
Agents d’IA dans les flux de travail d’analyse: trop tôt ou déjà derrière?
- Intelligence Artificielle
 Noesis News
Noesis News- 0
- 16 minutes de lecture

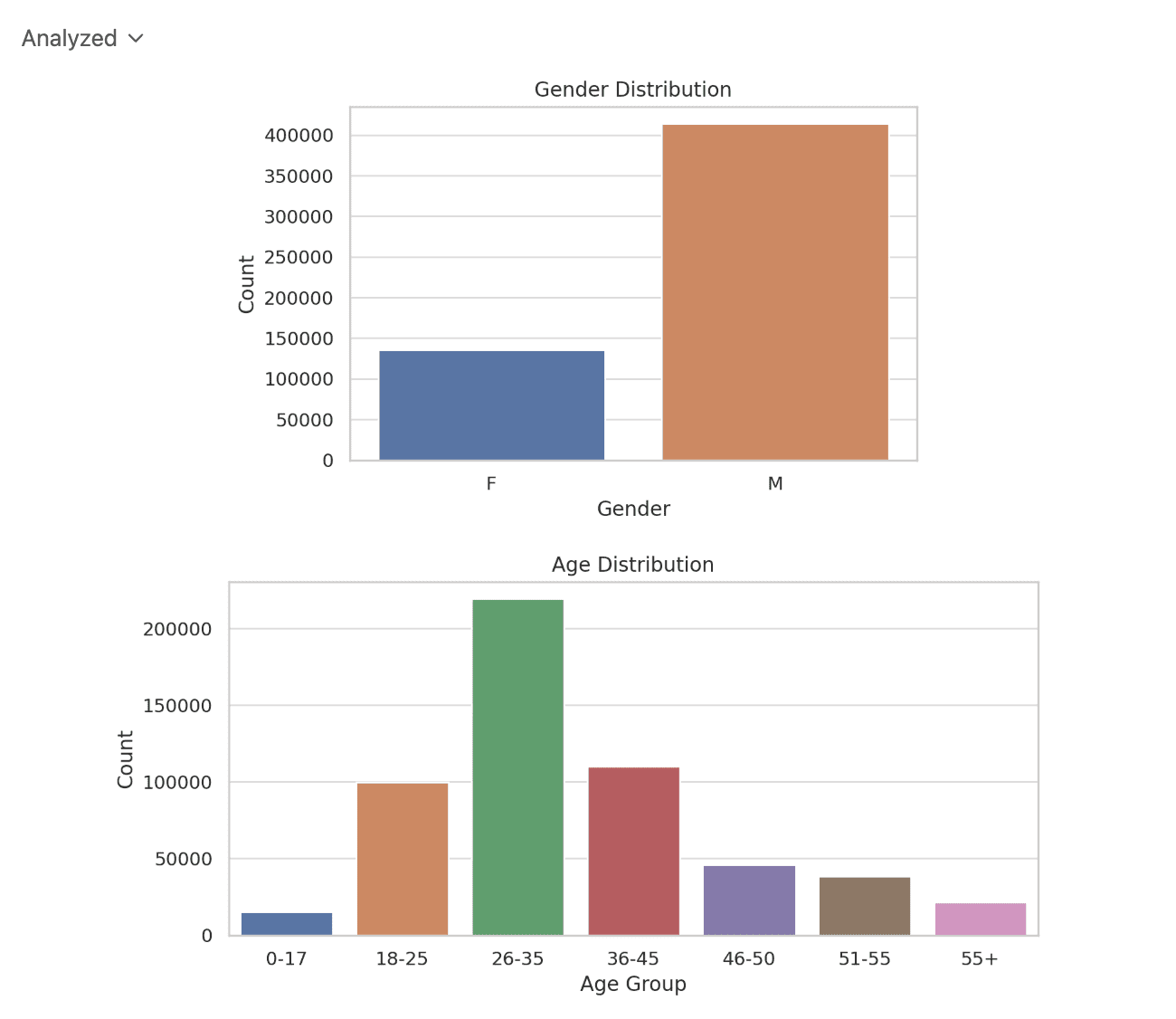
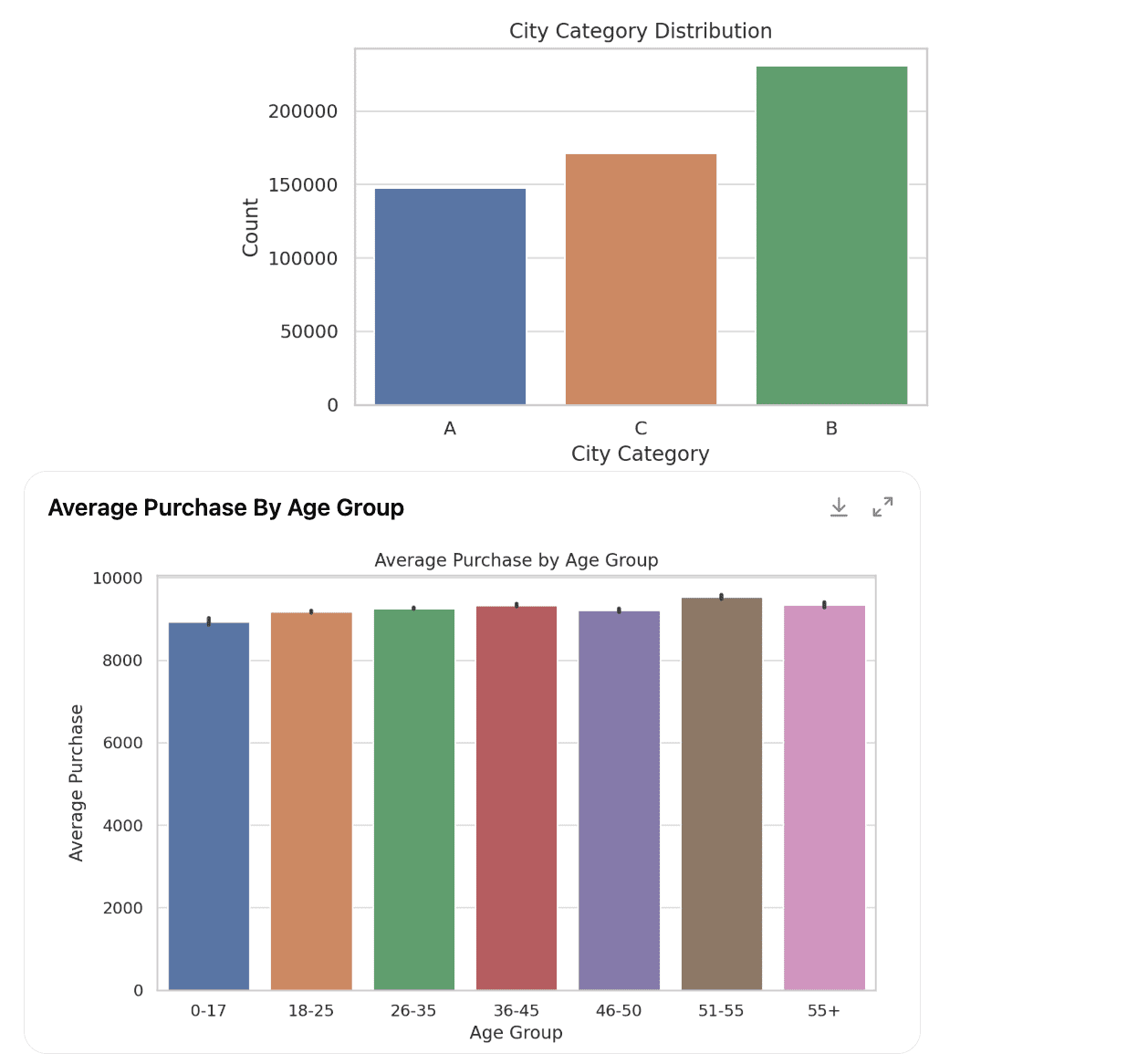




Image de l’auteur | Toile
« Les agents de l’IA deviendront une partie intégrante de notre vie quotidienne, nous aidant à tout, de la planification des rendez-vous à la gestion de nos finances. Ils rendront notre vie plus pratique et efficace. »
—Andrew ng
Après la popularité croissante des modèles de grands langues (LLM), la prochaine grande chose est les agents de l’IA. Comme l’a dit Andrew Ng, ils feront partie de notre vie quotidienne, mais comment cela affectera-t-il les flux de travail analytiques? Cela peut-il être la fin de l’analyse manuelle des données ou améliorer le flux de travail existant?
Dans cet article, nous avons essayé de découvrir la réponse à cette question et d’analyser le calendrier pour voir s’il est trop tôt pour le faire ou trop tard.
Le passé d’analyse de données
L’analyse des données n’était pas aussi facile ou rapide qu’aujourd’hui. En fait, il a traversé plusieurs phases différentes. Il est façonné par la technologie de son temps et la demande croissante de prise de décision basée sur les données des entreprises et des particuliers.
La domination de Microsoft Excel
Dans les années 90 et au début des années 2000, nous avons utilisé Microsoft Excel pour tout. N’oubliez pas ces affectations ou tâches scolaires sur votre lieu de travail. Vous avez dû combiner des colonnes et les trier en écrivant de longues formules. Il n’y a pas trop de sources où vous pouvez les apprendre, donc les cours sont très populaires.
De grands ensembles de données ralentiraient ce processus et la construction d’un rapport était manuelle et répétitive.
La montée de SQL, Python, R
Finalement, Excel a commencé à échouer. Ici, SQL est intervenu. Et il a été le Rockstar depuis. Il est structuré, évolutif et rapide. Vous vous souvenez probablement de la première fois que vous avez utilisé SQL; En quelques secondes, il a fait l’analyse.
R était là, mais avec la croissance de Python, il a également été amélioré. Python, c’est comme parler avec des données en raison de sa syntaxe. Maintenant, les tâches complexes pourraient être effectuées en quelques minutes. Les entreprises l’ont également remarqué, et tout le monde cherchait des talents qui pouvaient travailler avec SQL, Python et R. C’était la nouvelle norme.
Tableaux de bord bi partout
Après 2018, un nouveau quart de travail s’est produit. Des outils comme Tableau et Power BI font l’analyse des données en cliquant simplement, et ils offrent des visualisations incroyables à la fois, appelées tableaux de bord. Ces outils sans code sont devenus populaires si rapidement, et toutes les entreprises modifient désormais leurs descriptions de travail.
Les expériences Powerbi ou Tableau sont un must!
L’avenir: entrée des LLM
Ensuite, de grands modèles de langue entrent en scène et quelle entrée c’était! Tout le monde parle des LLM et essaie de les intégrer dans son flux de travail. Vous pouvez voir les titres de l’article trop souvent, « LLMS remplacera-t-il les analystes de données?».
Cependant, les premières versions de LLMS n’ont pas pu proposer une analyse automatisée des données avant l’interprète de code ChatGpt. C’est le changement de jeu qui a le plus effrayé les analystes de données, car il a commencé à montrer que les workflows d’analyse de données pourraient être automatisés en un clic. Comment? Voyons.
Exploration des données avec LLMS
Considérez ce projet de données: les achats du Black Friday. Il a été utilisé comme une affectation à emporter dans le processus de recrutement pour la position de la science des données chez Walmart.
Voici le lien vers ce projet de données: https://platform.stratascratch.com/data-projects/black-friday-purchases
Visitez, téléchargez l’ensemble de données et téléchargez-le sur chatgpt. Utilisez cette structure rapide:
I have attached my dataset.
Here is my dataset description:
(Copy-paste from the platform)
Perform data exploration using visuals.
Voici la première partie de la sortie.
Mais il n’a pas encore terminé. Cela continue, alors voyons ce qu’il a d’autre pour nous montrer.
Nous avons maintenant un résumé global de l’ensemble de données et des visualisations. Examinons la troisième partie de l’exploration des données, qui est maintenant verbale.
La meilleure partie? Il a fait tout cela en quelques secondes. Mais les agents de l’IA sont un peu plus avancés que cela. Alors, construisons un agent d’IA qui automatise l’exploration des données.
Agents d’analyse de données
Les agents sont allés un pas plus loin que l’interaction LLM traditionnelle. Aussi puissants que soient ces LLM, il semblait que quelque chose manquait. Ou est-ce juste une envie inévitable pour l’humanité de découvrir une intelligence qui dépasse la leur? Pour les LLM, vous avez dû les inciter comme nous l’avons fait ci-dessus, mais pour les agents d’analyse de données, ils n’ont même pas besoin d’intervention humaine. Ils feront tout eux-mêmes.
Implémentation de l’agent d’exploration et de visualisation des données
Construisons un agent ensemble. Pour ce faire, nous utiliserons Langchain et rationaliserons.
Configuration de l’agent
Tout d’abord, installons toutes les bibliothèques.
import streamlit as st
import pandas as pd
warnings.filterwarnings('ignore')
from langchain_experimental.agents.agent_toolkits import create_pandas_dataframe_agent
from langchain_openai import ChatOpenAI
from langchain.agents.agent_types import AgentType
import io
import warnings
import matplotlib.pyplot as plt
import seaborn as sns
Notre agent rationalisé vous permet de télécharger un fichier CSV ou Excel avec ce code.
api_key = "api-key-here"
st.set_page_config(page_title="Agentic Data Explorer", layout="wide")
st.title("Chat With Your Data — Agent + Visual Insights")
uploaded_file = st.file_uploader("Upload your CSV or Excel file", type=("csv", "xlsx"))
if uploaded_file:
# Read file
if uploaded_file.name.endswith(".csv"):
df = pd.read_csv(uploaded_file)
elif uploaded_file.name.endswith(".xlsx"):
df = pd.read_excel(uploaded_file)
Ensuite, les codes d’exploration des données et de visualisation des données arrivent. Comme vous pouvez le voir, il y en a if Blocs qui appliqueront votre code en fonction des caractéristiques des ensembles de données téléchargés.
# --- Basic Exploration ---
st.subheader("📌 Data Preview")
st.dataframe(df.head())
st.subheader("🔎 Basic Statistics")
st.dataframe(df.describe())
st.subheader("📋 Column Info")
buffer = io.StringIO()
df.info(buf=buffer)
st.text(buffer.getvalue())
# --- Auto Visualizations ---
st.subheader("📊 Auto Visualizations (Top 2 Columns)")
numeric_cols = df.select_dtypes(include=("int64", "float64")).columns.tolist()
categorical_cols = df.select_dtypes(include=("object", "category")).columns.tolist()
if numeric_cols:
col = numeric_cols(0)
st.markdown(f"### Histogram for `{col}`")
fig, ax = plt.subplots()
sns.histplot(df(col).dropna(), kde=True, ax=ax)
st.pyplot(fig)
if categorical_cols:
# Limiting to the top 15 categories by count
top_cats = df(col).value_counts().head(15)
st.markdown(f"### Top 15 Categories in `{col}`")
fig, ax = plt.subplots()
top_cats.plot(kind='bar', ax=ax)
plt.xticks(rotation=45, ha="right")
st.pyplot(fig)
Ensuite, configurez un agent.
st.divider()
st.subheader("🧠 Ask Anything to Your Data (Agent)")
prompt = st.text_input("Try: 'Which category has the highest average sales?'")
if prompt:
agent = create_pandas_dataframe_agent(
ChatOpenAI(
temperature=0,
model="gpt-3.5-turbo", # Or "gpt-4" if you have access
api_key=api_key
),
df,
verbose=True,
agent_type=AgentType.OPENAI_FUNCTIONS,
**{"allow_dangerous_code": True}
)
with st.spinner("Agent is thinking..."):
response = agent.invoke(prompt)
st.success("✅ Answer:")
st.markdown(f"> {response('output')}")
Tester l’agent
Maintenant, tout est prêt. Enregistrez-le comme:
Ensuite, accédez au répertoire de travail de ce fichier de script et exécutez-le à l’aide de ce code:
Et, le tour est joué!
Votre agent est prêt, testons-le!
Réflexions finales
Dans cet article, nous avons analysé l’évolution de l’analyse des données commençant dans les années 90 à aujourd’hui, d’Excel aux agents LLM. Nous avons analysé Cet ensemble de données réelqui a été interrogé dans un entretien d’embauche de science des données réelle, en utilisant Chatgpt.
Enfin, nous avons développé un agent qui automatise l’exploration des données et la visualisation des données en utilisant Streamlit, Langchain et d’autres bibliothèques Python, qui est une intersection du flux de travail d’analyse des données passées et nouvelles. Et nous avons tout fait en utilisant un projet de données réel.
Que vous les adoptiez aujourd’hui ou demain, les agents de l’IA ne sont plus une tendance future; En fait, ils sont la prochaine phase d’analyse.
Nate Rosidi est un scientifique des données et en stratégie de produit. Il est également professeur auxiliaire qui enseigne l’analyse et est le fondateur de Stratascratch, une plate-forme aidant les scientifiques des données à se préparer à leurs entretiens avec de véritables questions d’entrevue de grandes entreprises. Nate écrit sur les dernières tendances du marché de la carrière, donne des conseils d’entrevue, partage des projets de science des données et couvre tout SQL.
Source link



