
Intervenant sur les lectures précoces pour atténuer les caractéristiques parasites et la simplicité bi
- Intelligence Artificielle
 Noesis News
Noesis News- 0
- 22 minutes de lecture






Les modèles d’apprentissage automatique dans le monde réel sont souvent formés sur des données limitées qui peuvent contenir des biais statistiques. Par exemple, dans le Célèbre L’ensemble de données d’images de célébrités, un nombre disproportionné de célébrités féminines, a des cheveux blonds, conduisant à des classificateurs prédisant à tort «blonds» comme couleur de cheveux pour la plupart des visages féminins – ici, le genre est une caractéristique parasites pour prédire la couleur des cheveux. De tels biais injustes pourraient avoir des conséquences significatives dans des applications critiques telles que diagnostic médical.
Étonnamment, des travaux récents ont également découvert une tendance inhérente aux réseaux profonds amplifier ces biais statistiquesà travers le soi-disant biais de simplicité de l’apprentissage en profondeur. Ce biais est la tendance des réseaux profonds à identifier les caractéristiques faiblement prédictives au début de la formation et à continuer à ancrer ces fonctionnalités, n’ayant pas identifié de fonctionnalités plus complexes et potentiellement plus précises.
Dans l’esprit ci-dessus, nous proposons des correctifs simples et efficaces à ce double défi de caractéristiques parasites et de biais de simplicité en appliquant lectures précoces et fonctionnalité oubliant. Premièrement, dans «Utilisation de lectures précoces pour médier les biais features de la distillation», Nous montrons que la fabrication de prédictions à partir des premières couches d’un réseau profond (appelé« lectures précoces ») peut automatiquement signaler les problèmes avec la qualité des représentations apprises. En particulier, ces prédictions sont plus souvent erronées, et plus en toute confiance, lorsque le réseau s’appuie sur des caractéristiques parasites. Nous utilisons cette confiance erronée pour améliorer les résultats dans distillation du modèleun cadre où un modèle plus grand «enseignant» guide la formation d’un modèle plus petit «étudiant». Puis dans « Surmonter les biais de simplicité dans les réseaux profonds à l’aide d’un tamis de fonctionnalité», Nous intervenons directement sur ces signaux indicateurs en faisant« oublier »le réseau les fonctionnalités problématiques et par conséquent rechercher des fonctionnalités meilleures et plus prédictives. Cela améliore considérablement la capacité du modèle à se généraliser aux domaines invisibles par rapport aux approches précédentes. Notre Principes d’IA et notre Pratiques d’IA responsables Guidons la façon dont nous recherchons et développons ces applications avancées et nous aidons à relever les défis posés par les biais statistiques.
 |
| Animation comparant les réponses hypothétiques de deux modèles formés avec et sans le tamis de fonction. |
Lectures précoces pour la distillation Debiasing
Nous illustrons d’abord la valeur diagnostique de lectures précoces et leur application dans la distillation débiasée, c’est-à-dire en s’assurant que le modèle d’élève hérite de la résilience du modèle enseignant pour comporter le biais par la distillation. Nous commençons par un cadre de distillation standard où l’élève est formé avec un mélange de correspondance d’étiquettes (minimisant le perte d’entropie entre les sorties des élèves et les étiquettes de la vérité au sol) et la correspondance des enseignants (minimisant le Divergence kl Perte entre les sorties de l’élève et de l’enseignant pour une entrée donnée).
Supposons que l’on entraîne un décodeur linéaire, c’est-à-dire un petit réseau neuronal auxiliaire nommé comme Aux, en plus d’une représentation intermédiaire du modèle étudiant. Nous appelons la sortie de ce décodeur linéaire comme une lecture précoce de la représentation du réseau. Notre constatation est que les lectures précoces font plus d’erreurs dans les cas qui contiennent des caractéristiques parasites, et en outre, la confiance sur ces erreurs est plus élevée que la confiance associée aux autres erreurs. Cela suggère que la confiance des erreurs des lectures précoces est un indicateur automatisé assez fort de la dépendance du modèle à l’égard des caractéristiques potentiellement parasites.
 |
| Illustrant l’utilisation des lectures précoces (c’est-à-dire la sortie de la couche auxiliaire) dans la distillation de la débris. Les cas qui sont mal prédités dans les premières lectures sont parvenus à la perte de la perte de distillation. |
Nous avons utilisé ce signal pour moduler la contribution de l’enseignant dans la perte de distillation par instance, et avons donc trouvé des améliorations significatives du modèle d’étudiant formé.
Nous avons évalué notre approche sur les ensembles de données de référence standard connus pour contenir des corrélations parasites (Oiseaux d’eau, Célèbre, Civils, MNLI). Chacun de ces ensembles de données contient des groupements de données qui partagent un attribut potentiellement corrélé avec l’étiquette de manière parasite. Par exemple, l’ensemble de données Celeba mentionné ci-dessus comprend des groupes tels que {mâle blond, femelle blonde, mâle non blonde, femelle non blonde}, avec des modèles effectuant généralement le pire du groupe {non blonde} lors de la prévision de la couleur des cheveux. Ainsi, une mesure des performances du modèle est son Pire précision de groupec’est-à-dire la plus faible précision parmi tous les groupes connus présents dans l’ensemble de données. Nous avons amélioré la pire précision de groupe des modèles d’étudiants sur tous les ensembles de données; De plus, nous avons également amélioré la précision globale dans trois des quatre ensembles de données, montrant que notre amélioration par rapport à un seul groupe ne se fait pas au détriment de la précision sur d’autres groupes. Plus de détails sont disponibles dans notre papier.
 |
| Comparaison des pires précisions de groupe de différentes techniques de distillation par rapport à celles du modèle enseignant. Notre méthode surpasse les autres méthodes sur tous les ensembles de données. |
Surmonter le biais de simplicité avec un tamis de fonctionnalité
Dans un deuxième projet étroitement lié, nous intervenons directement sur les informations fournies par les lectures précoces, pour améliorer apprentissage des fonctionnalités et généralisation. Le workflow alterne entre identifiant Caractéristiques problématiques et Effacer les fonctionnalités identifiées du réseau. Notre principale hypothèse est que les premières caractéristiques sont plus sujettes au biais de simplicité, et qu’en effaçant («tamisage») ces caractéristiques, nous permettons à des représentations de caractéristiques plus riches.
 |
| Formation de travail de formation avec tamis de fonction. Nous alternons entre l’identification des fonctionnalités problématiques (en utilisant l’itération de formation) et les effacer du réseau (en utilisant l’itération d’oubli). |
Nous décrivons plus en détail les étapes d’identification et d’effacement:
- Identification des fonctionnalités simples: Nous formons le modèle principal et le modèle de lecture (Aux ci-dessus) de manière conventionnelle via la propagation avant et rétro-propagation. Notez que la rétroaction de la couche auxiliaire ne propage pas le réseau principal. Il s’agit de forcer la couche auxiliaire à apprendre des fonctionnalités déjà disponibles plutôt que de les créer ou de les renforcer dans le réseau principal.
- Appliquer le tamis de fonctionnalité: Nous visons à effacer les caractéristiques identifiées dans les premières couches du réseau neuronal avec l’utilisation d’un roman oublier la perte, Lf qui est simplement l’entropie croisée entre la lecture et une distribution uniforme sur les étiquettes. Essentiellement, toutes les informations qui conduisent à des lectures non triviales sont effacées du réseau principal. Dans cette étape, le réseau auxiliaire et les couches supérieures du réseau principal sont maintenus inchangés.
Nous pouvons contrôler spécifiquement comment le tamis de fonction est appliqué à un ensemble de données donné via un petit nombre de paramètres de configuration. En modifiant la position et la complexité du réseau auxiliaire, nous contrôlons la complexité des fonctionnalités identifiées et effacées. En modifiant le mélange des étapes d’apprentissage et d’oubli, nous contrôlons dans quelle mesure le modèle est mis au défi d’apprendre des caractéristiques plus complexes. Ces choix, dépendants de l’ensemble de données, sont faits via Recherche d’hyperparamètre Pour maximiser la précision de validation, une mesure standard de la généralisation. Étant donné que nous incluons «non-informes» (c’est-à-dire le modèle de base) dans l’espace de recherche, nous nous attendons à trouver des paramètres qui sont au moins aussi bons que la ligne de base.
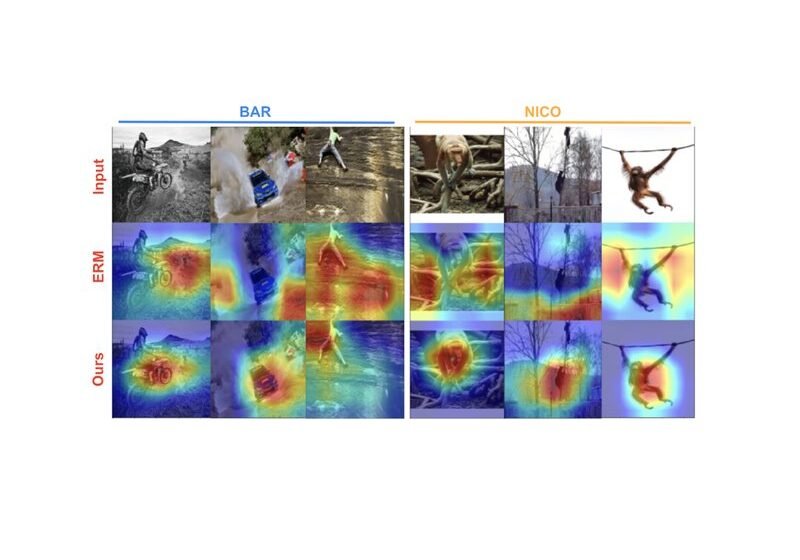
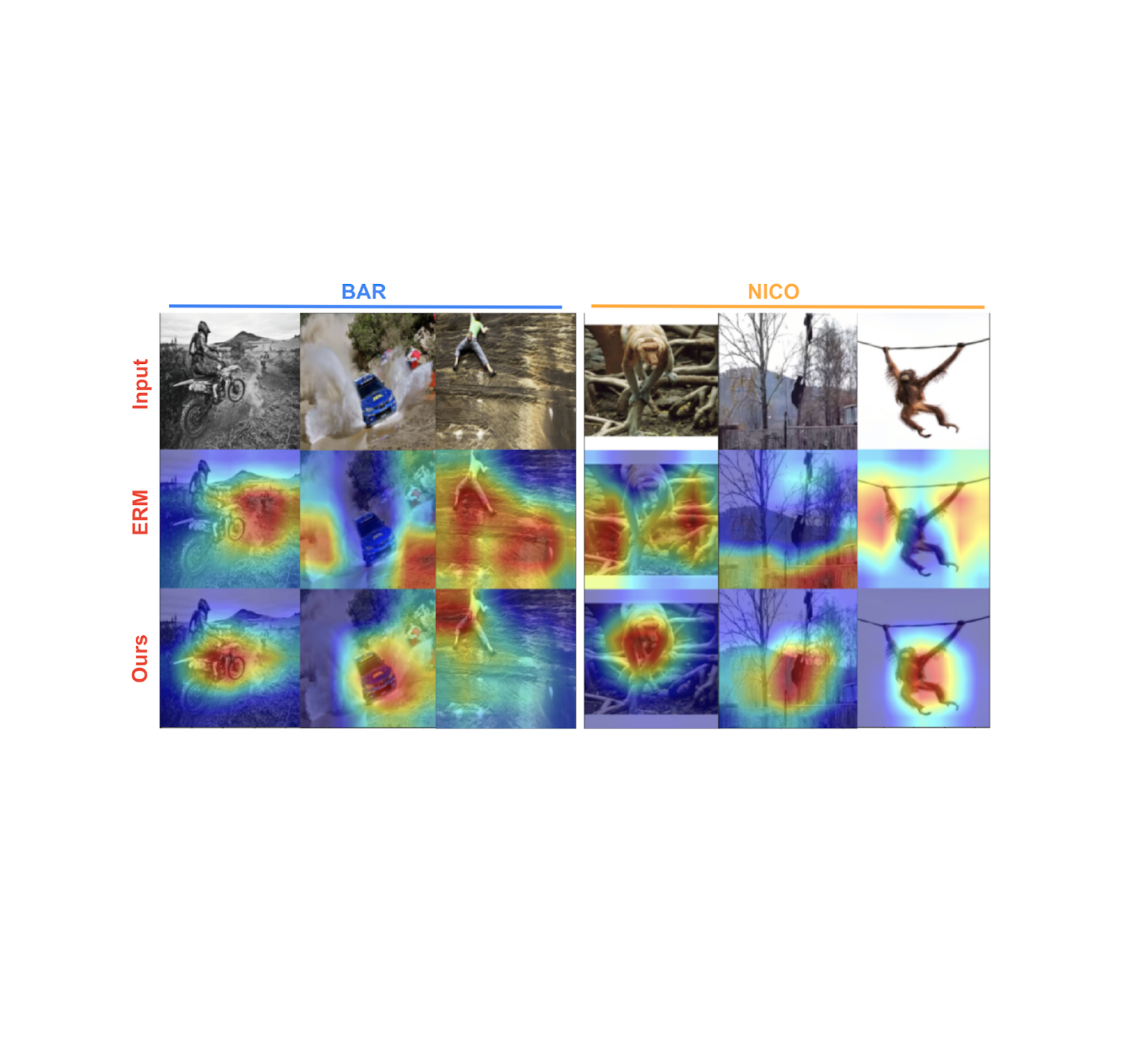
Ci-dessous, nous montrons des fonctionnalités apprises par le modèle de base (rangée moyenne) et notre modèle (rangée inférieure) sur deux ensembles de données de référence – reconnaissance d’activité biaisée (BAR) et la catégorisation des animaux (Nico). L’importance des caractéristiques a été estimée en utilisant une notation d’importance basée sur le gradient post-hoc (Caméra graduelle), avec l’extrémité rouge orange du spectre indiquant une grande importance, tandis que le bleu vert indique une faible importance. Ci-dessous, nos modèles formés se concentrent sur l’objet principal d’intérêt, tandis que le modèle de base a tendance à se concentrer sur les fonctionnalités de fond qui sont plus simples et faussement corrélées avec l’étiquette.
 |
| Caractéristiques de la notation de l’importance en utilisant des repères de généralisation de la reconnaissance d’activité (BAR) et de la catégorisation des animaux (NICO). Notre approche (dernière ligne) se concentre sur les objets pertinents de l’image, tandis que la ligne de base (ERM; rangée moyenne) s’appuie sur des caractéristiques de fond qui sont faussement corrélées avec l’étiquette. |
Grâce à cette capacité à apprendre de meilleures fonctionnalités généralisables, nous montrons des gains substantiels sur une gamme de lignes de base pertinentes sur les ensembles de données de référence parasites du monde réel: BAR, Cheveux de célebe, Nico et Imagenetapar des marges jusqu’à 11% (voir la figure ci-dessous). Plus de détails sont disponibles dans Notre journal.
 |
| Notre méthode de tamis de fonctions améliore la précision par des marges significatives par rapport à la ligne de base la plus proche pour une gamme d’ensembles de données de référence de généralisation des fonctionnalités. |
Conclusion
Nous espérons que nos travaux sur les lectures précoces et leur utilisation dans les caractéristiques de la généralisation stimuleront à la fois le développement d’une nouvelle classe d’approches d’apprentissage adversaires et contribueront à améliorer la capacité de généralisation et la robustesse des systèmes d’apprentissage en profondeur.
Remerciements
Les travaux sur l’application des lectures précoces à la distillation de débias ont été menées en collaboration avec nos partenaires universitaires Durga Sivasubramanian, Anmol Reddy et le professeur Ganesh Ramakrishnan à Iit bombay. Nous exprimons notre sincère gratitude à Praneeth Netrapalli et Anshul Nasery pour leurs commentaires et recommandations. Nous sommes également reconnaissants à Nishant Jain, Shreyas Havaldar, Rachit Bansal, Kartikeya Badola, Amandeep Kaur et toute la cohorte de chercheurs prédoctoraux de Google Research India pour avoir participé à des discussions de recherche. Un merci spécial à Tom Small d’avoir créé l’animation utilisée dans ce post.
Source link



