
Apprendre l’importance de la formation des données sous la dérive du concept
- Intelligence Artificielle
 Noesis News
Noesis News- 0
- 22 minutes de lecture
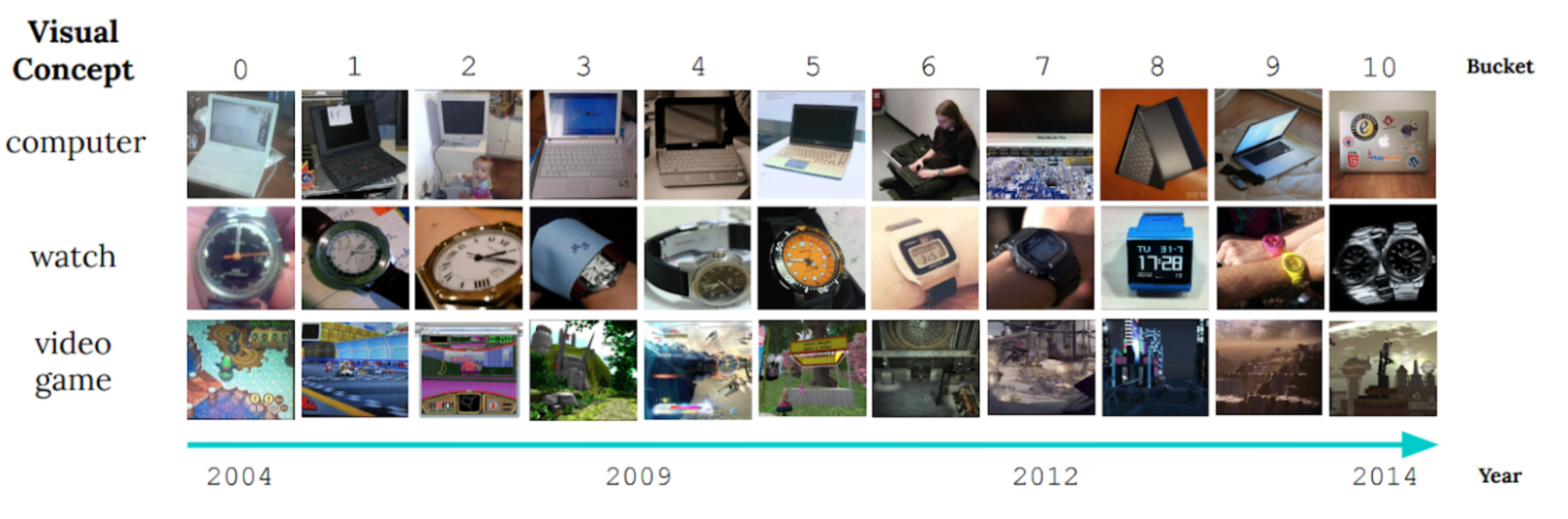



La nature en constante évolution du monde qui nous entoure pose un défi important pour le développement des modèles d’IA. Souvent, les modèles sont formés sur des données longitudinales dans l’espoir que les données de formation utilisées représenteront avec précision les entrées que le modèle pourrait recevoir à l’avenir. Plus généralement, l’hypothèse par défaut selon laquelle toutes les données de formation sont également pertinentes se cassent souvent dans la pratique. Par exemple, la figure ci-dessous montre des images du CLAIR Benchmark d’apprentissage non stationnaire, et il illustre comment les caractéristiques visuelles des objets évoluent considérablement sur une période de 10 ans (un phénomène que nous appelons dérive de concept lent), posant un défi pour les modèles de catégorisation d’objets.
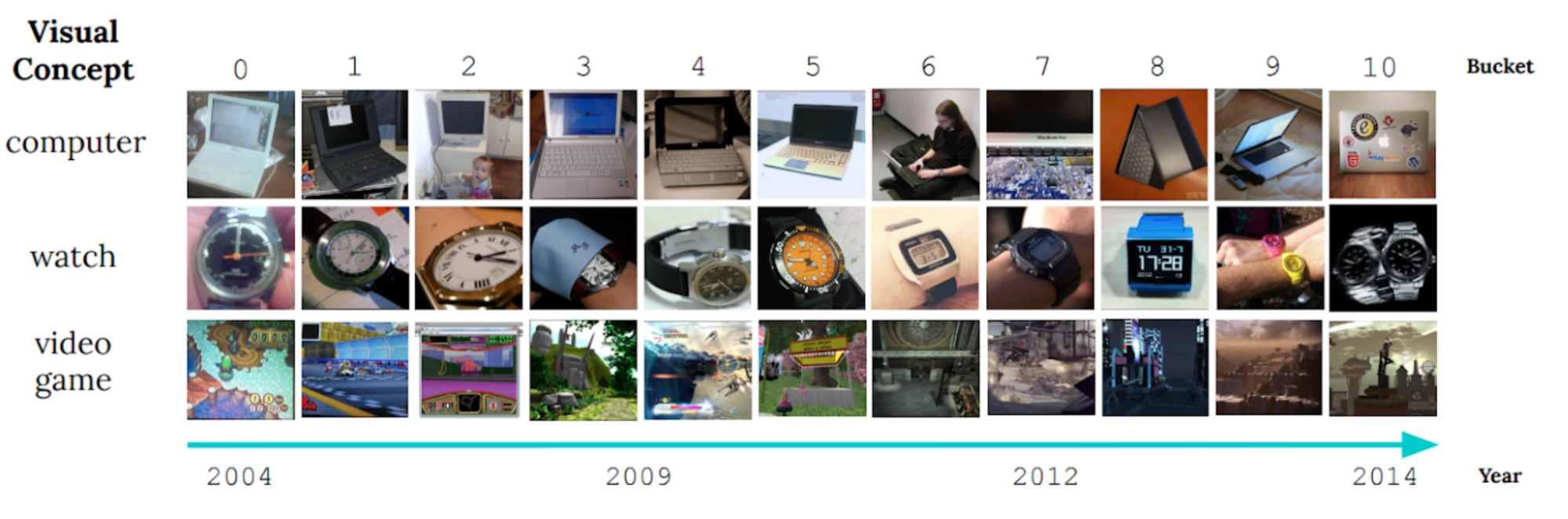 |
| Exemple d’images de la référence claire. (Adapté de Lin et al.) |
Approches alternatives, telles que en ligne et apprentissage continuMettez à jour à plusieurs reprises un modèle avec de petites quantités de données récentes afin de le garder à jour. Cela priorise implicitement les données récentes, car les apprentissages des données passées sont progressivement effacés par des mises à jour ultérieures. Cependant, dans le monde réel, différents types d’informations perdent une pertinence à des taux différents, il y a donc deux problèmes clés: 1) par conception ils se concentrent exclusivement Sur les données les plus récentes et perdre tout signal des données plus anciennes qui sont effacées. 2) Contributions de Data Instances Decay uniformément dans le temps quel que soit le contenu des données.
Dans nos travaux récents, « Échelles de délai de décroissance des instances pour l’apprentissage non stationnaire», Nous proposons d’attribuer à chaque instance un score d’importance pendant la formation afin de maximiser les performances du modèle sur les données futures. Pour ce faire, nous utilisons un modèle auxiliaire qui produit ces scores en utilisant l’instance de formation ainsi que son âge. Ce modèle est appris conjointement avec le modèle principal. Nous relevons à la fois les défis ci-dessus et réalisons des gains importants sur d’autres méthodes d’apprentissage robustes sur une gamme d’ensembles de données de référence pour l’apprentissage non stationnaire. Par exemple, sur un référence récent à grande échelle Pour l’apprentissage non stationnaire (~ 39 millions de photos sur une période de 10 ans), nous montrons jusqu’à 15% de gains de précision relative grâce à la réonctionnement des données de formation.
Le défi de la dérive du concept pour l’apprentissage supervisé
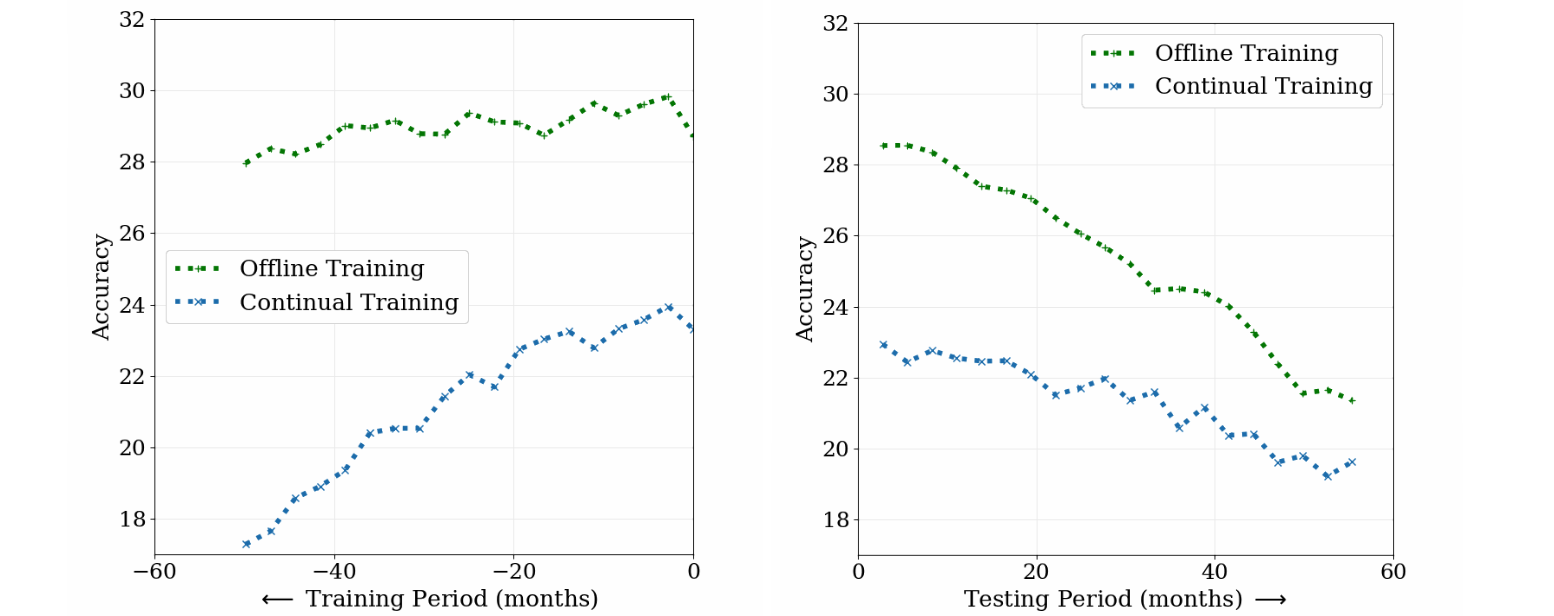
Pour obtenir un aperçu quantitatif de la dérive du concept lent, nous avons construit des classificateurs sur un Tâche de catégorisation récentecomprenant environ 39 millions de photographies provenant de sites Web de médias sociaux sur une période de 10 ans. Nous avons comparé la formation hors ligne, qui a itéré toutes les données de formation plusieurs fois dans un ordre aléatoire et une formation continue, qui a itéré plusieurs fois par mois chaque mois de données dans un ordre séquentiel (temporel). Nous avons mesuré la précision des modèles à la fois pendant la période de formation et pendant une période ultérieure où les deux modèles ont été congelés, c’est-à-dire non mis à jour davantage sur les nouvelles données (illustrées ci-dessous). À la fin de la période de formation (panneau de gauche, axe X = 0), les deux approches ont vu la même quantité de données, mais montrent un grand écart de performance. Cela est dû à oublier catastrophiqueun problème dans l’apprentissage continu où les connaissances d’un modèle sur les données du début de la séquence de formation sont diminuées de manière incontrôlée. D’un autre côté, l’oubli a ses avantages – sur la période de test (illustré à droite), le modèle formé continu se dégrade beaucoup moins rapidement que le modèle hors ligne car il dépend moins des données plus anciennes. La décroissance de la précision des deux modèles dans la période de test confirme que les données évoluent en effet au fil du temps, et les deux modèles deviennent de plus en moins pertinents.
 |
| Comparaison des modèles hors ligne et continuellement formés sur la tâche de classification photo. |
Re-pondération sensible au temps des données de formation
Nous concevons une méthode combinant les avantages de l’apprentissage hors ligne (la flexibilité de réutiliser efficacement toutes les données disponibles) et l’apprentissage continu (la capacité de minimiser les données plus anciennes) pour traiter la dérive du concept lente. Nous s’appuyons sur l’apprentissage hors ligne, puis ajoutons un contrôle minutieux sur l’influence des données passées et un objectif d’optimisation, tous deux conçus pour réduire la désintégration du modèle à l’avenir.
Supposons que nous souhaitons former un modèle, M, Compte tenu de certaines données de formation collectées au fil du temps. Nous proposons également de former un modèle d’assistance qui attribue un poids à chaque point en fonction de son contenu et de son âge. Ce poids évolue la contribution de ce point de données dans l’objectif de formation pour M. L’objectif des poids est d’améliorer les performances de M sur les données futures.
Dans Notre travailnous décrivons comment le modèle d’aide peut être méta-appris, c’est-à-dire, appris à côté M d’une manière qui aide l’apprentissage du modèle M lui-même. Un choix de conception clé du modèle d’assistance est que nous avons séparé les contributions liées à l’instance et à l’âge de manière factorisée. Plus précisément, nous fixons le poids en combinant les contributions à partir de plusieurs délais fixes différents de décomposition et apprenons une «affectation» approximative d’un exemple donné à ses échelles de temps les plus adaptées. Nous constatons dans nos expériences que cette forme du modèle d’assistance surpasse de nombreuses autres alternatives que nous avons considérées, allant des fonctions articulaires non contraints à une seule échelle de désintégration (exponentielle ou linéaire), en raison de sa combinaison de simplicité et d’expressivité. Tous les détails peuvent être trouvés dans le papier.
Marque de poids d’instance
La figure supérieure ci-dessous montre que notre modèle d’apprentissage d’assistance Défi de reconnaissance d’objets clairs; Les objets plus anciens sont en conséquence pondérés. De plus en plus examen (figure inférieure ci-dessous, basé sur le gradient importance importante Évaluation), nous constatons que le modèle d’assistance se concentre sur l’objet principal dans l’image, par exemple, par exemple, les caractéristiques de fond qui peuvent être fausses corrélées avec l’âge de l’instance.
 |
| Exemple d’images du CLAIR La référence (catégories de caméra et d’ordinateur) a attribué les poids les plus élevés et les plus bas respectivement par notre modèle d’aide. |
 |
| Analyse de l’importance de caractéristique de notre modèle d’assistance sur des exemples d’images CLAIR Benchmark. |
Résultats
Gains sur des données à grande échelle
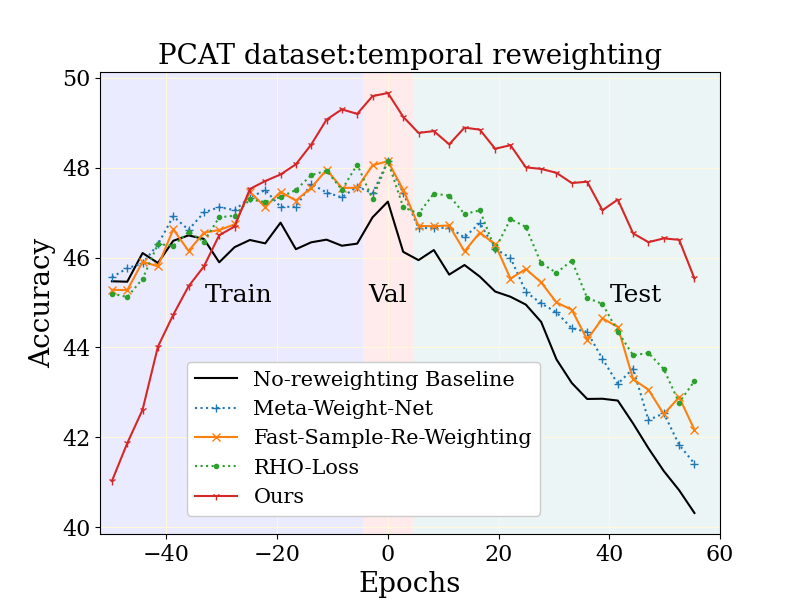
Nous étudions d’abord la grande échelle tâche de catégorisation de photos (Pcat) sur le Ensemble de données YFCC100M discuté plus tôt, en utilisant les cinq premières années de données pour la formation et les cinq prochaines années comme données de test. Notre méthode (montrée en rouge ci-dessous) s’améliore considérablement par rapport à la ligne de base de non-poids (noir) ainsi que de nombreuses autres techniques d’apprentissage robustes. Fait intéressant, notre méthode échange délibérément la précision sur le passé lointain (données de formation qui ne se reproduiront pas à l’avenir) en échange d’améliorations marquées dans la période de test. De plus, comme souhaité, notre méthode se dégrade moins que les autres lignes de base de la période de test.
 |
| Comparaison de notre méthode et des lignes de base pertinentes sur l’ensemble de données PCAT. |
Large applicabilité
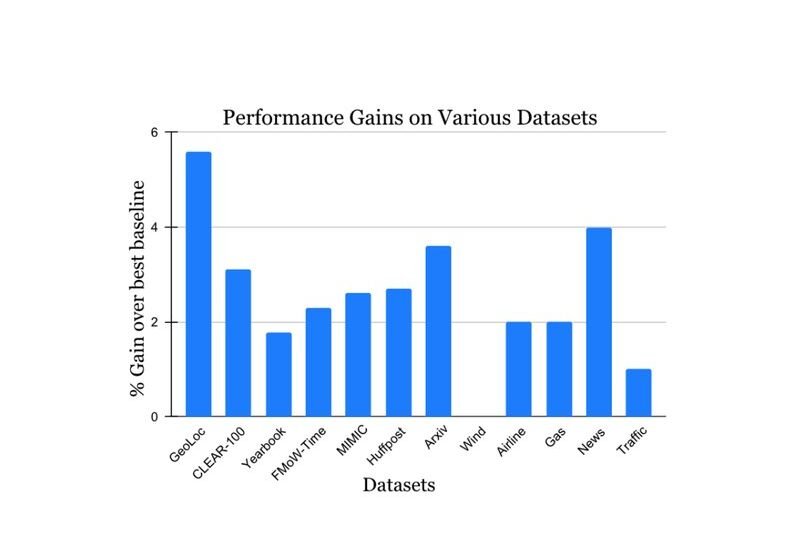
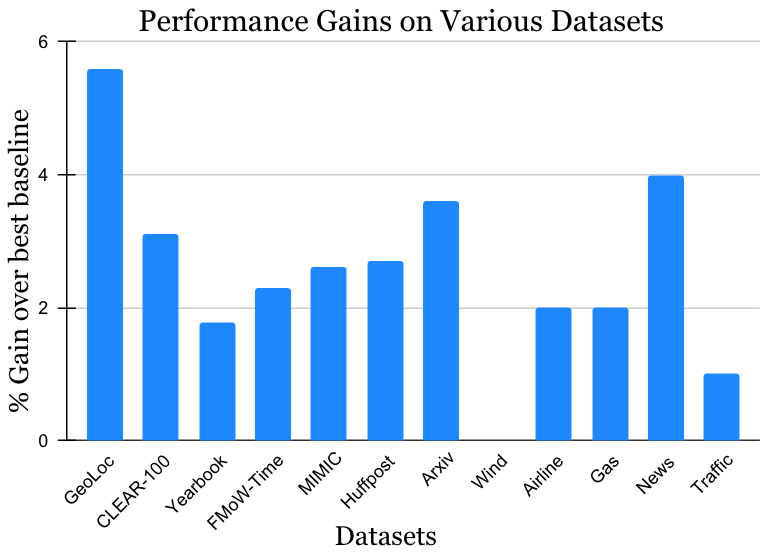
Nous avons validé nos résultats sur un large éventail de jeux de données de défi d’apprentissage non stationnaires provenant de la littérature universitaire (voir 1, 2, 3, 4 pour plus de détails) qui couvre les sources de données et les modalités (photos, images satellites, texte des médias sociaux, dossiers médicaux, lectures de capteurs, données tabulaires) et tailles (allant de 10k à 39m instances). Nous rapportons des gains significatifs dans la période de test par rapport à la méthode de référence publiée la plus proche pour chaque ensemble de données (illustré ci-dessous). Notez que la méthode la plus connue précédente peut être différente pour chaque ensemble de données. Ces résultats présentent la large applicabilité de notre approche.
 |
| Gain de performance de notre méthode sur une variété de tâches étudiant la dérive du concept naturel. Nos gains rapportés sont sur la méthode la plus connue précédente pour chaque ensemble de données. |
Extensions vers l’apprentissage continu
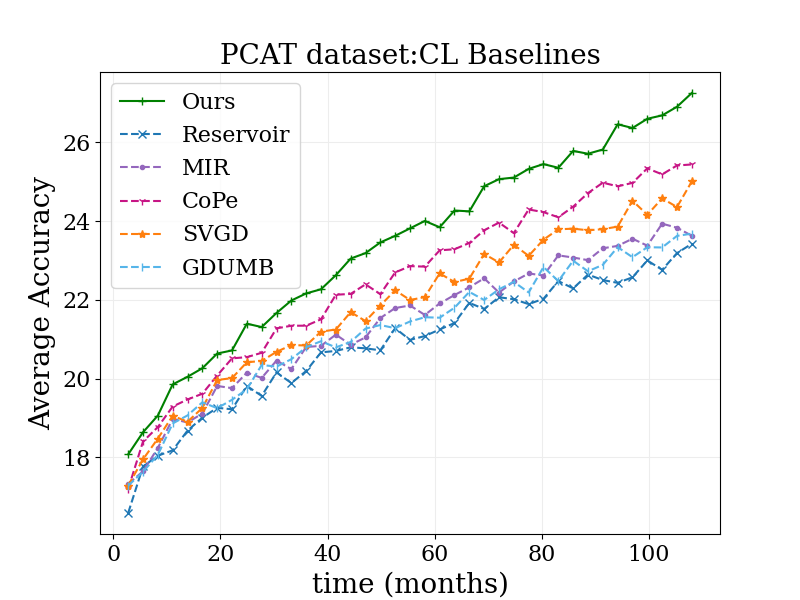
Enfin, nous considérons une extension intéressante de notre travail. Le travail ci-dessus a décrit comment l’apprentissage hors ligne peut être étendu pour gérer la dérive du concept en utilisant des idées inspirées de l’apprentissage continu. Cependant, l’apprentissage hors ligne est parfois irréalisable – par exemple, si la quantité de données de formation disponibles est trop importante pour maintenir ou traiter. Nous avons adapté notre approche de l’apprentissage continu de manière simple en appliquant une réonctionnement temporelle dans le contexte de Chaque seau de données utilisé pour mettre à jour séquentiellement le modèle. Cette proposition conserve encore certaines limites de l’apprentissage continu, par exemple, les mises à jour du modèle sont effectuées uniquement sur la plupart des données récentes, et toutes les décisions d’optimisation (y compris notre repondération) ne sont prises que sur ces données. Néanmoins, notre approche bat systématiquement l’apprentissage continu régulier ainsi qu’un large éventail d’autres algorithmes d’apprentissage continu sur la référence de catégorisation de photos (voir ci-dessous). Étant donné que notre approche est complémentaire des idées dans de nombreuses lignes de base par rapport ici, nous prévoyons des gains encore plus importants lorsqu’ils sont combinés avec eux.
 |
| Résultats de notre méthode adaptés à l’apprentissage continu, par rapport aux dernières lignes de base. |
Conclusion
Nous avons relevé le défi de la dérive des données dans l’apprentissage en combinant les forces des approches précédentes – l’apprentissage hors ligne avec sa réutilisation efficace des données et l’apprentissage continu en mettant l’accent sur les données plus récentes. Nous espérons que notre travail aide à améliorer la robustesse du modèle à la dérive du concept dans la pratique et génère un intérêt accru et de nouvelles idées pour résoudre le problème omniprésent de la dérive lente du concept.
Remerciements
Nous remercions Mike Mozer pour de nombreuses discussions intéressantes au début de ce travail, ainsi que des conseils et des commentaires très utiles pendant son développement.
Source link



