
Commencez à construire avec des gemini 2.5 Flash
- Robotique
 Noesis News
Noesis News- 0
- 13 minutes de lecture

Aujourd’hui, nous déplions une première version de Gémeaux 2.5 Flash dans prévisualisation à travers l’API Gemini via Google AI Studio et Vertex Ai. S’appuyant sur la fondation populaire de 2.0 Flash, cette nouvelle version offre une mise à niveau majeure des capacités de raisonnement, tout en priorisant la vitesse et le coût. Gemini 2.5 Flash est notre premier modèle de raisonnement entièrement hybride, donnant aux développeurs la possibilité d’activer la réflexion sur ou l’éteindre. Le modèle permet également aux développeurs de définir les budgets de réflexion pour trouver le bon compromis entre la qualité, le coût et la latence. Même avec penser, Les développeurs peuvent maintenir les vitesses rapides de 2.0 Flash et améliorer les performances.
Nos modèles Gemini 2.5 sont des modèles de réflexion, capables de raisonner à travers leurs pensées avant de répondre. Au lieu de générer immédiatement une sortie, le modèle peut effectuer un processus de « réflexion » pour mieux comprendre l’invite, décomposer des tâches complexes et planifier une réponse. Sur les tâches complexes qui nécessitent plusieurs étapes de raisonnement (comme la résolution de problèmes mathématiques ou l’analyse des questions de recherche), le processus de réflexion permet au modèle d’arriver à des réponses plus précises et complètes. En fait, Gemini 2.5 Flash fonctionne fortement sur Invites dures en lmarenadeuxième à 2,5 pro.
2.5 Flash a des mesures comparables à d’autres modèles leader pour une fraction du coût et de la taille.
Notre modèle de pensée le plus rentable
2.5 Flash continue de mener en tant que modèle avec le meilleur rapport prix / performance.
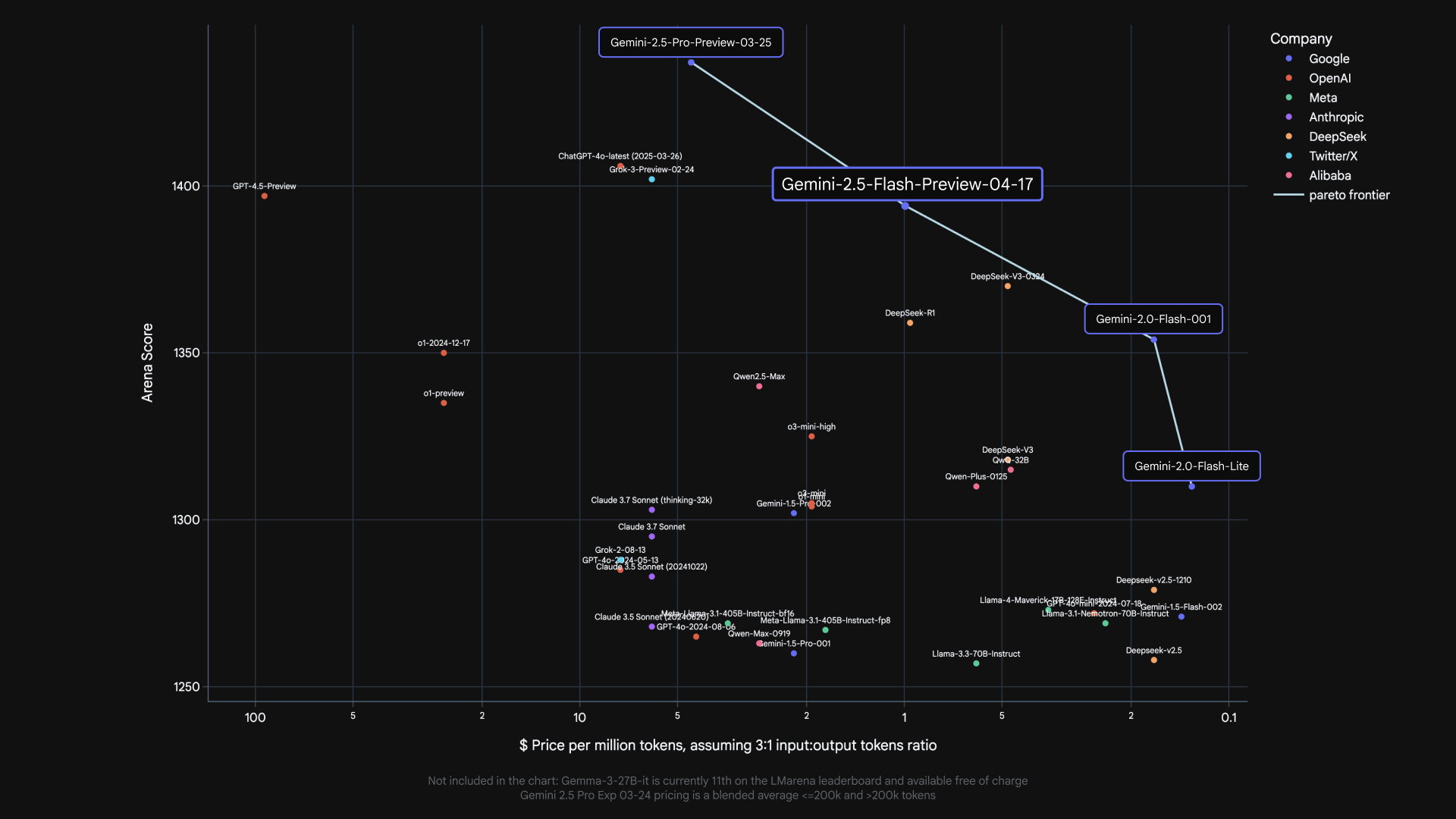
Gemini 2.5 Flash ajoute un autre modèle à la frontière Pareto de Google de coût à la qualité. *
Contrôles à grains fins pour gérer la pensée
Nous savons que différents cas d’utilisation ont des compromis différents en qualité, en coût et en latence. Pour donner à la flexibilité des développeurs, nous avons permis de définir un budget de réflexion Cela offre un contrôle à grain fin sur le nombre maximal de jetons qu’un modèle peut générer pendant la réflexion. Un budget plus élevé permet au modèle de raisonner davantage d’améliorer la qualité. Surtout, cependant, le budget établit un plafond sur la quantité de 2,5 Flash peut penser, mais le modèle n’utilise pas le budget complet si l’invite ne le nécessite pas.
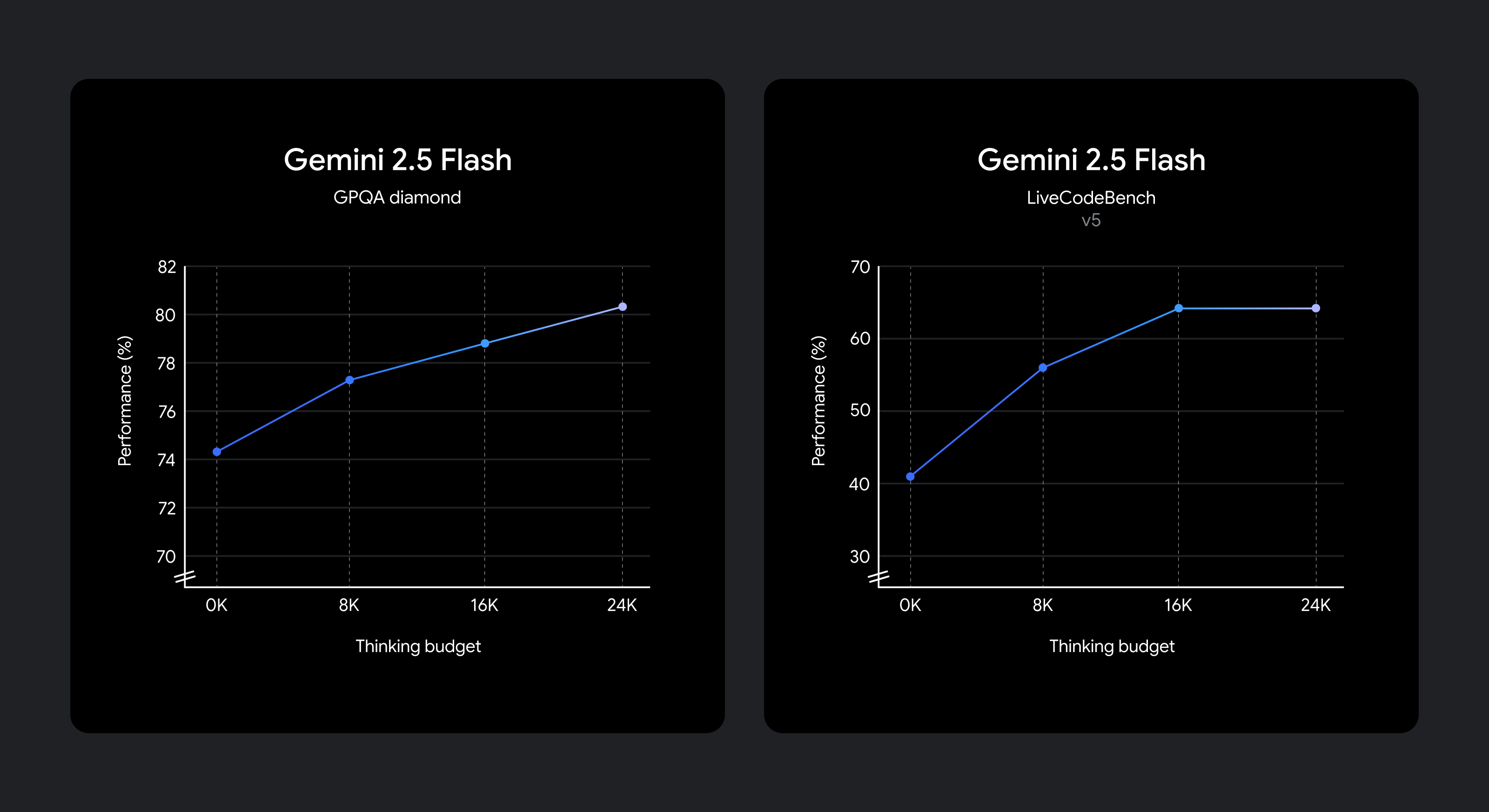
Améliorations de la qualité du raisonnement à mesure que le budget de réflexion augmente.
Le modèle est formé pour savoir combien de temps réfléchir pour une invite donnée, et décide donc automatiquement de la quantité à penser en fonction de la complexité des tâches perçue.
Si vous souhaitez conserver le coût et la latence les plus bas tout en améliorant les performances sur 2,0 Flash, Définissez le budget de réflexion sur 0. Vous pouvez également choisir de Définir un budget de jeton spécifique pour la phase de réflexion à l’aide d’un paramètre dans l’API ou le curseur dans Google Ai Studio et dans Vertex AI. Le budget peut aller de 0 à 24576 jetons pour 2,5 flash.
Les invites suivantes montrent combien de raisonnement peut être utilisé dans le mode par défaut du Flash 2.5.
Invites nécessitant un faible raisonnement:
Exemple 1: « Merci » en espagnol
Exemple 2: Combien de provinces du Canada a-t-il?
Invites nécessitant un raisonnement moyen:
Exemple 1: Vous roulez deux dés. Quelle est la probabilité qu’ils ajoutent à 7?
Exemple 2: Mon gymnase a des heures de ramassage pour le basket-ball de 21h à 15h sur MWF et entre 14h et 20h le mardi et samedi. Si je travaille de 9 h à 18 h 5 jours par semaine et que je veux jouer 5 heures de basket en semaine, créez un calendrier pour moi pour que tout fonctionne.
Invites nécessitant un raisonnement élevé:
Exemple 1: Un faisceau en porte-à-faux de longueur L = 3M a une section transversale rectangulaire (largeur b = 0,1 m, hauteur h = 0,2 m) et est en acier (E = 200 GPa). Il est soumis à une charge uniformément distribuée w = 5 kN / m sur toute sa longueur et une charge ponctuelle p = 10 kN à son extrémité libre. Calculez la contrainte de flexion maximale (σ_max).
Exemple 2: Écrire une fonction evaluate_cells(cells: Dict(str, str)) -> Dict(str, float) qui calcule les valeurs des cellules de la feuille de calcul.
Chaque cellule contient:
- Ou une formule comme
"=A1 + B1 * 2"en utilisant+,-,*,/et d’autres cellules.
Exigences:
- Résoudre les dépendances entre les cellules.
- Manipuler la priorité de l’opérateur (
*/avant+-).
- Détecter les cycles et augmenter
ValueError("Cycle detected at.") |
- Non
eval(). Utilisez uniquement des bibliothèques intégrées.
Commencez à construire avec Gemini 2.5 Flash dès aujourd’hui
Gemini 2.5 Flash avec des capacités de réflexion est désormais disponible en avant-première via le API Gemini dans Google AI Studio et dans Vertex Aiet dans une liste déroulante dédiée dans le Application Gemini. Nous vous encourageons à expérimenter le thinking_budget Paramètre et explorer comment le raisonnement contrôlable peut vous aider à résoudre des problèmes plus complexes.
from google import genai
client = genai.Client(api_key="GEMINI_API_KEY")
response = client.models.generate_content(
model="gemini-2.5-flash-preview-04-17",
contents="You roll two dice. What’s the probability they add up to 7?",
config=genai.types.GenerateContentConfig(
thinking_config=genai.types.ThinkingConfig(
thinking_budget=1024
)
)
)
print(response.text)
Trouvez des références API détaillées et des guides de réflexion dans notre Doc des développeurs ou commencer avec Exemples de code de Livre de cuisine Gemini.
Nous continuerons d’améliorer les Gemini 2.5 Flash, avec plus à venir bientôt, avant de le rendre généralement disponible pour une utilisation complète de la production.
*Le prix du modèle provient de l’analyse artificielle et de la documentation de l’entreprise



