
Modélisation des images extrêmement grandes avec XT – Le blog de recherche de Berkeley Artificial Intelligence Research
- Intelligence Artificielle
 Noesis News
Noesis News- 0
- 15 minutes de lecture

En tant que chercheurs en vision par ordinateur, nous pensons que chaque pixel peut raconter une histoire. Cependant, il semble y avoir un bloc d’écrivain qui s’installe sur le terrain lorsqu’il s’agit de gérer les grandes images. Les grandes images ne sont plus rares – les caméras que nous portons dans nos poches et celles en orbite autour de notre planète Snap Pictures si grandes et détaillées qu’elles étendent nos meilleurs modèles et matériel actuels à leurs points de rupture lors de leur manipulation. Généralement, nous sommes confrontés à une augmentation quadratique de l’utilisation de la mémoire en fonction de la taille de l’image.
Aujourd’hui, nous faisons l’un des deux choix sous-optimaux lors de la manipulation de grandes images: l’échantillonnage ou le recadrage. Ces deux méthodes subissent des pertes importantes dans la quantité d’informations et de contexte présentes dans une image. Nous examinons un autre regard sur ces approches et introduisons $ x $ t, un nouveau cadre pour modéliser de grandes images de bout en bout sur des GPU contemporains tout en agrégeant efficacement le contexte global avec des détails locaux.
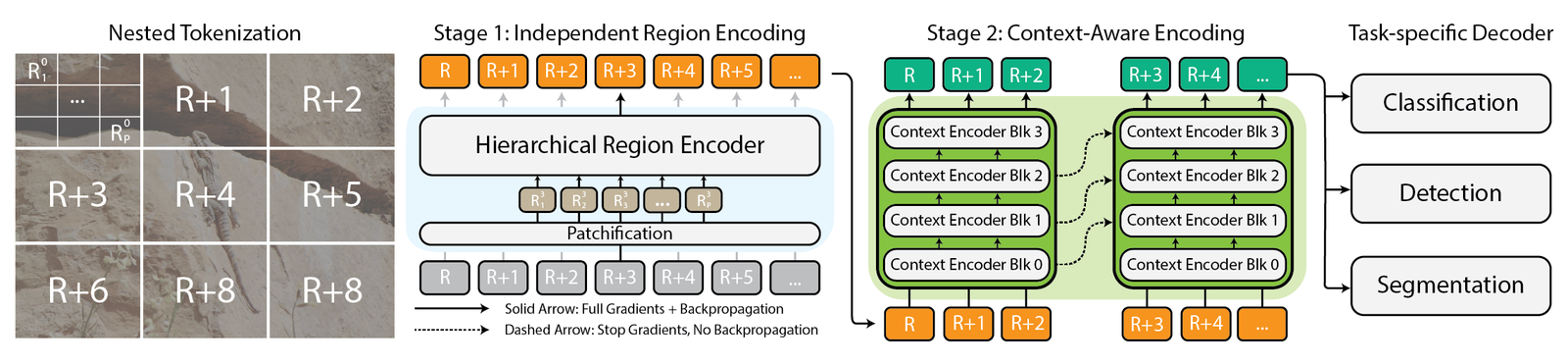
Architecture du framework $ x $ t.
Pourquoi s’embêter avec de grandes images de toute façon?
Pourquoi se soucier de gérer de grandes images de toute façon? Imaginez-vous devant votre télévision, en regardant votre équipe de football préférée. Le champ est parsemé de joueurs partout avec une action ne se produisant que sur une petite partie de l’écran à la fois. Seriez-vous satisfait, cependant, si vous ne pouviez voir qu’une petite région autour de l’endroit où se trouvait le ballon actuellement? Alternativement, seriez-vous satisfaisant à regarder le match en basse résolution? Chaque pixel raconte une histoire, quelle que soit leur distance. Cela est vrai dans tous les domaines de votre écran de télévision à un pathologiste visant une diapositive gigapixel pour diagnostiquer de minuscules plaques de cancer. Ces images sont des trésors d’informations. Si nous ne pouvons pas explorer pleinement la richesse parce que nos outils ne peuvent pas gérer la carte, à quoi ça sert?
Les sports sont amusants quand vous savez ce qui se passe.
C’est précisément là que réside la frustration aujourd’hui. Plus l’image est grande, plus nous avons besoin de zoomer simultanément pour voir l’image entière et zoomer pour les détails de Nitty-Gritty, ce qui rend le défi de saisir à la fois la forêt et les arbres simultanément. La plupart des méthodes actuelles obligent un choix entre perdre de vue la forêt ou manquer les arbres, et aucune des options n’est excellente.
Comment $ x $ t essaie de résoudre ce problème
Imaginez essayer de résoudre un puzzle massif. Au lieu de vous attaquer à la fois en même temps, ce qui serait écrasant, vous commencez avec des sections plus petites, jetez un bon aperçu de chaque pièce, puis déterminez comment elles s’intègrent dans la situation dans son ensemble. C’est essentiellement ce que nous faisons avec de grandes images avec $ x $ t.
$ x $ t prend ces gigantesques images et les coupe en pièces plus petites et plus digestibles hiérarchiquement. Il ne s’agit pas seulement de réduire les choses, cependant. Il s’agit de comprendre chaque pièce à part entière, puis, en utilisant des techniques intelligentes, en déterminant comment ces pièces se connectent à plus grande échelle. C’est comme avoir une conversation avec chaque partie de l’image, apprendre son histoire, puis partager ces histoires avec les autres parties pour obtenir le récit complet.
Tokenisation imbriquée
Au cœur de $ x $ T se trouve le concept de tokenisation imbriquée. En termes simples, la tokenisation dans le domaine de la vision par ordinateur s’apparente à couper une image en morceaux (jetons) qu’un modèle peut digérer et analyser. Cependant, $ x $ t va plus loin en introduisant une hiérarchie dans le processus, d’où, imbriqué.
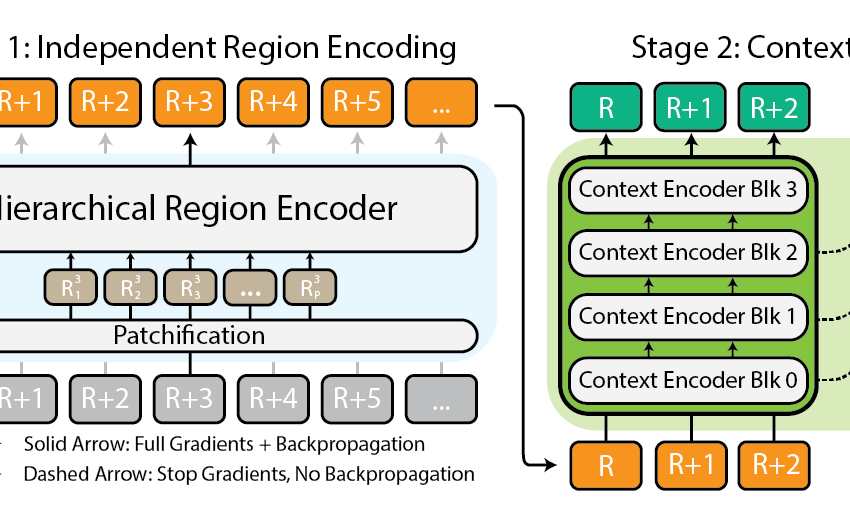
Imaginez que vous êtes chargé d’analyser une carte de la ville détaillée. Au lieu d’essayer de prendre toute la carte à la fois, vous le décomposez en districts, puis en quartiers de ces districts, et enfin, les rues de ces quartiers. Cette ventilation hiérarchique facilite la gestion et la compréhension des détails de la carte tout en gardant une trace de l’endroit où tout s’intègre dans l’image plus large. C’est l’essence de la tokenisation imbriquée – nous avons divisé une image en régions, chacune qui peut être divisée en sous-régions supplémentaires en fonction de la taille d’entrée attendue par une squelette de vision (ce que nous appelons un encodeur de région), avant d’être patchifié pour être traité par ce codeur de région. Cette approche imbriquée nous permet d’extraire des fonctionnalités à différentes échelles au niveau local.
Coordination de la région et des encodeurs de contexte
Une fois qu’une image est soigneusement divisée en jetons, $ x $ t utilise deux types d’encodeurs pour donner un sens à ces pièces: l’encodeur de la région et l’encodeur de contexte. Chacun joue un rôle distinct en rassemblant l’histoire complète de l’image.
L’encodeur de la région est un «expert local» autonome qui convertit les régions indépendantes en représentations détaillées. Cependant, comme chaque région est traitée isolément, aucune information n’est partagée sur l’image en général. L’encodeur de la région peut être n’importe quel squelette de vision ultramoderne. Dans nos expériences, nous avons utilisé des transformateurs de vision hiérarchique tels que Faire un swin et Hiera et aussi CNNS tels que Convoiter!
Entrez dans le codeur de contexte, le gourou à grande échelle. Son travail consiste à prendre les représentations détaillées des encodeurs de la région et à les assembler, garantissant que les idées d’un jeton sont considérées dans le contexte des autres. L’encodeur de contexte est généralement un modèle à longue séquence. Nous expérimentons avec Transformateur-xl (Et notre variante a appelé Hyper) et Mambabien que vous puissiez utiliser Forgeron et d’autres nouvelles avancées dans ce domaine. Même si ces modèles à longue séquence sont généralement conçus pour le langage, nous démontrons qu’il est possible de les utiliser efficacement pour les tâches de vision.
La magie de $ x $ T est dans la façon dont ces composants – la tokenisation imbriquée, les encodeurs régionaux et les encodeurs de contexte – viennent ensemble. En décomposant d’abord l’image en pièces gérables, puis en analysant systématiquement ces pièces à la fois isolément et en conjonction, $ x $ T parvient à maintenir la fidélité des détails de l’image d’origine tout en intégrant le contexte à longue distance le contexte global Tout en montrant des images massives, de bout en bout, sur des GPU contemporains.
Résultats
Nous évaluons $ x $ t sur les tâches de référence difficiles qui s’étendent sur les lignes de base de vision par ordinateur bien établies à des tâches d’image grandes rigoureuses. En particulier, nous expérimentons avec Inaturalist 2018 Pour la classification des espèces à grains fins, xview3-sar pour la segmentation dépendante du contexte, et MS-COCO pour la détection.
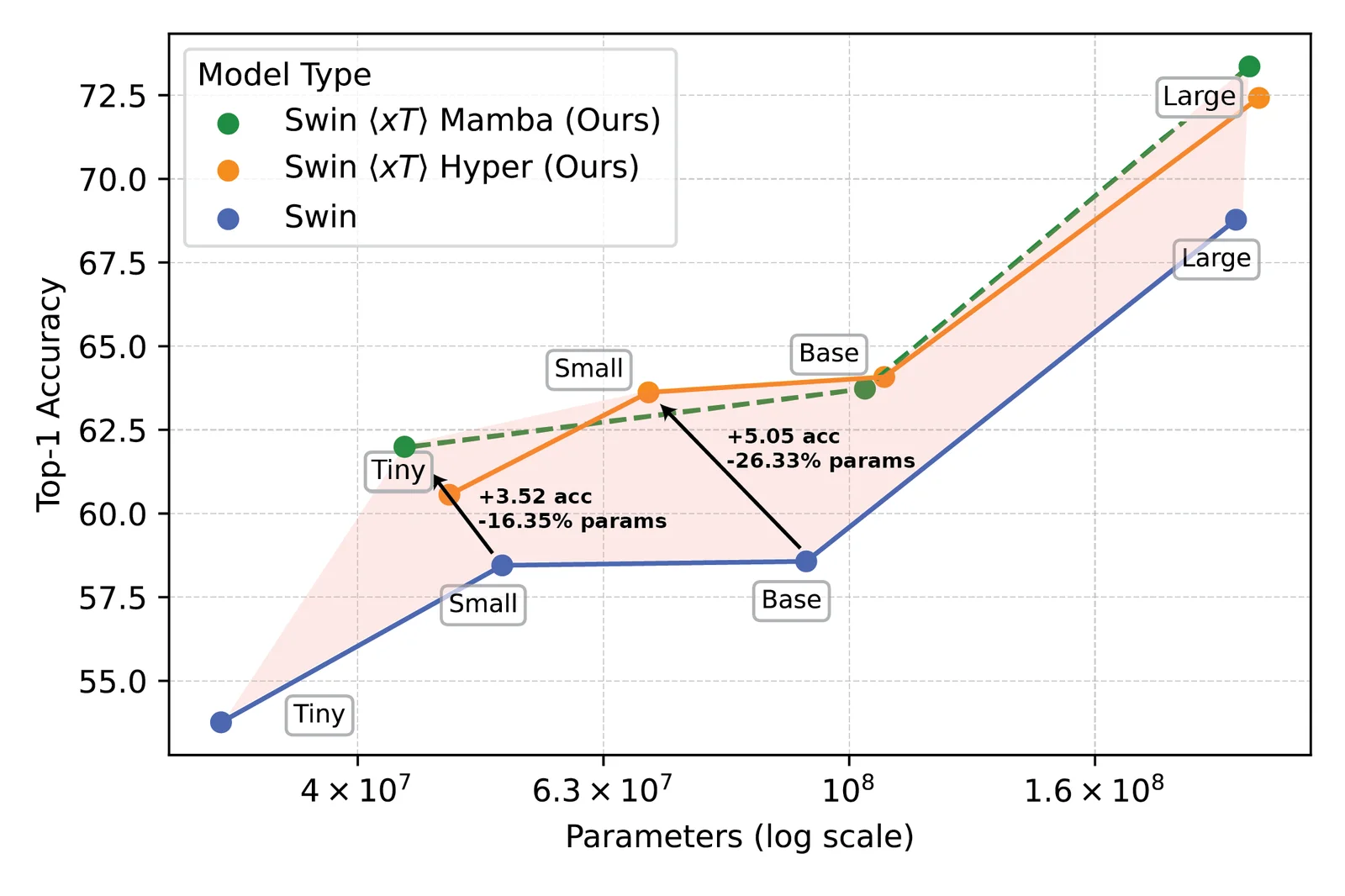
Des modèles de vision puissants utilisés avec $ x $ T ont établi une nouvelle frontière sur les tâches en aval telles que la classification des espèces à grain fin.
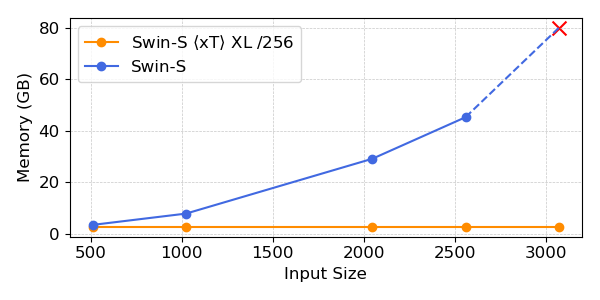
Nos expériences montrent que $ x $ T peut atteindre une précision plus élevée sur toutes les tâches en aval avec moins de paramètres tout en utilisant beaucoup moins de mémoire par région que les lignes de base de pointe*. Nous sommes en mesure de modéliser des images aussi grandes que 29 000 x 25 000 pixels de grande envergure sur 40 Go A100s tandis que les lignes de base comparables ne mangent pas de mémoire à seulement 2 800 x 2 800 pixels.
Des modèles de vision puissants utilisés avec $ x $ T ont établi une nouvelle frontière sur les tâches en aval telles que la classification des espèces à grain fin.
*Selon votre choix de contexte, comme Transformor-XL.
Pourquoi cela compte plus que vous ne le pensez
Cette approche n’est pas seulement cool; c’est nécessaire. Pour les scientifiques qui suivent le changement climatique ou les médecins diagnostiqués les maladies, c’est un changement de jeu. Cela signifie créer des modèles qui comprennent toute l’histoire, pas seulement des morceaux. Dans la surveillance environnementale, par exemple, être en mesure de voir à la fois les changements plus larges dans de vastes paysages et les détails de zones spécifiques peuvent aider à comprendre la situation dans son impact climatique. Dans les soins de santé, cela pourrait faire la différence entre attraper une maladie tôt ou non.
Nous ne prétendons pas avoir résolu tous les problèmes du monde en une seule fois. Nous espérons qu’avec $ x $ t, nous avons ouvert la porte à ce qui est possible. Nous entrons dans une nouvelle ère où nous n’avons pas à faire des compromis sur la clarté ou l’étendue de notre vision. $ x $ T est notre grand saut vers des modèles qui peuvent jongler avec les subtilités des images à grande échelle sans transpirer.
Il y a beaucoup plus de terrain à couvrir. La recherche évoluera, et espérons-le, notre capacité à traiter des images encore plus grandes et plus complexes. En fait, nous travaillons sur les suivis de $ x $ t qui élargiront davantage cette frontière.
En conclusion
Pour un traitement complet de ce travail, veuillez consulter le document sur arxiv. Le page du projet Contient un lien vers notre code et nos poids libérés. Si vous trouvez le travail utile, veuillez le citer comme ci-dessous:
@article{xTLargeImageModeling,
title={xT: Nested Tokenization for Larger Context in Large Images},
author={Gupta, Ritwik and Li, Shufan and Zhu, Tyler and Malik, Jitendra and Darrell, Trevor and Mangalam, Karttikeya},
journal={arXiv preprint arXiv:2403.01915},
year={2024}
}
Source link



