
Comment construire un pipeline de données léger avec AirTable et Python
- Intelligence Artificielle
 Noesis News
Noesis News- 0
- 15 minutes de lecture

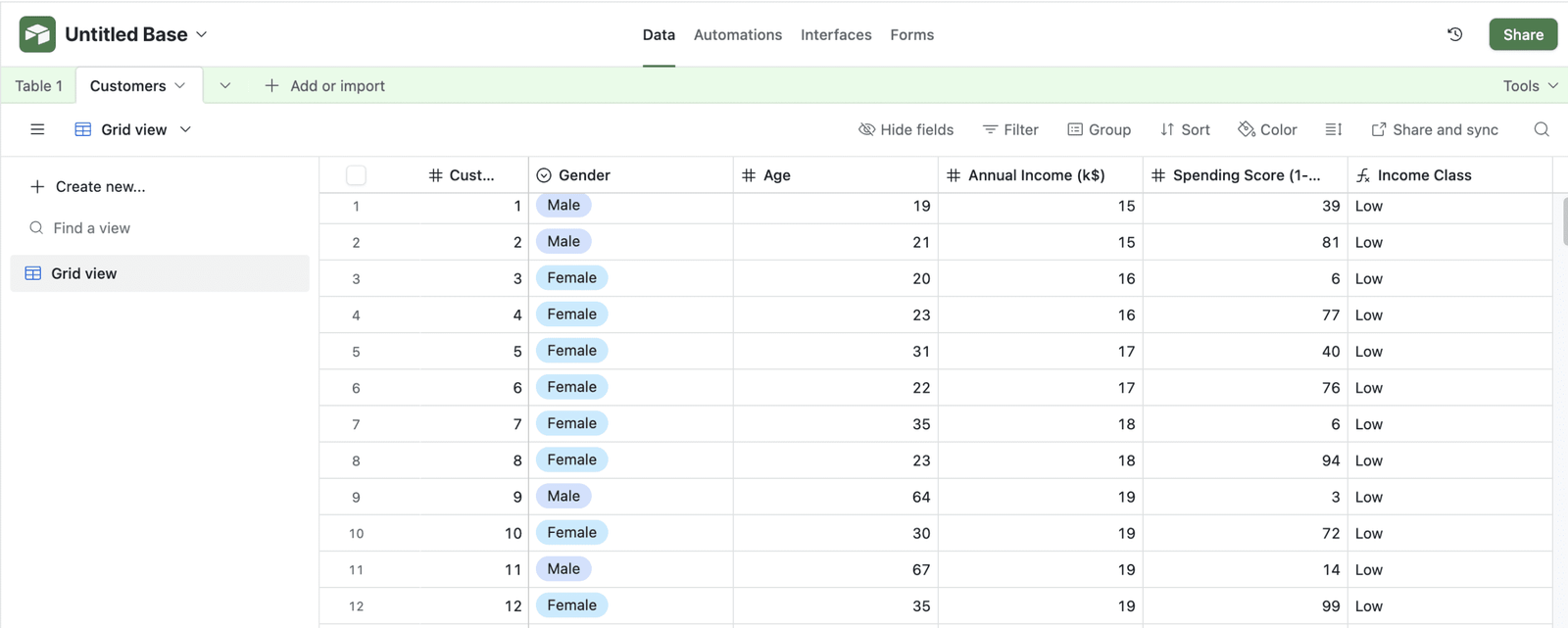
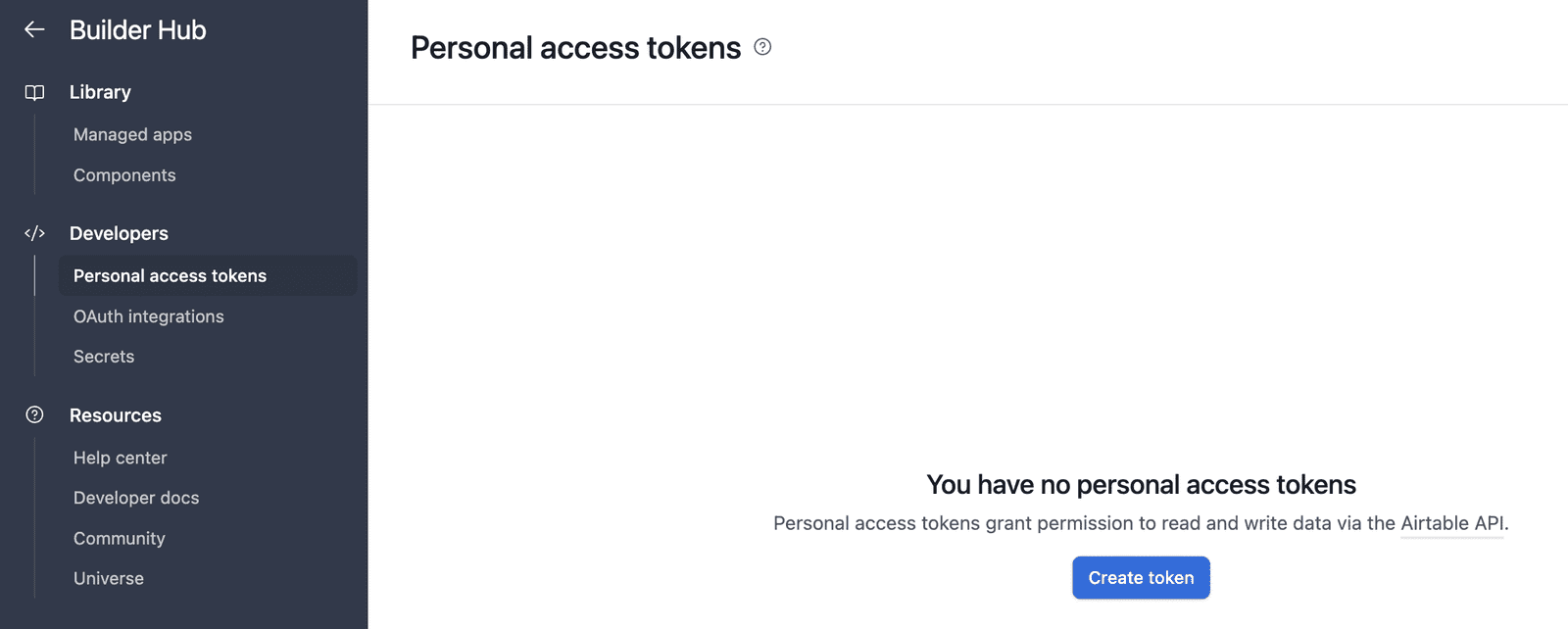

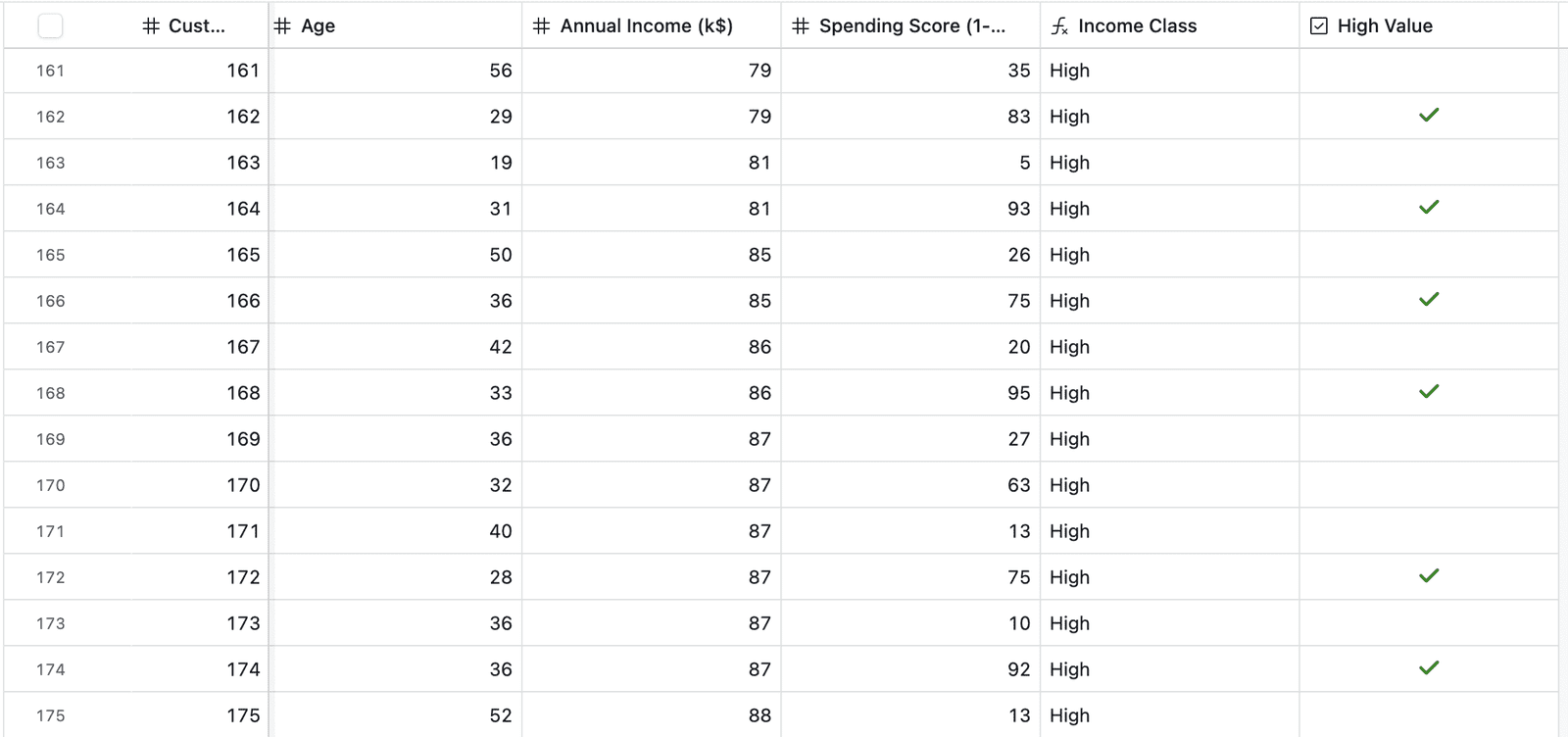

Image de l’éditeur | Chatte
# Introduction
Aérinable Offre non seulement une interface flexible de type de calcul pour le stockage et l’analyse des données, mais elle fournit également une API pour l’interaction programmatique. En d’autres termes, vous pouvez le connecter aux outils et technologies externes – par exemple, Python – Pour créer des pipelines de données ou traiter les workflows, ramener vos résultats à votre base de données Airtable (ou simplement « base », dans le jargon Airtable).
Cet article montre comment créer un pipeline simple de type ETL à l’aide de l’API Python Airtable. Nous nous en tiendrons au niveau gratuit, garantissant que l’approche fonctionne sans fonctionnalités payantes.
# Configuration de l’ensemble de données Airtable
Bien que le pipeline intégré dans cet article puisse être facilement adapté à une variété d’ensembles de données, pour ceux qui sont nouveaux à Airtable et ont besoin d’un projet AirTable et d’un ensemble de données stocké comme point de départ, nous vous recommandons de suivre cela Tutoriel d’introduction récent à AirTable et créer un ensemble de données tabulaire appelé « clients », contenant 200 lignes et les colonnes suivantes (voir image):
Ensemble de données / table des clients dans AirTable | Image par auteur
# Pipeline de données Airtable-Python
Dans Airtable, accédez à votre avatar d’utilisateur – au moment de la rédaction du moment de la rédaction, c’est l’avatar encerclé situé dans le coin inférieur gauche de l’interface de l’application – et sélectionnez « Builder Hub ». Dans le nouvel écran (voir la capture d’écran ci-dessous), cliquez sur « Personal Access Tokens », puis sur « Créer un jeton ». Donnez-lui un nom et assurez-vous d’ajouter au moins ces deux portées: data.records:read et data.records:write. De même, sélectionnez la base où se trouve votre tableau des clients dans la section « Accès », afin que votre jeton ait configuré l’accès à cette base.
Création d’un jeton API Airtable | Image par auteur
Une fois le jeton créé, copiez-le et stockez-le soigneusement dans un endroit sûr, comme il ne sera montré qu’une seule fois. Nous en aurons besoin plus tard. Le jeton commence par pat suivi d’un long code alphanumérique.
Une autre information clé dont nous aurons besoin pour construire notre pipeline basé sur Python qui interagit avec AirTable est l’ID de notre base. Revenez à votre base dans l’interface Web Airtable, et une fois sur place, vous devriez voir que son URL dans le navigateur a une syntaxe comme: https://airtable.com/app(xxxxxx)/xxxx/xxxx. La partie que nous souhaitons copier est le app(xxxx) ID contenu entre deux barres obliques consécutives (/): c’est l’ID de base dont nous aurons besoin.
Avec cela en main, et en supposant que vous avez déjà une table peuplée appelée « clients » dans votre base, nous sommes prêts à démarrer notre programme Python. J’utiliserai un ordinateur portable pour le coder. Si vous utilisez un IDE, vous devrez peut-être modifier légèrement la partie où les trois variables d’environnement Airtable sont définies, pour les faire lire à partir d’un .env fichier à la place. Dans cette version, pour simplicité et facilité d’illustration, nous les définirons directement dans notre cahier. Commençons par installer les dépendances nécessaires:
!pip install pyairtable python-dotenv
Ensuite, nous définissons les variables d’environnement Airtable. Notez que pour les deux premiers, vous devez remplacer la valeur par votre jeton d’accès réel et votre ID de base, respectivement:
import os
from dotenv import load_dotenv # Necessary only if reading variables from a .env file
from pyairtable import Api, Table
import pandas as pd
PAT = "pat-xxx" # Your PAT (Personal Access Token) is pasted here
BASE_ID = "app-xxx" # Your Airtable Base ID is pasted here
TABLE_NAME = "Customers"
api = Api(PAT)
table = Table(PAT, BASE_ID, TABLE_NAME)
Nous venons de configurer une instance de l’API Python AirTable et a instancié un point de connexion à la table des clients de notre base. Maintenant, c’est ainsi que nous lisons l’intégralité de l’ensemble de données contenu dans notre table AirTable et le chargez dans un Pandas DataFrame. Il vous suffit de faire attention à utiliser les noms de colonne exacts de la table source pour les arguments de chaîne à l’intérieur du get() Appels de méthode:
rows = ()
for rec in table.all(): # honors 5 rps; auto-retries on 429s
fields = rec.get("fields", {})
rows.append({
"id": rec("id"),
"CustomerID": fields.get("CustomerID"),
"Gender": fields.get("Gender"),
"Age": fields.get("Age"),
"Annual Income (k$)": fields.get("Annual Income (k$)"),
"Spending Score (1-100)": fields.get("Spending Score (1-100)"),
"Income class": fields.get("Income Class"),
})
df = pd.DataFrame(rows)
Une fois les données chargées, il est temps d’appliquer une transformation simple. Pour plus de simplicité, nous appliquerons une seule transformation, mais nous pourrions en appliquer autant que nécessaire, tout comme nous le ferions habituellement lors du prétraitement ou du nettoyage des ensembles de données avec des pandas. Nous allons créer un nouvel attribut binaire, appelé Is High Valuepour désigner les clients de grande valeur, c’est-à-dire ceux dont le revenu et le score de dépenses sont tous les deux élevés:
def high_value(row):
try:
return (row("Spending Score (1-100)") >= 70) and (row("Annual Income (k$)") >= 70)
except TypeError:
return False
df("Is High Value") = df.apply(high_value, axis=1)
df.head()
Ensemble de données résultant:
Transformation de données Airtable avec Python et Pandas | Image par auteur
Enfin, il est temps d’écrire les modifications à AirTable en incorporant les nouvelles données associées à la nouvelle colonne. Il y a une petite mise en garde: nous devons d’abord créer manuellement une nouvelle colonne nommée « Haute valeur » dans notre table AirTable Custirals, avec son type défini sur « Box » (l’équivalent des attributs catégoriques binaires). Une fois cette colonne vierge créée, exécutez le code suivant dans votre programme Python et les nouvelles données seront automatiquement ajoutées à AirTable!
updates = ()
for _, r in df.iterrows():
if pd.isna(r("id")):
continue
updates.append({
"id": r("id"),
"fields": {
"High Value": bool(r("Is High Value"))
}
})
if updates:
table.batch_update(updates)
Il est temps de retourner à Airtable et de voir ce qui a changé dans notre table des clients source! Si à première vue, vous ne voyez aucun changement et que la nouvelle colonne semble toujours vide, ne paniquez pas encore. Peu de clients sont étiquetés comme « une grande valeur », et vous devrez peut-être faire défiler un peu pour voir un peu étiqueté avec un panneau de tick vert:
Tableau des clients mis à jour | Image par auteur
C’est ça! Vous venez de construire votre propre pipeline de données léger de type ETL basé sur une interaction bidirectionnelle entre AirTable et Python. Bien joué!
# Emballage
Cet article s’est concentré sur la mise en valeur des capacités de données avec AirTable, une plate-forme cloud polyvalente et conviviale pour la gestion et l’analyse des données qui combinent les caractéristiques des feuilles de calcul et des bases de données relationnelles avec des fonctions alimentées par l’IA. En particulier, nous avons montré comment exécuter un pipeline de transformation de données léger avec l’API Airtable Python qui lit les données d’AirTable, la transforme et la charge à AirTable – toutes dans les capacités et les limites de la version gratuite d’AirTable.
Iván Palomares Carrascosa est un leader, écrivain, conférencier et conseiller dans l’IA, l’apprentissage automatique, le Deep Learning & LLMS. Il entraîne et guide les autres à exploiter l’IA dans le monde réel.
Source link



