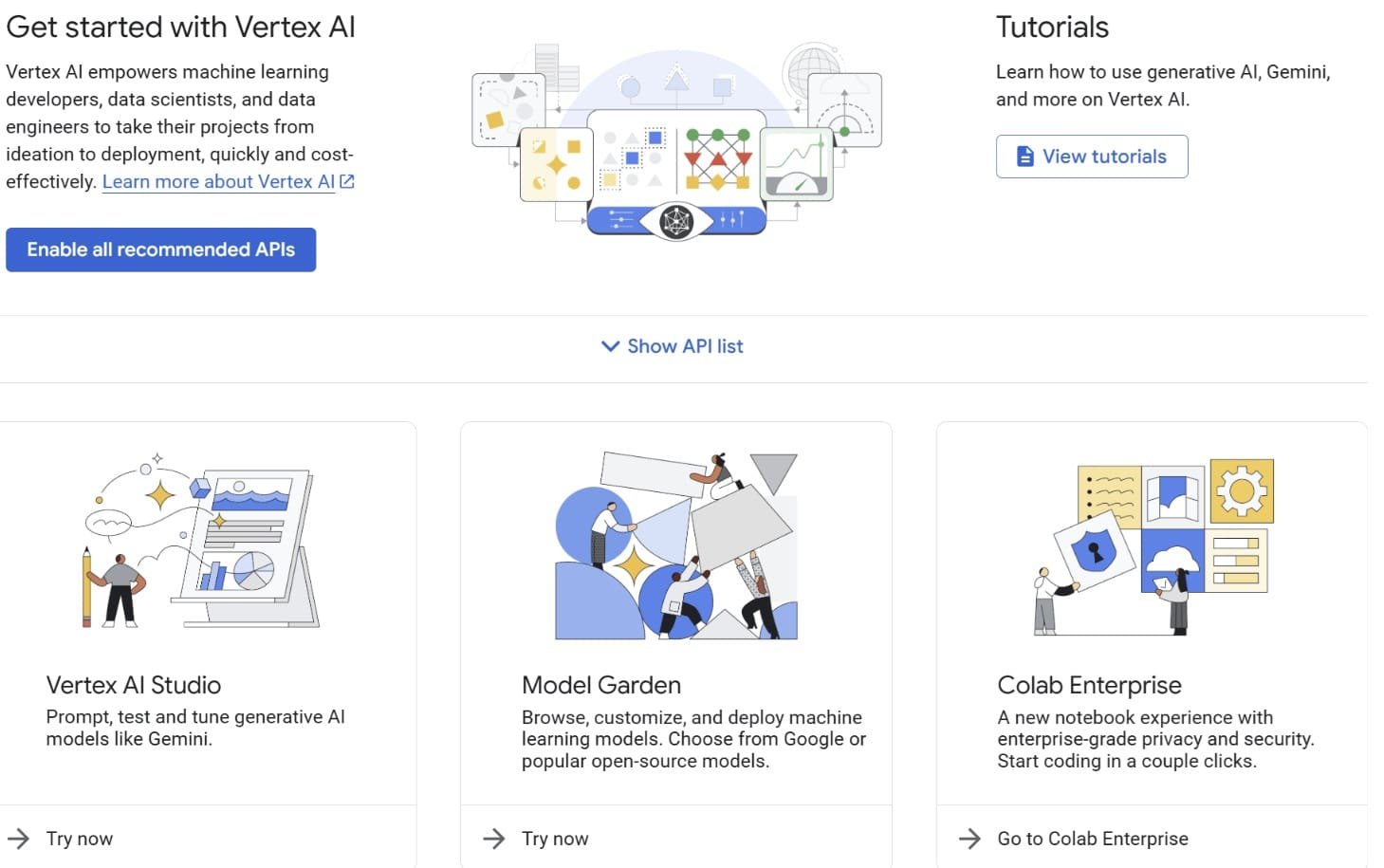
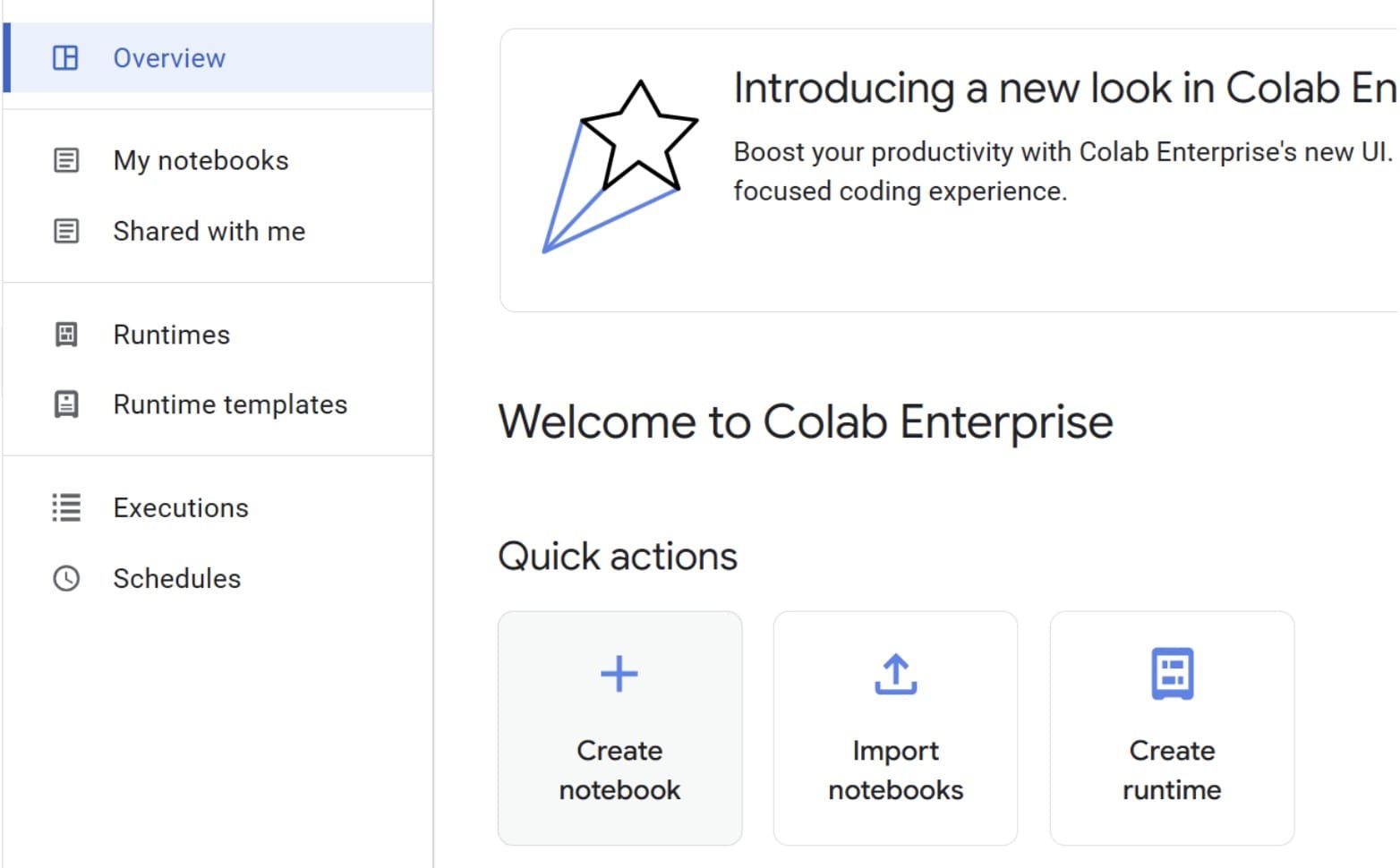
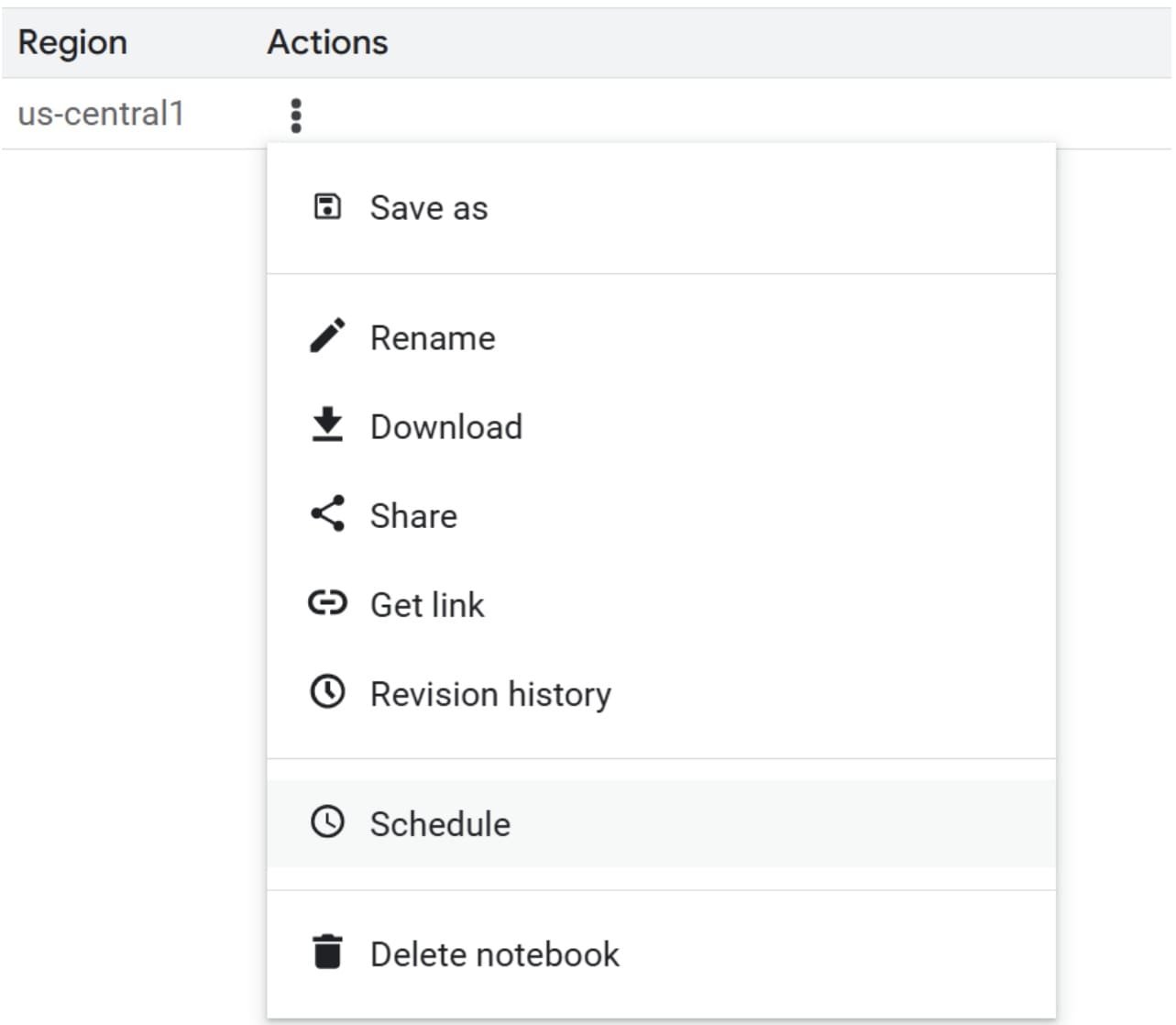
 Image de l’éditeur | Chatte
Image de l’éditeur | Chatte# Introduction
L’apprentissage automatique est devenu une partie intégrante de nombreuses entreprises, et les entreprises qui ne l’utilisent pas risquent d’être laissées pour compte. Compte tenu de la façon dont les modèles critiques fournissent un avantage concurrentiel, il est naturel que de nombreuses entreprises souhaitent les intégrer dans leurs systèmes.
Il existe de nombreuses façons de configurer un système de pipeline d’apprentissage automatique pour aider une entreprise, et une option consiste à l’héberger avec un fournisseur de cloud. Il existe de nombreux avantages au développement et au déploiement de modèles d’apprentissage automatique dans le cloud, y compris l’évolutivité, la rentabilité et les processus simplifiés par rapport à la construction de l’ensemble du pipeline en interne.
La sélection du fournisseur de cloud appartient à l’entreprise, mais dans cet article, nous explorerons comment configurer un pipeline d’apprentissage automatique sur la plate-forme Google Cloud (GCP).
Commençons.
# Préparation
Vous devez avoir un compte Google avant de procéder, car nous utiliserons le GCP. Une fois que vous avez créé un compte, accédez au Console Cloud Google.
Une fois dans la console, créez un nouveau projet.
Ensuite, avant toute autre chose, vous devez configurer votre configuration de facturation. La plate-forme GCP vous oblige à enregistrer vos informations de paiement avant de pouvoir faire la plupart des choses sur la plate-forme, même avec un compte d’essai gratuit. Vous n’avez pas à vous inquiéter, cependant, car l’exemple que nous utiliserons ne consommera pas beaucoup de votre crédit gratuit.
Veuillez inclure toutes les informations de facturation nécessaires pour démarrer le projet. Vous pourriez également avoir besoin de vos informations fiscales et d’une carte de crédit pour vous assurer qu’elles sont prêtes.
Avec tout en place, commençons à construire notre pipeline d’apprentissage automatique avec GCP.
# Pipeline d’apprentissage automatique avec Google Cloud Platform
Pour construire notre pipeline d’apprentissage automatique, nous aurons besoin d’un exemple de jeu de données. Nous utiliserons le Prédiction de crise cardiaque Ensemble de données de Kaggle pour ce tutoriel. Téléchargez les données et stockez-la quelque part pour l’instant.
Ensuite, nous devons configurer le stockage de données pour notre ensemble de données, que le pipeline d’apprentissage automatique utilisera. Pour ce faire, nous devons créer un seau de stockage pour notre ensemble de données. Recherchez le «stockage cloud» pour créer un seau. Il doit avoir un nom global unique. Pour l’instant, vous n’avez pas besoin de modifier les paramètres par défaut; Cliquez simplement sur le bouton Créer.
Une fois le seau créé, téléchargez votre fichier CSV vers lui. Si vous l’avez fait correctement, vous verrez l’ensemble de données à l’intérieur du seau.
Ensuite, nous allons créer une nouvelle table que nous pouvons interroger en utilisant le service BigQuery. Recherchez «BigQuery» et cliquez sur «Ajouter des données». Choisissez «Google Cloud Storage» et sélectionnez le fichier CSV dans le seau que nous avons créé plus tôt.
Remplissez les informations, en particulier la destination du projet, le formulaire de jeu de données (créez un nouvel ensemble de données ou sélectionnez un existant) et le nom du tableau. Pour le schéma, sélectionnez «Auto-détecter» puis créez le tableau.
Si vous l’avez créé avec succès, vous pouvez interroger la table pour voir si vous pouvez accéder à l’ensemble de données.
Ensuite, recherchez Vertex AI et activez toutes les API recommandées. Une fois cela terminé, sélectionnez «Colab Enterprise».
Sélectionnez «Créer un cahier» pour créer le cahier que nous utiliserons pour notre pipeline d’apprentissage automatique simple.
Si vous connaissez Google Colab, l’interface sera très similaire. Vous pouvez importer un ordinateur portable à partir d’une source externe si vous le souhaitez.
Avec le ordinateur portable prêt, connectez-vous à un runtime. Pour l’instant, le type de machine par défaut suffira car nous n’avons pas besoin de nombreuses ressources.
Commençons notre développement de pipeline d’apprentissage automatique en interrogeant les données de notre table BigQuery. Tout d’abord, nous devons initialiser le client BigQuery avec le code suivant.
from google.cloud import bigquery
client = bigquery.Client()
Ensuite, interrogeons notre ensemble de données dans la table BigQuery en utilisant le code suivant. Modifiez l’ID du projet, l’ensemble de données et le nom de la table pour correspondre à ce que vous avez créé précédemment.
# TODO: Replace with your project ID, dataset, and table name
query = """
SELECT *
FROM `your-project-id.your_dataset.heart_attack`
LIMIT 1000
"""
query_job = client.query(query)
df = query_job.to_dataframe()
Les données sont maintenant dans un Pandas DataFrame dans notre cahier. Transformons notre variable cible («résultat») en étiquette numérique.
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
df('Outcome') = df('Outcome').apply(lambda x: 1 if x == 'Heart Attack' else 0)
Ensuite, préparons nos ensembles de données de formation et de test.
df = df.select_dtypes('number')
X = df.drop('Outcome', axis=1)
y = df('Outcome')
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
⚠️ Note: df = df.select_dtypes('number') est utilisé pour simplifier l’exemple en supprimant toutes les colonnes non nucléaires. Dans un scénario du monde réel, il s’agit d’une étape agressive qui pourrait éliminer les fonctionnalités catégorielles utiles. Cela se fait ici pour simplifier, et normalement l’ingénierie ou le codage serait généralement pris en compte.
Une fois les données prêtes, formons un modèle et évaluons ses performances.
model = LogisticRegression()
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
print(f"Model Accuracy: {accuracy_score(y_test, y_pred)}")
La précision du modèle n’est que d’environ 0,5. Cela pourrait certainement être amélioré, mais pour cet exemple, nous procéderons avec ce modèle simple.
Maintenant, utilisons notre modèle pour faire des prédictions et préparer les résultats.
result_df = X_test.copy()
result_df('actual') = y_test.values
result_df('predicted') = y_pred
result_df.reset_index(inplace=True)
Enfin, nous sauverons les prédictions de notre modèle sur une nouvelle table BigQuery. Notez que le code suivant écrasera la table de destination si elle existe déjà, plutôt que de l’ajouter.
# TODO: Replace with your project ID and destination dataset/table
destination_table = "your-project-id.your_dataset.heart_attack_predictions"
job_config = bigquery.LoadJobConfig(write_disposition=bigquery.WriteDisposition.WRITE_TRUNCATE)
load_job = client.load_table_from_dataframe(result_df, destination_table, job_config=job_config)
load_job.result()
Avec cela, vous avez créé un pipeline d’apprentissage automatique simple dans un cahier Vertex AI.
Pour rationaliser ce processus, vous pouvez planifier le cahier pour s’exécuter automatiquement. Accédez aux actions de votre cahier et sélectionnez «calendrier».
Sélectionnez la fréquence dont vous avez besoin pour que le cahier exécute, par exemple, tous les mardis ou le premier jour du mois. Il s’agit d’un moyen simple de s’assurer que le pipeline d’apprentissage automatique fonctionne au besoin.
C’est tout pour la configuration d’un pipeline d’apprentissage automatique simple sur GCP. Il existe de nombreux autres moyens plus prêts pour la production de configurer un pipeline, comme l’utilisation de pipelines Kubeflow (KFP) ou le service de pipelines Vertex AI plus intégré.
# Conclusion
Google Cloud Platform offre aux utilisateurs un moyen facile de configurer un pipeline d’apprentissage automatique. Dans cet article, nous avons appris à configurer un pipeline en utilisant divers services cloud comme le stockage cloud, BigQuery et Vertex AI. En créant le pipeline sous forme de cahier et en le planifiant pour s’exécuter automatiquement, nous pouvons créer un pipeline fonctionnel simple.
J’espère que cela a aidé!
Cornellius Yudha Wijaya est un directeur adjoint des sciences de données et un écrivain de données. Tout en travaillant à plein temps chez Allianz Indonesia, il aime partager des conseils de python et de données via les médias sociaux et la rédaction des médias. Cornellius écrit sur une variété d’IA et de sujets d’apprentissage automatique.
Source link



