
Avez-vous également remarqué que l’IA devient moins précise et plus lente à mesure que la conversation continue? | par Daniel Sautot | Mai 2025
- Intelligence Artificielle
 Noesis News
Noesis News- 0
- 10 minutes de lecture
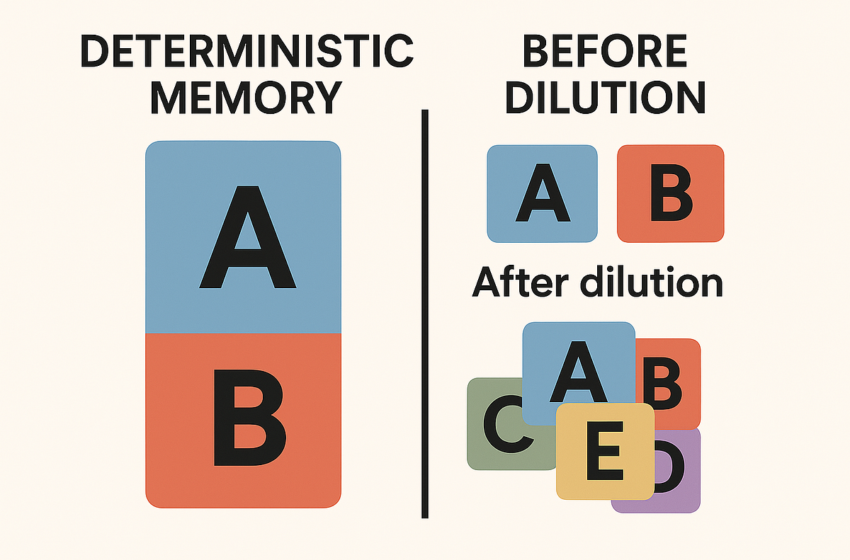
Aujourd’hui, je vais expliquer tous les secrets derrière ce qu’on appelle le fenêtre de contexte.
Vous avez probablement déjà demandé à une IA de corriger un texte ou de modifier une image sur plusieurs virages de conversation. À un moment donné, vous remarquez que l’IA cesse de faire les corrections que vous demandez. C’est dû à ce que j’appelle «Mémoire déterministe.»
Si vous parlez, par exemple, 100 000 fois sur le même sujet A, et que le 100 001e sujet – le sujet B – est sémantiquement très différent, l’IA aura du mal à généraliser, ce qui signifie qu’il a du mal à s’éloigner du sujet A. Félicitations, vous l’avez lavée par le cerveau. 😆
C’est un biais connu sous le nom de effet d’amorçagecausé par le contexte récent et dominant. Nous disons que le sujet A est amorcéet le sujet B est marginalcar il ne reçoit pas suffisamment d’attention mathématiquement. Je parle ici de inertie contextuelle causée par la domination de A (pauvre B: L’attention est toujours tout ce dont vous avez besoin…)
Maintenant, regardons perte d’informationsou ce que j’appelle « dilution. »
Plus vous écrivez à l’IA, moins il devient précis. Si votre conversation comprend plusieurs sujets, l’IA se perd finalement dans le mélange. C’est complètement normal.
Plus le contexte est long et plus complexe, plus il est difficile pour le LLM d’attribuer des poids optimaux aux informations. Cela peut finir par mélanger les thèmes et perdre de la précision, diluant ainsi les informations les plus pertinentes.
Enfin, parlons de temps de réponse.
Les LLM utilisent la mémoire GPU pour stocker les poids du modèle et les données contextuelles. Plus la fenêtre de contexte est grande, plus elle utilise de la mémoire et plus les calculs deviennent «exigeants».
En «exigeant», je veux dire la complexité algorithmique. La plupart des LLM modernes ont complexité de calcul quadratiqueou o (n²).
Combien ça coûte?
Cela dépend de l’architecture du modèle et de la fenêtre de contexte. Pour donner quelques chiffres (simplifiés): avec une fenêtre de contexte 4096-token, vous regardez à peu près 16,7 millions d’opérations vectorielles.
Pourquoi est-ce lent alors?
Même si un GPU peut effectuer des milliards d’opérations par seconde, le problème est que les LLM sont rarement pleinement chargés dans une seule mémoire de GPU. Ils sont répartis sur plusieurs GPU, et communication inter-gpu est ce qui ralentit tout.
Devriez-vous prendre tout cela littéralement?
Question rhétorique. Certains fournisseurs «trichent» un peu – ils réinitialisent partiellement la conversation sans vous le dire. Sneaky, non?
Que faire si vous rencontrez ces problèmes?
Demandez à l’IA de résumer la conversation et à copier-coller ce résumé dans une nouvelle session.
Intéressé à en savoir plus? Contactez-moi ici.



