
Comment combiner rational, pandas et tracer pour les applications de données interactives
- Intelligence Artificielle
 Noesis News
Noesis News- 0
- 17 minutes de lecture

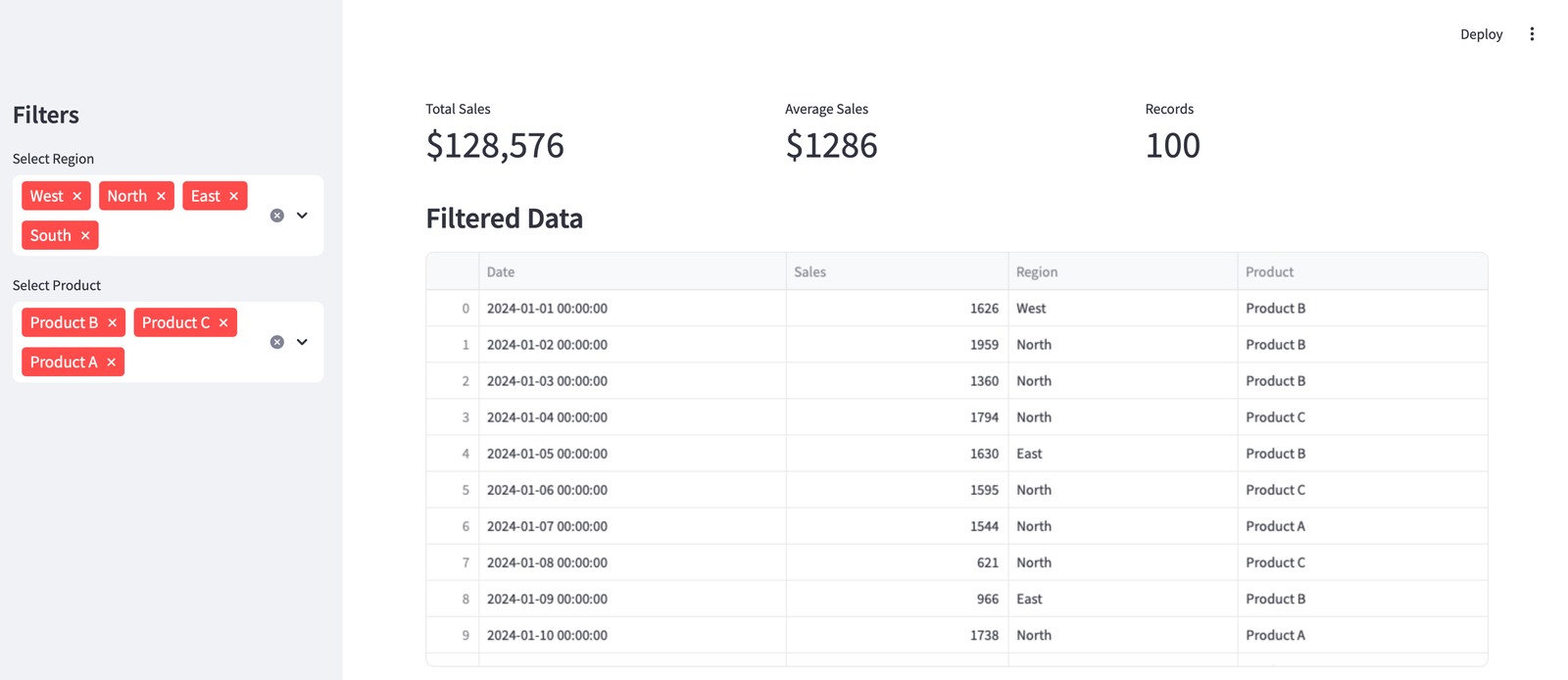


Image de l’auteur | Chatte
Introduction
La création de tableaux de bord de données interactifs basés sur le Web dans Python est plus facile que jamais lorsque vous combinez les forces de Rationaliser, Pandaset Tracer. Ces trois bibliothèques fonctionnent parfaitement ensemble pour transformer des ensembles de données statiques en applications réactives et visuellement engageantes – le tout sans avoir besoin d’une formation en développement Web.
Cependant, il y a une différence architecturale importante à comprendre avant de commencer. Contrairement aux bibliothèques telles que Matplotlib ou SeaBorn qui fonctionnent directement dans des ordinateurs portables Jupyter, Streamlit crée des applications Web autonomes qui doivent être exécutées à partir de la ligne de commande. Vous écrirez votre code dans un IDE basé sur le texte comme le code VS, enregistrez-le en tant que fichier .pyet l’exécutez en utilisant rational de run run filename.py. Ce passage de l’environnement du cahier vers le développement basé sur le script ouvre de nouvelles possibilités pour partager et déployer vos applications de données.
Dans ce tutoriel pratique, vous apprendrez à créer un tableau de bord de vente complet dans Deux étapes claires. Nous commencerons avec les fonctionnalités de base en utilisant Just Streamlit et Pandas, puis améliorer le tableau de bord avec des visualisations interactives à l’aide de Plotly.
Installation
Installez les packages requis:
pip install streamlit pandas plotly
Créez un nouveau dossier pour votre projet et ouvrez-le dans VS Code (ou votre éditeur de texte préféré).
Étape 1: Straitement + tableau de bord Pandas
Commençons par construire un tableau de bord fonctionnel en utilisant Just Streamlit et Pandas. Cela montre comment rationaliser crée des interfaces Web interactives et comment Pandas gère le filtrage des données.
Créer un fichier appelé Step1_dashboard_basic.py:
import streamlit as st
import pandas as pd
import numpy as np
# Page config
st.set_page_config(page_title="Basic Sales Dashboard", layout="wide")
# Generate sample data
np.random.seed(42)
df = pd.DataFrame({
'Date': pd.date_range('2024-01-01', periods=100),
'Sales': np.random.randint(500, 2000, size=100),
'Region': np.random.choice(('North', 'South', 'East', 'West'), size=100),
'Product': np.random.choice(('Product A', 'Product B', 'Product C'), size=100)
})
# Sidebar filters
st.sidebar.title('Filters')
regions = st.sidebar.multiselect('Select Region', df('Region').unique(), default=df('Region').unique())
products = st.sidebar.multiselect('Select Product', df('Product').unique(), default=df('Product').unique())
# Filter data
filtered_df = df((df('Region').isin(regions)) & (df('Product').isin(products)))
# Display metrics
col1, col2, col3 = st.columns(3)
col1.metric("Total Sales", f"${filtered_df('Sales').sum():,}")
col2.metric("Average Sales", f"${filtered_df('Sales').mean():.0f}")
col3.metric("Records", len(filtered_df))
# Display filtered data
st.subheader("Filtered Data")
st.dataframe(filtered_df)
Décomposons les méthodes de rationalisation des clés utilisées ici:
- St.Set_Page_Config () Configure le titre et la disposition de l’onglet du navigateur
- casse-pied Crée le panneau de navigation gauche pour les filtres
- St.Multiselelect () génère des menus déroulants pour les sélections d’utilisateurs
- St.Columns () Crée des sections de disposition côte à côte
- St.Metric () affiche de grands nombres avec des étiquettes
- St.DataFrame () rend les tables de données interactives
Ces méthodes gèrent automatiquement les interactions utilisateur et déclenchent des mises à jour de l’application lorsque les sélections changent.
Exécutez-le à partir de votre terminal (ou terminal intégré de VS Code):
streamlit run step1_dashboard_basic.py
Votre navigateur s’ouvrira à http: // localhost: 8501 montrant un tableau de bord interactif.
Essayez de modifier les filtres dans la barre latérale – regardez comment les métriques et la table de données mettent automatiquement à mettre à jour automatiquement! Cela démontre la nature réactive de la rationalisation combinée aux capacités de manipulation des données de Pandas.
Étape 2: Ajouter un terrain pour les visualisations interactives
Maintenant, améliorons notre tableau de bord en ajoutant des graphiques interactifs de Plotly. Cela montre comment les trois bibliothèques fonctionnent ensemble de manière transparente. Créons un nouveau fichier et appelons-le Step2_dashboard_plotly.py:
import streamlit as st
import pandas as pd
import plotly.express as px
import numpy as np
# Page config
st.set_page_config(page_title="Sales Dashboard with Plotly", layout="wide")
# Generate data
np.random.seed(42)
df = pd.DataFrame({
'Date': pd.date_range('2024-01-01', periods=100),
'Sales': np.random.randint(500, 2000, size=100),
'Region': np.random.choice(('North', 'South', 'East', 'West'), size=100),
'Product': np.random.choice(('Product A', 'Product B', 'Product C'), size=100)
})
# Sidebar filters
st.sidebar.title('Filters')
regions = st.sidebar.multiselect('Select Region', df('Region').unique(), default=df('Region').unique())
products = st.sidebar.multiselect('Select Product', df('Product').unique(), default=df('Product').unique())
# Filter data
filtered_df = df((df('Region').isin(regions)) & (df('Product').isin(products)))
# Metrics
col1, col2, col3 = st.columns(3)
col1.metric("Total Sales", f"${filtered_df('Sales').sum():,}")
col2.metric("Average Sales", f"${filtered_df('Sales').mean():.0f}")
col3.metric("Records", len(filtered_df))
# Charts
col1, col2 = st.columns(2)
with col1:
fig_line = px.line(filtered_df, x='Date', y='Sales', color="Region", title="Sales Over Time")
st.plotly_chart(fig_line, use_container_width=True)
with col2:
region_sales = filtered_df.groupby('Region')('Sales').sum().reset_index()
fig_bar = px.bar(region_sales, x='Region', y='Sales', title="Total Sales by Region")
st.plotly_chart(fig_bar, use_container_width=True)
# Data table
st.subheader("Filtered Data")
st.dataframe(filtered_df)
Exécutez-le à partir de votre terminal (ou terminal intégré de VS Code):
streamlit run step2_dashboard_plotly.py
Vous avez maintenant un tableau de bord interactif complet!
Les graphiques de l’intrigue sont entièrement interactifs – vous pouvez survoler les points de données, zoomer sur des périodes spécifiques et même cliquer sur les éléments de légende pour afficher / masquer les séries de données.
Comment les trois bibliothèques fonctionnent ensemble
Cette combinaison est puissante car chaque bibliothèque gère ce qu’elle fait le mieux:
Pandas gère toutes les opérations de données:
- Création et chargement de données
- Filtrage des données basées sur les sélections d’utilisateurs
- Agréger les données pour les visualisations
- Gestion des transformations de données
Rationaliser Fournit l’interface Web:
- Crée des widgets interactifs (multiselect, curseurs, etc.)
- Relacer automatiquement l’ensemble de l’application lorsque les utilisateurs interagissent avec les widgets
- Gère le modèle de programmation réactive
- Gère la disposition avec des colonnes et des conteneurs
Tracer Crée des visualisations riches et interactives:
- Graphiques que les utilisateurs peuvent planer, zoomer et explorer
- Graphiques d’aspect professionnel avec un code minimal
- Intégration automatique avec la réactivité de Streamlit
Flux de travail de développement clé
Le processus de développement suit un schéma simple. Commencez par écrire votre code dans VS Code ou n’importe quel éditeur de texte, en l’enregistrant en tant que fichier .py. Ensuite, exécutez l’application à partir de votre terminal en utilisant rational de run run filename.pyqui ouvre votre tableau de bord dans un navigateur à http: // localhost: 8501. Au fur et à mesure que vous modifiez et enregistrez votre code, rationalisez automatiquement les modifications et les offres pour relancer l’application. Une fois que vous êtes satisfait de votre tableau de bord, vous pouvez le déployer à l’aide de Streamlit Community Cloud pour partager avec les autres.
Étapes suivantes
Essayez ces améliorations:
Ajouter des données réelles:
# Replace sample data with CSV upload
uploaded_file = st.sidebar.file_uploader("Upload CSV", type="csv")
if uploaded_file:
df = pd.read_csv(uploaded_file)
Gardez à l’esprit que les ensembles de données réels nécessiteront des étapes de prétraitement spécifiques à votre structure de données. Vous devrez ajuster les noms de colonne, gérer les valeurs manquantes et modifier les options de filtre pour correspondre à vos champs de données réels. L’exemple de code fournit un modèle, mais chaque ensemble de données aura des exigences uniques pour le nettoyage et la préparation.
Plus de types de graphiques:
# Pie chart for product distribution
fig_pie = px.pie(filtered_df, values="Sales", names="Product", title="Sales by Product")
st.plotly_chart(fig_pie)
Vous pouvez tirer parti d’un tout Capacités graphiques de la galerie de Plotly.
Déploiement de votre tableau de bord
Une fois que votre tableau de bord fonctionne localement, le partager avec d’autres est simple via le cloud communautaire rationalisé. Tout d’abord, poussez votre code vers un référentiel public GitHub, en vous assurant d’inclure un exigences.txt Fichier répertoriant vos dépendances (Streamlit, Pandas, tracely). Puis visiter https://streamlit.io/cloudConnectez-vous avec votre compte GitHub et sélectionnez votre référentiel. Streamlit créera automatiquement et déploiera votre application, fournissant une URL publique auquel tout le monde peut accéder. Le niveau gratuit prend en charge plusieurs applications et gère les charges de trafic raisonnables, ce qui le rend parfait pour partager des tableaux de bord avec des collègues ou présenter votre travail dans un portefeuille.
Conclusion
La combinaison de rationalisation, de pandas et transforme de l’analyse des données des rapports statiques en applications Web interactives. Avec seulement deux fichiers Python et une poignée de méthodes, vous avez construit un tableau de bord complet qui rivalise avec des outils de renseignement commercial coûteux.
Ce tutoriel démontre un changement significatif dans la façon dont les scientifiques des données peuvent partager leur travail. Au lieu d’envoyer des graphiques statiques ou de nécessiter des collègues pour exécuter des ordinateurs portables Jupyter, vous pouvez désormais créer des applications Web que n’importe qui peut utiliser via un navigateur. La transition de l’analyse basée sur les cahiers aux applications basées sur des scripts ouvre de nouvelles opportunités aux professionnels de données pour rendre leurs informations plus accessibles et plus percutantes.
Au fur et à mesure que vous continuez à construire avec ces outils, considérez comment les tableaux de bord interactifs peuvent remplacer les rapports traditionnels dans votre organisation. Les mêmes principes que vous avez appris ici évoluent pour gérer les ensembles de données réels, les calculs complexes et les visualisations sophistiquées. Que vous créiez des tableaux de bord exécutifs, des outils de données exploratoires ou des applications orientées client, cette combinaison à trois bibliothèques fournit une base solide pour les applications de données professionnelles.
Né en Inde et élevé au Japon, Vinod apporte une perspective mondiale à l’enseignement des sciences des données et de l’apprentissage automatique. Il comble le fossé entre les technologies émergentes de l’IA et la mise en œuvre pratique des professionnels du travail. Vinod se concentre sur la création de voies d’apprentissage accessibles pour des sujets complexes tels que l’IA agentique, l’optimisation des performances et l’ingénierie de l’IA. Il se concentre sur les implémentations pratiques de l’apprentissage automatique et le mentorat de la prochaine génération de professionnels des données grâce à des sessions en direct et à des conseils personnalisés.
Source link



