
Comment cerebras + datarobot accélère le développement d’applications AI
- Intelligence Artificielle
 Noesis News
Noesis News- 0
- 18 minutes de lecture


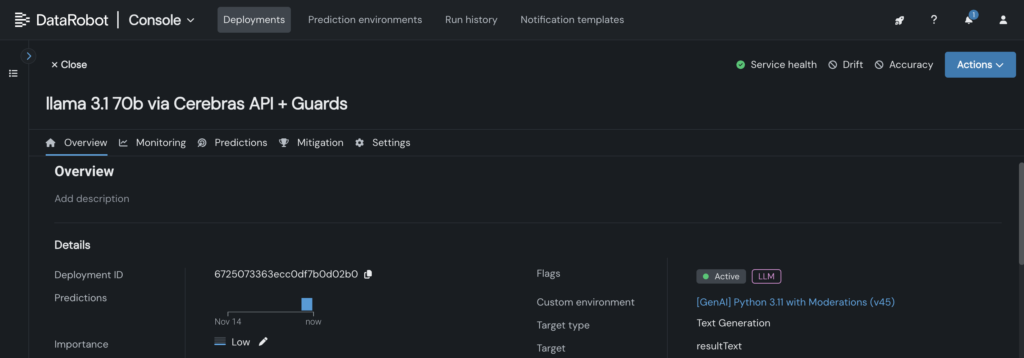


Plus rapide, plus intelligent, plus réactif Applications d’IA – c’est ce à quoi vos utilisateurs attendent. Mais lorsque les modèles de grandes langues (LLM) sont lents à répondre, l’expérience utilisateur en souffre. Chaque milliseconde compte.
Avec les critères de terminaison d’inférence à grande vitesse de Cerebras, vous pouvez réduire la latence, accélérer les réponses du modèle et maintenir la qualité à grande échelle avec des modèles comme Llama 3.1-70b. En suivant quelques étapes simples, vous pourrez personnaliser et déployer vos propres LLM, vous donnant le contrôle pour optimiser à la fois la vitesse et la qualité.
Dans ce blog, nous vous guiderons à travers comment:
- Configurez Llama 3.1-70b dans le Aire de jeux Datarobot LLM.
- Générez et appliquez une clé API pour tirer parti des cerveaux pour l’inférence.
- Personnaliser et déployer des applications plus intelligentes et plus rapides.
À la fin, vous serez prêt à déployer des LLM qui fournissent la vitesse, la précision et la réactivité en temps réel.
Prototype, personnaliser et tester les LLMS en un seul endroit
Le prototypage et le test des modèles d’IA génératifs nécessitent souvent un patchwork d’outils déconnectés. Mais avec un Environnement unifié et intégré pour les LLMTechniques de récupération et mesures d’évaluation, vous pouvez passer de l’idée au prototype de travail plus rapidement et avec moins de barrages routiers.
Ce processus rationalisé Cela signifie que vous pouvez vous concentrer sur la construction d’applications d’IA efficaces et à fort impact sans les tracas de rassembler des outils de différentes plateformes.
Profitons un cas d’utilisation pour voir comment vous pouvez tirer parti de ces capacités pour Développer des applications d’IA plus intelligentes et plus rapides.
Cas d’utilisation: accélérer les interférences LLM sans sacrifier la qualité
La faible latence est essentielle pour construire des applications d’IA rapides et réactives. Mais les réponses accélérées ne doivent pas avoir à venir au prix de la qualité.
La vitesse de Cérébras Inférence surpasse les autres plates-formes, permettant aux développeurs de créer des applications qui se sentent fluide, réactive et intelligente.
Lorsqu’il est combiné avec une expérience de développement intuitive, vous pouvez:
- Réduire la latence LLM Pour des interactions utilisateur plus rapides.
- Expérimenter plus efficacement avec de nouveaux modèles et flux de travail.
- Déployer les demandes qui répondent instantanément aux actions des utilisateurs.
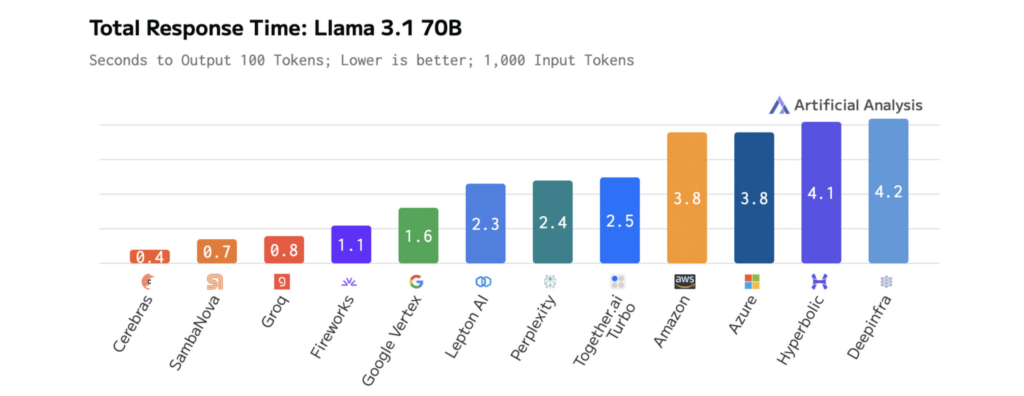
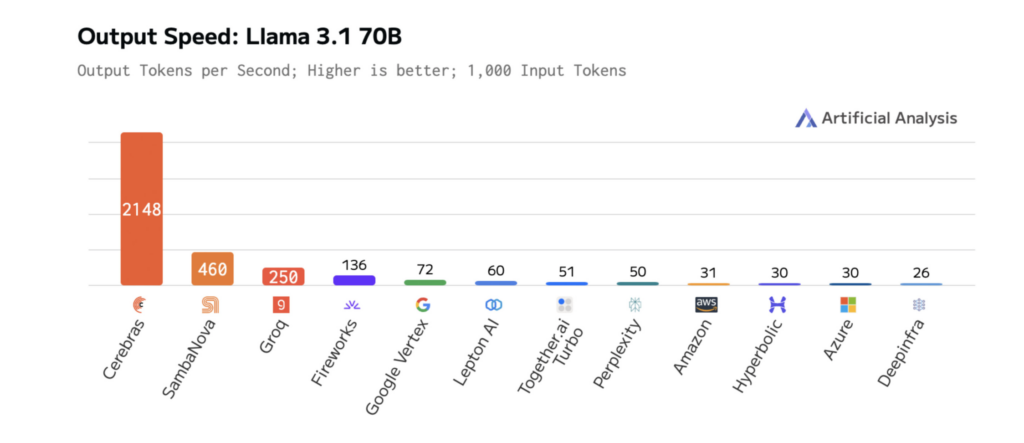
Les diagrammes ci-dessous montrent les performances de Cerebras sur LLAMA 3.1-70B, illustrant les temps de réponse plus rapides et la latence plus faible que les autres plates-formes. Cela permet une itération rapide pendant le développement et des performances en temps réel en production.
Comment la taille du modèle a un impact sur la vitesse et les performances de LLM
À mesure que les LLM deviennent plus grandes et plus complexes, leurs résultats deviennent plus pertinents et plus complets – mais cela a un coût: une latence accrue. Cerebras relève ce défi avec des calculs optimisés, un transfert de données rationalisé et un décodage intelligent conçu pour la vitesse.
Ces améliorations de vitesse transforment déjà les applications d’IA dans des industries comme les produits pharmaceutiques et l’IA de voix. Par exemple:
- GlaxoSmithKline (GSK) utilise l’inférence des cerèvres pour accélérer la découverte de médicaments, ce qui entraîne une productivité plus élevée.
- Livekit a augmenté les performances du pipeline de mode voix de Chatgpt, atteignant des temps de réponse plus rapides que les solutions d’inférence traditionnelles.
Les résultats sont mesurables. Sur Llama 3.1-70b, cerebras offre une inférence 70x plus rapide que les GPU à la vanille, permettant des interactions plus lisses et en temps réel et des cycles d’expérimentation plus rapides.
Cette performance est alimentée par le moteur à l’échelle de plaquette de troisième génération de Cerebras (WSE-3), un processeur personnalisé conçu pour optimiser les opérations d’algèbre linéaire clairsemées basées sur le tenseur qui entraînent une inférence LLM.
En priorisant les performances, l’efficacité et la flexibilité, le WSE-3 garantit des résultats plus rapides et plus cohérents pendant les performances du modèle.
La vitesse de Cerebras Inference réduit la latence des applications d’IA alimentées par leurs modèles, permettant un raisonnement plus profond et des expériences utilisateur plus réactives. L’accès à ces modèles optimisés est simple – ils sont hébergés sur des cerèvres et accessibles via un seul point de terminaison, vous pouvez donc commencer à les utiliser avec une configuration minimale.
Étape par étape: comment personnaliser et déployer LLAMA 3.1-70B pour l’IA à faible latence
Intégrer les LLM comme Llama 3.1-70b de cerebras dans Datarobot Vous permet de personnaliser, tester et déployer des modèles AI en quelques étapes. Ce processus prend en charge un développement plus rapide, des tests interactifs et un plus grand contrôle sur la personnalisation LLM.
1. Générez une clé API pour LLAMA 3.1-70B dans la plate-forme Cerebras.
2. Dans Datarobot, créez un modèle personnalisé dans l’atelier de modèle qui appelle le point de terminaison Cerebras où LLAMA 3.1 70B est hébergé.
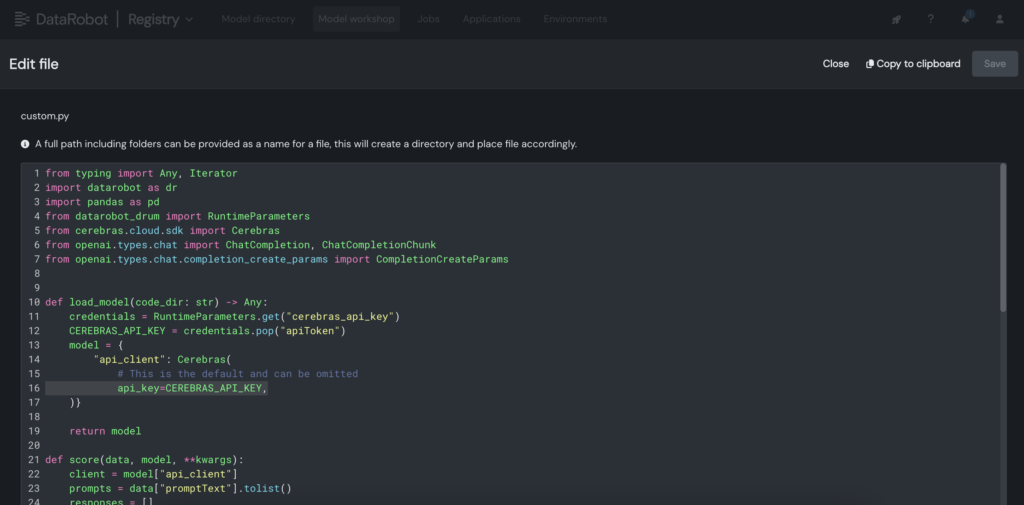
3. Dans le modèle personnalisé, placez la clé API Cerebras dans le fichier personnalisé.py.
4. Déployez le modèle personnalisé sur un point de terminaison dans la console Datarobot, permettant aux Blueprints LLM de le tirer parti pour l’inférence.
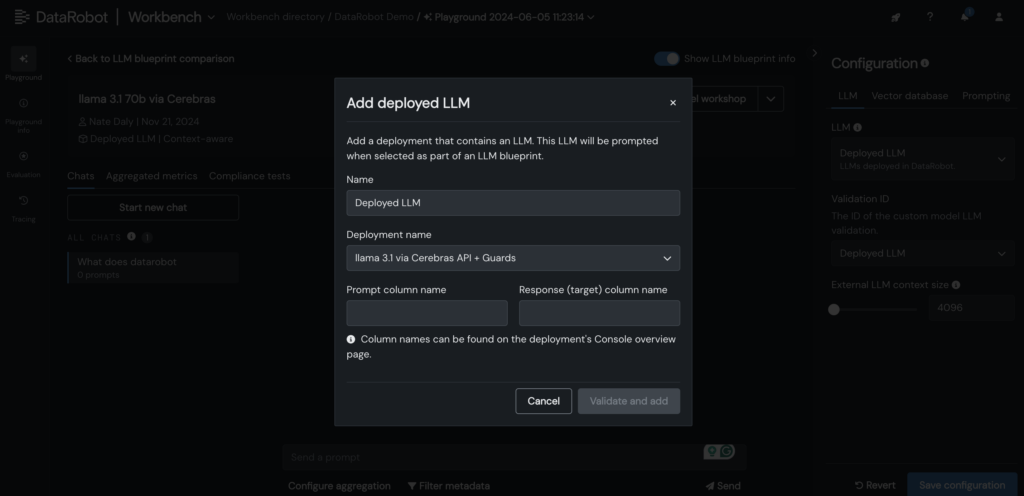
5. Ajoutez votre CEERBRAS LLM déployé au LLM Blueprint dans le terrain de jeu Datarobot LLM pour commencer à discuter avec LLAMA 3.1 -70B.
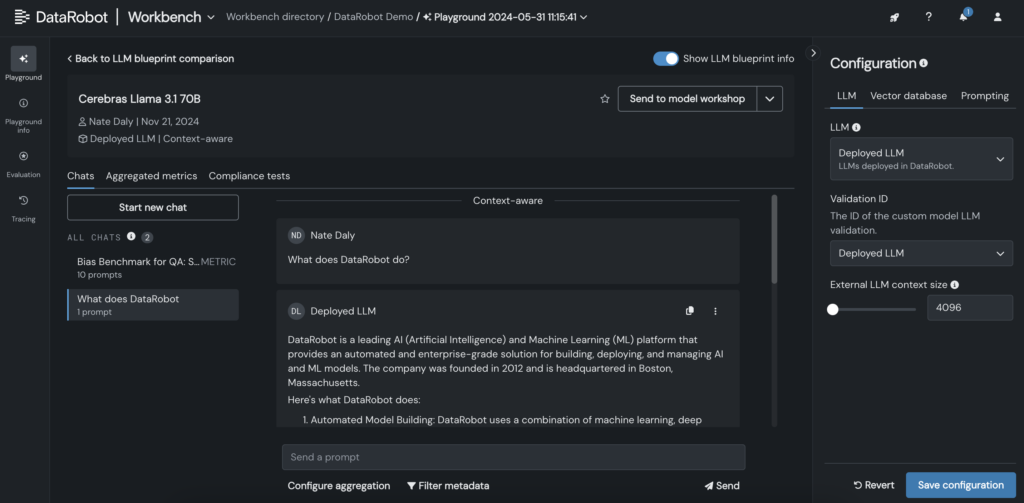
6. Une fois le LLM ajouté au plan, testez les réponses en ajustant les paramètres d’incitation et de récupération, et comparez les sorties avec d’autres LLM directement dans l’interface graphique Datarobot.
Développez les limites de l’inférence LLM pour vos applications d’IA
Le déploiement de LLM comme LLAMA 3.1-70B avec une faible latence et une réactivité en temps réel n’est pas une petite tâche. Mais avec les bons outils et les bons flux de travail, vous pouvez réaliser les deux.
En intégrant LLMS dans le terrain de jeu LLM de Datarobot et en tirant parti de l’inférence optimisée de Cerebras, vous pouvez simplifier la personnalisation, accélérer les tests et réduire la complexité – tout en conservant les performances que vos utilisateurs attendent.
À mesure que les LLM deviennent plus grandes et plus puissantes, avoir un processus rationalisé pour les tests, la personnalisation et l’intégration sera essentiel pour les équipes qui cherchent à rester en avance.
Explorez-le vous-même. Accéder Cérébras InférenceGénérez votre clé API et commencez à construire Applications AI dans Datarobot.
À propos de l’auteur
Kumar Venkateswar est vice-président du produit, de la plate-forme et de l’écosystème chez Datarobot. Il dirige la gestion des produits pour les services fondamentaux de Datarobot et les partenariats écosystémiques, combler les lacunes entre l’infrastructure efficace et les intégrations qui maximisent les résultats de l’IA. Avant Datarobot, Kumar a travaillé sur Amazon et Microsoft, y compris les principales équipes de gestion de produits pour Amazon Sagemaker et Amazon Q Business.
Nathaniel Daly est chef de produit senior chez Datarobot se concentrant sur les produits Automl et Time Series. Il s’est concentré sur l’apport des progrès de la science des données aux utilisateurs afin qu’ils puissent tirer parti de cette valeur pour résoudre les problèmes commerciaux du monde réel. Il est titulaire d’un diplôme en mathématiques de l’Université de Californie à Berkeley.
Source link



