
Accélérer la préparation des données et la collaboration de l’IA à grande échelle
- Intelligence Artificielle
 Noesis News
Noesis News- 0
- 20 minutes de lecture



La vitesse, l’échelle et la collaboration sont essentielles pour les équipes d’IA – mais des données structurées limitées, des ressources de calcul et des workflows centralisés restent sur le chemin.
Que vous soyez un client Datarobot ou un praticien d’IA à la recherche de façons plus intelligentes de préparer et de modéliser de grands ensembles de données, nouveaux outils Comme l’apprentissage incrémentiel, la reconnaissance optique des caractères (OCR) et la préparation améliorée des données élimineront les barrages routiers, vous aidant à construire des modèles plus précis en moins de temps.
Voici ce qui est nouveau dans le Expérience Datarobot Workbench:
- Apprentissage incrémentiel: Modéliser efficacement de grands volumes de données avec une plus grande transparence et contrôle.
- Reconnaissance de caractères optiques (OCR): Convertir instantanément les PDF numérisés non structurés en données utilisables pour prédictif et Génératif AJ’utilise des cas.
- Collaboration plus facile: Travaillez avec votre équipe dans un espace unifié avec un accès partagé à la préparation des données, au développement générateur d’IA et aux outils de modélisation prédictive.
Modèle efficacement sur de grands volumes de données avec un apprentissage incrémentiel
Les modèles de construction avec de grands ensembles de données conduisent souvent à surprendre les coûts de calcul, les inefficacités et les dépenses en fuite. L’apprentissage incrémentiel supprime ces barrières, vous permettant de modéliser sur de grands volumes de données avec précision et contrôle.
Au lieu de traiter un ensemble de données entier à la fois, l’apprentissage incrémentiel exécute des itérations successives sur vos données de formation, en utilisant uniquement autant de données que nécessaire pour atteindre une précision optimale.
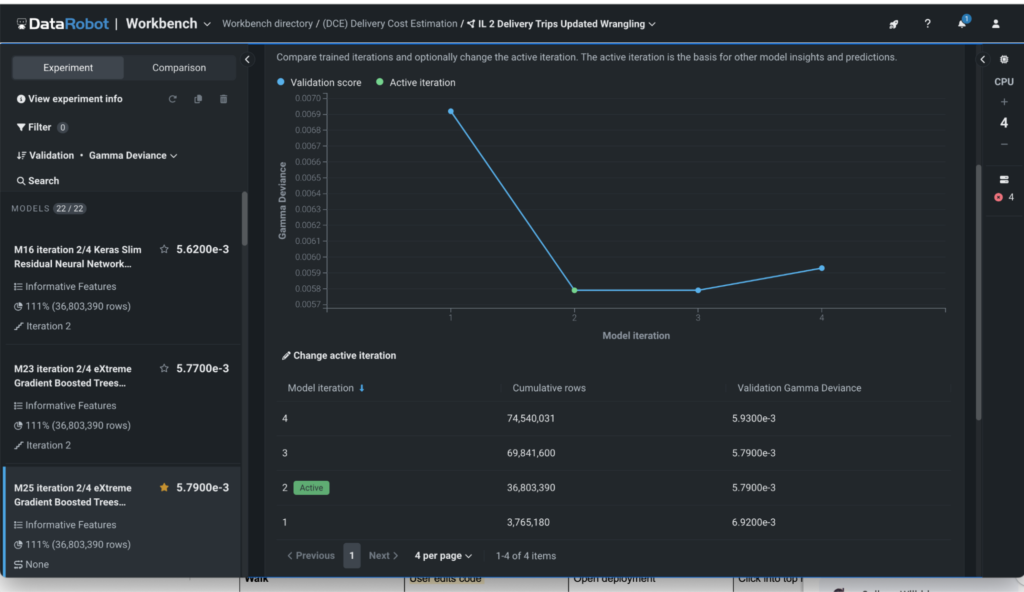
Chaque itération est visualisée sur un graphique (voir figure 1), où vous pouvez suivre le nombre de lignes traitées et la précision acquises – toutes en fonction de la métrique que vous choisissez.
Avantages clés de apprentissage incrémentiel:
- Traitez uniquement les données qui entraînent des résultats.
L’apprentissage incrémentiel arrête automatiquement les travaux lorsque les rendements diminués sont détectés, garantissant que vous utilisez juste assez de données pour obtenir une précision optimale. Dans Datarobot, chaque itération est suivie, vous verrez donc clairement combien de données donne les résultats les plus forts. Vous êtes toujours en contrôle et pouvez personnaliser et exécuter des itérations supplémentaires pour bien faire les choses.
- S’entraîner sur la bonne quantité de données
L’apprentissage incrémentiel empêche le sur-ajustement en itérant sur des échantillons plus petits, donc votre modèle apprend des modèles – pas seulement les données de formation.
- Automatiser les workflows complexes:
Assurez-vous que ce provisionnement de données est rapide et sans erreur. Les utilisateurs avancés de code, d’abord, peuvent aller plus loin et rationaliser le recyclage en utilisant des poids enregistrés pour ne traiter que de nouvelles données. Cela évite la nécessité de relancer l’ensemble de données à partir de zéro, réduisant les erreurs de la configuration manuelle.
Quand tirer le meilleur parti de l’apprentissage incrémentiel
Il existe deux scénarios clés où l’apprentissage incrémentiel entraîne l’efficacité et le contrôle:
- Emplois de modélisation unique
Vous pouvez personnaliser un arrêt anticipé sur de grands ensembles de données pour éviter un traitement inutile, prévenir le sur-ajustement et assurer la transparence des données.
- Modèles dynamiques et régulièrement mis à jour
Pour les modèles qui réagissent à de nouvelles informations, les utilisateurs avancés de code peuvent créer des pipelines qui ajoutent de nouvelles données aux ensembles de formation sans rediffusion complète.
Contrairement à d’autres plates-formes d’IA, l’apprentissage incrémentiel vous donne le contrôle des grands travaux de données, ce qui les rend plus rapides, plus efficaces et moins coûteux.
Comment la reconnaissance optique des caractères (OCR) prépare des données non structurées pour l’IA
Avoir accès à de grandes quantités de données utilisables peut être un obstacle à la création de modèles prédictifs précis et à des chatbots de génération auprès de la récupération (RAG). Cela est particulièrement vrai car les données de l’entreprise de 80 à 90% sont des données non structurées, ce qui peut être difficile à traiter. L’OCR supprime cette barrière en transformant les PDF numérisés en un format utilisable et consultable pour une IA prédictive et générative.
Comment ça marche
OCR est une capacité de code d’abord dans DatarObot. En appelant l’API, vous pouvez transformer un fichier zip de PDF numérisés en un ensemble de données de PDF pendés par texte. Le texte extrait est intégré directement dans le document PDF, prêt à être accessible par Documenter les fonctionnalités de l’IA.
Comment l’OCR peut alimenter l’IA multimodale
Notre nouvelle fonctionnalité OCR n’est pas uniquement pour les bases de données génératrices d’IA ou de vecteur. Il simplifie également la préparation des données prêtes pour l’AI pour les modèles prédictifs multimodaux, permettant des informations plus riches à partir de diverses sources de données.
Préparation de données d’IA prédictive multimodale
Transformez rapidement les documents numérisés en un ensemble de données de PDF avec du texte intégré. Cela vous permet d’extraire des informations clés et de créer des fonctionnalités de vos modèles prédictifs en utilisant documenter les capacités d’IA.
Par exemple, disons que vous souhaitez prédire les dépenses de fonctionnement, mais que vous avez uniquement accès aux factures numérisées. En combinant OCR, en document l’extraction de texte et une intégration avec le flux d’air Apache, vous pouvez transformer ces factures en une puissante source de données pour votre modèle.
Alimenter les LLM de chiffon avec des bases de données vectorielles
Les grandes bases de données vectorielles prennent en charge la génération (RAG) (RAG) plus précise de récupération pour les LLM, en particulier lorsqu’elles sont prises en charge par des ensembles de données plus grands et plus riches. L’OCR joue un rôle clé en transformant les PDF numérisés en PDF en texte, ce qui rend ce texte utilisable en tant que vecteurs pour alimenter les réponses LLM plus précises.
Cas d’utilisation pratique
Imaginez construire un chatbot de chiffon qui répond aux questions complexes des employés. Les documents des avantages sociaux des employés sont souvent denses et difficiles à rechercher. En utilisant OCR pour préparer ces documents pour une IA générative, vous pouvez enrichir un LLM, permettant aux employés d’obtenir des réponses rapides et précises dans un format en libre-service.
Migrations de l’ouchette qui stimulent la collaboration
La collaboration peut être l’un des plus grands bloqueurs pour accélérer la livraison d’IA, en particulier lorsque les équipes sont obligées de travailler sur plusieurs outils et sources de données. NextGen Workbench de DatarObot résout cela en unifiant les workflows de modélisation prédictive et générative clés dans un environnement partagé.
Cette migration signifie que vous pouvez créer des modèles prédictifs et génératifs en utilisant à la fois l’interface utilisateur graphique (GUI) et cahiers et codepsages basés sur le code – Tout dans un seul espace de travail. Il amène également de puissantes capacités de préparation des données dans le même environnement, afin que les équipes puissent collaborer sur des flux de travail de l’IA de bout en bout sans outils.
Accélérer la préparation des données où vous développez des modèles
La préparation des données prend souvent jusqu’à 80% du temps d’un scientifique des données. Le Workbench NextGen rationalise ce processus avec:
- Détection de la qualité des données et guérison automatisée des données: Identifier et résoudre les problèmes tels que les valeurs manquantes, les valeurs aberrantes et les erreurs de format automatiquement.
- Détection et réduction automatisées des fonctionnalités: Identifiez automatiquement les fonctionnalités clés et supprimez-les à faible impact, en réduisant le besoin d’ingénierie des fonctionnalités manuelles.
- Visualisations prêtes à l’emploi de l’analyse des données: Générez instantanément des visualisations interactives pour explorer les ensembles de données et les tendances ponctuelles.
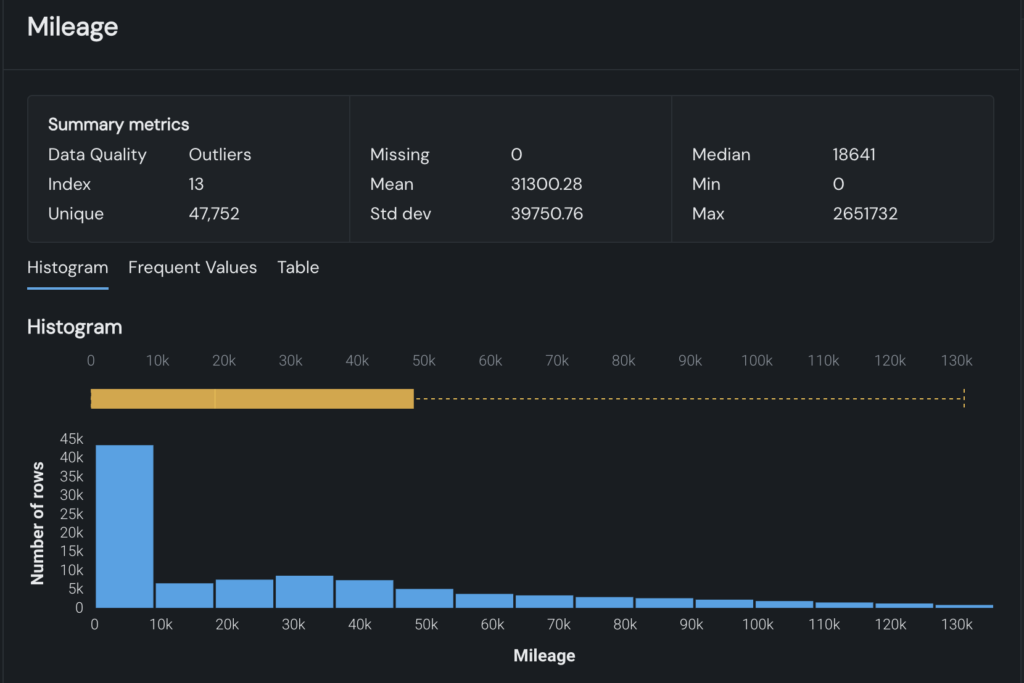
Améliorer la qualité des données et visualiser instantanément les problèmes
Les problèmes de qualité des données tels que les valeurs manquantes, les valeurs aberrantes et les erreurs de format peuvent ralentir le développement de l’IA. Le NextGen Workbench aborde cela avec des analyses automatisées et des informations visuelles qui font gagner du temps et réduisent les efforts manuels.
Maintenant, lorsque vous téléchargez un ensemble de données, les analyses automatiques vérifient les problèmes de qualité des données clés, notamment:
- Aberrements
- Erreurs de format multicategorique
- Insérents
- Excès de zéros
- Valeurs manquantes déguisées
- Fuite cible
- Images manquantes (dans des ensembles de données d’image uniquement)
- PII
Ces vérifications de la qualité des données sont associées à des visualisations EDA (analyse des données exploratoires) prêtes à l’emploi. Les nouveaux ensembles de données sont automatiquement visualisés dans des graphiques interactifs, vous offrant une visibilité instantanée dans les tendances des données et les problèmes potentiels, sans avoir à créer vous-même des graphiques. La figure 3 ci-dessous montre comment les problèmes de qualité sont mis en évidence directement dans le graphique.
Automatiser la détection des fonctionnalités et réduire la complexité
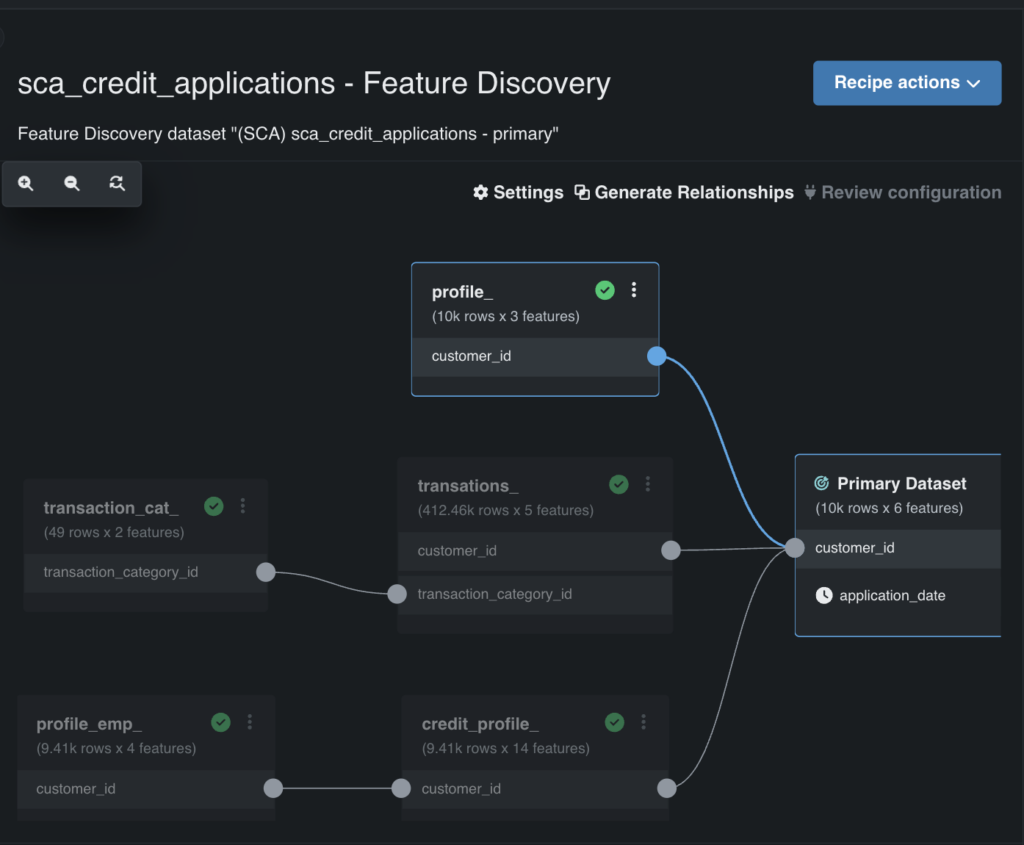
La détection automatisée des fonctionnalités vous aide à simplifier l’ingénierie des fonctionnalités, ce qui facilite l’adhésion à des ensembles de données secondaires, à détecter les fonctionnalités clés et à supprimer celles à faible impact.
Cette capacité analyse tous vos ensembles de données secondaires pour trouver des similitudes – comme les ID client (voir la figure 4) – et vous permet de les rejoindre automatiquement dans un ensemble de données de formation. Il identifie et supprime également les caractéristiques à faible impact, réduisant la complexité inutile.
Vous maintenez le contrôle total, avec la possibilité d’examiner et de personnaliser les fonctionnalités incluses ou exclues.
Ne laissez pas les flux de travail lents vous ralentir
La préparation des données n’a pas à prendre 80% de votre temps. Les outils déconnectés n’ont pas à ralentir vos progrès. Et les données non structurées ne doivent pas être hors de portée.
Avec NextGen Soelbenchvous avez les outils pour vous déplacer plus rapidement, simplifier les flux de travail et construire avec moins d’effort manuel. Ces fonctionnalités sont déjà à votre disposition – il s’agit simplement de les mettre au travail.
Si vous êtes prêt à voir ce qui est possible, explorez l’expérience NextGen dans Un essai gratuit.
À propos de l’auteur
Ezra Berger est responsable du marketing de produit senior chez Datarobot. Il a plus de neuf ans d’expérience dans la construction de contenus et de stratégies de mise sur le marché pour le public technique dans l’IA, la science des données et l’ingénierie. Avant Datarobot, Ezra a occupé des rôles similaires chez Snowflake, Doordash et Grid Dynamics. Il est titulaire d’un BA de l’Université de Californie à Los Angeles.
Source link



