
Tiration de pandas et SQL ensemble pour une analyse efficace des données
- Intelligence Artificielle
 Noesis News
Noesis News- 0
- 32 minutes de lecture

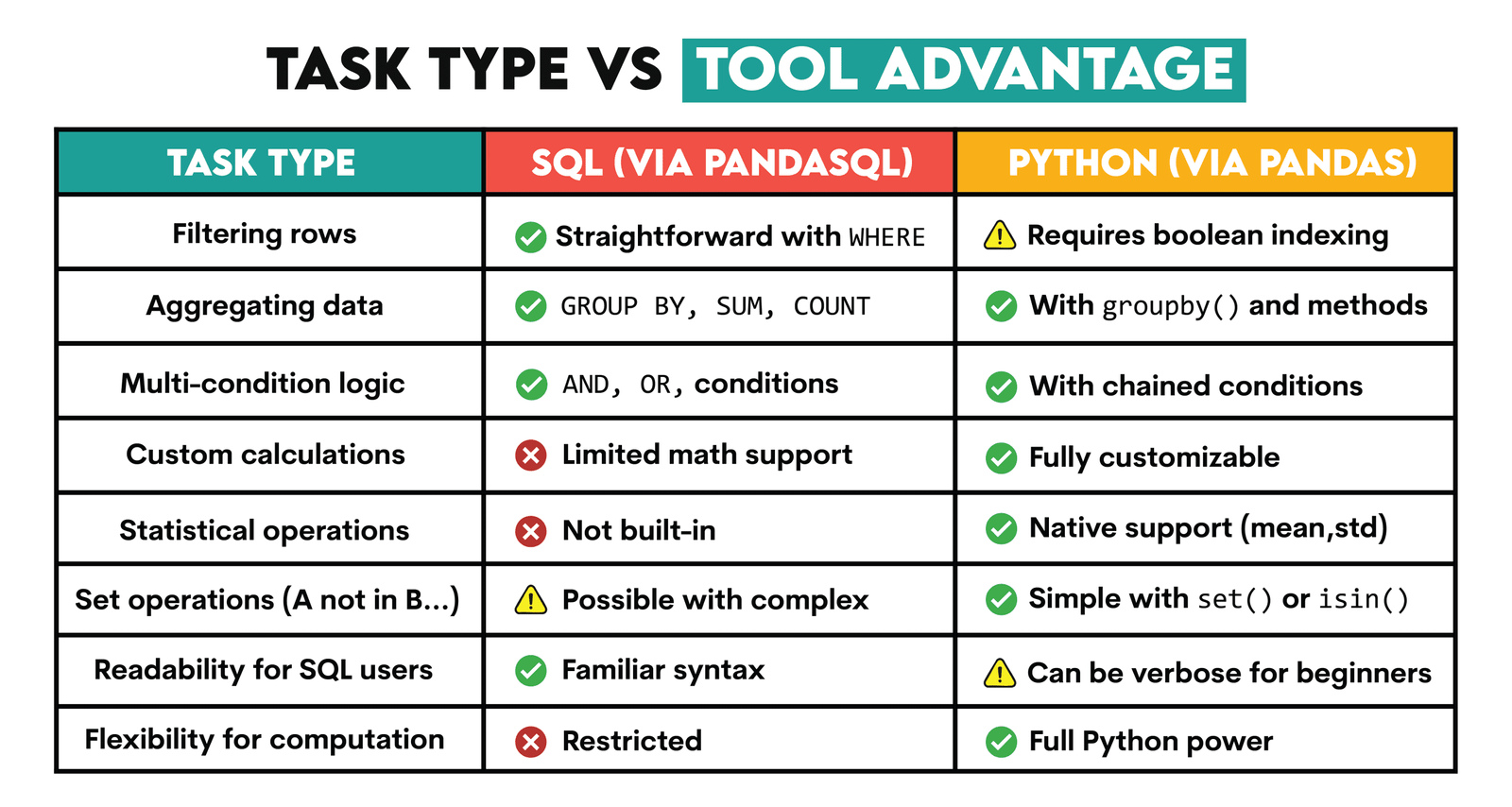
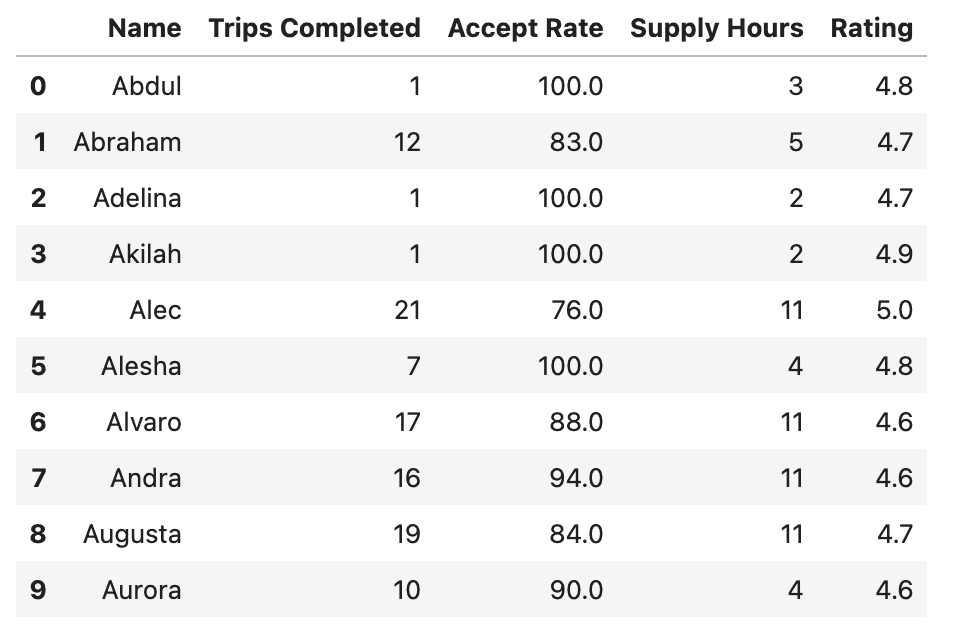
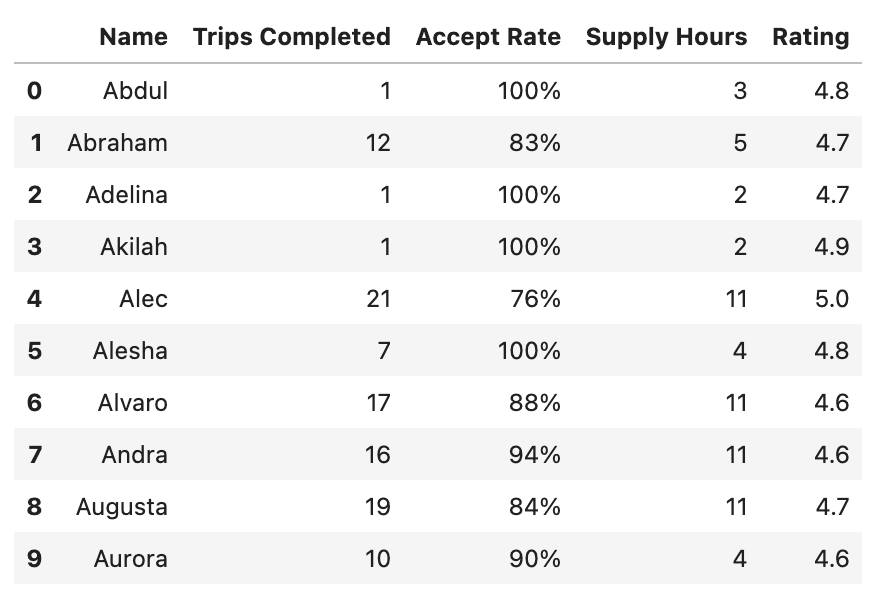

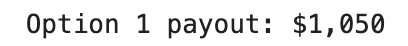
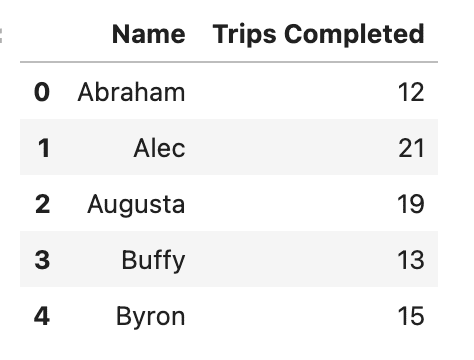


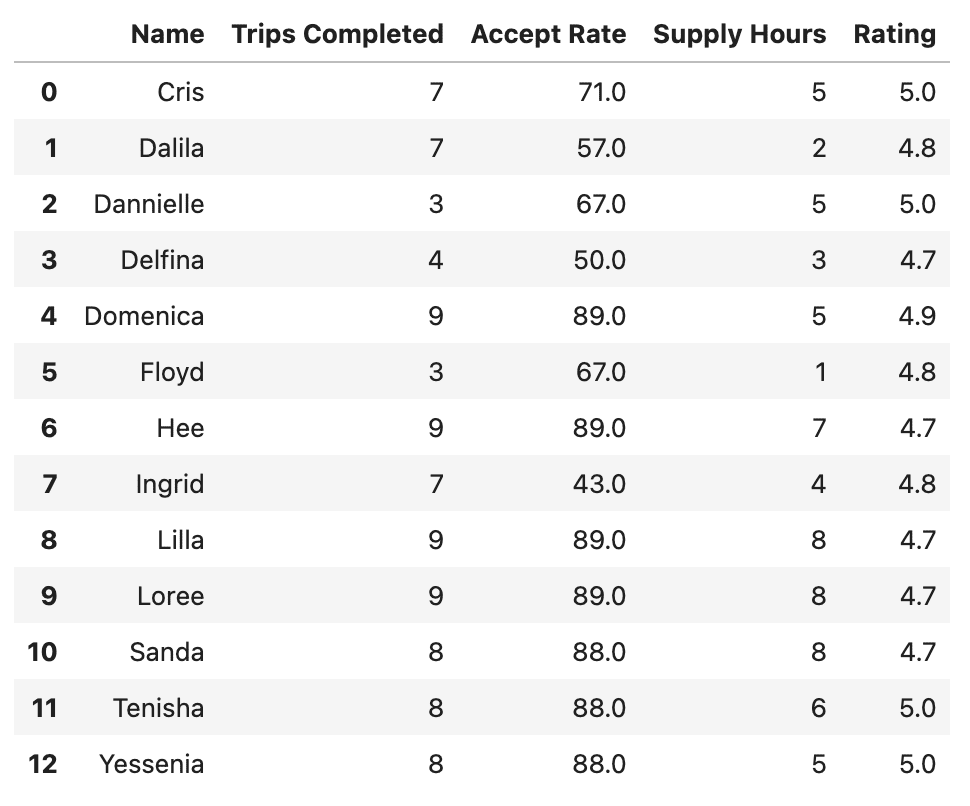
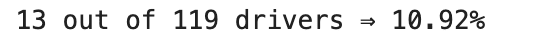
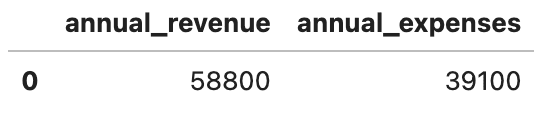
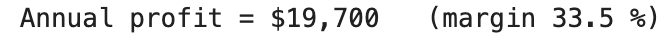

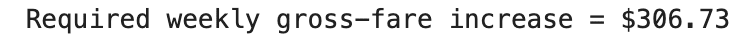
 Image de l’auteur | Toile
Image de l’auteur | ToileLes Pandas et SQL sont tous deux efficaces pour l’analyse des données, mais que se passe-t-il si nous pouvions fusionner leur pouvoir? Avec pandasqlvous pouvez écrire des requêtes SQL directement dans un cahier Jupyter. Cette intégration nous permet de mélanger la logique SQL avec Python pour une analyse efficace des données.
Dans cet article, nous utiliserons ensemble Pandas et SQL sur un projet de données d’Uber. Commençons!
# Qu’est-ce que Pandasql?
Pandasql peut être intégré à n’importe quelle dataframe via une mémoire Sqlite moteur, vous pouvez donc écrire du SQL pur dans un environnement Python.
# Avantages de l’utilisation de Pandas et SQL ensemble
SQL est utile pour filtrer facilement les lignes, agréger les données ou appliquer une logique multi-conditions.
Python, en revanche, propose des outils avancés d’analyse statistique et de calculs personnalisés, ainsi que des opérations basées sur des ensembles, qui s’étendent au-delà des capacités de SQL.
Lorsqu’il est utilisé ensemble, SQL simplifie la sélection des données, tandis que Python ajoute une flexibilité analytique.
# Comment exécuter Pandasql dans un cahier Jupyter?
Courir pandasql À l’intérieur d’un cahier Jupyter, commencez par le code suivant.
import pandas as pd
from pandasql import sqldf
run = lambda q: sqldf(q, globals())
Ensuite, vous pouvez exécuter votre code SQL comme ceci:
run("""
SELECT *
FROM df
LIMIT 10;
""")
Nous utiliserons le code SQL sans afficher le run fonctionnez à chaque fois dans cet article.
Voyons comment l’utilisation de SQL et Pandas ensemble fonctionne dans un projet réel d’Uber.
# Projet du monde réel: analyse des données de performance du pilote Uber
Image par auteur
En ce moment projet de donnéesUber nous demande d’analyser les données de performance du conducteur et d’évaluer les stratégies de bonus.
// Exploration et analyse des données
Maintenant, explorons les ensembles de données. Tout d’abord, nous chargerons les données.
// Chargement initial de l’ensemble de données
Chargeons l’ensemble de données en utilisant Just Pandas.
import pandas as pd
import numpy as np
df = pd.read_csv('dataset_2.csv')
// Explorer les données
Passons maintenant à l’ensemble de données.
La sortie ressemble à ceci:
Nous avons maintenant un aperçu des données.
Comme vous pouvez le voir, l’ensemble de données comprend le nom de chaque conducteur, le nombre de voyages qu’ils ont achevés, leur taux d’acceptation (c’est-à-dire le pourcentage de demandes de voyage acceptées), les heures d’approvisionnement totales (les heures totales passées en ligne) et leur note moyenne.
Vérifions les noms de colonne avant de démarrer l’analyse des données afin que nous puissions les utiliser correctement.
Voici la sortie.
Comme vous pouvez le voir, notre ensemble de données a cinq colonnes différentes et il n’y a pas de valeurs manquantes.
Répondons maintenant aux questions en utilisant SQL et Python.
# Question 1: Qui se qualifie pour l’option de bonus 1?
Dans la première question, on nous demande de déterminer le paiement du bonus total pour l’option 1, qui est:
50 $ pour chaque pilote en ligne au moins 8 heures, accepte 90% des demandes, termine 10 voyages et a une note de 4,7 ou mieux pendant le délai.
// Étape 1: Filtrage des pilotes éligibles avec SQL (Pandasql)
Dans cette étape, nous allons commencer à utiliser pandasql.
Dans le code suivant, nous avons sélectionné tous les pilotes qui remplissent les conditions du bonus de l’option 1 en utilisant le WHERE clause et le AND Opérateur pour lier plusieurs conditions. Pour apprendre à utiliser WHERE et ANDreportez-vous documentation.
opt1_eligible = run("""
SELECT Name -- keep only a name column for clarity
FROM df
WHERE `Supply Hours` >= 8
AND `Trips Completed` >= 10
AND `Accept Rate` >= 90
AND Rating >= 4.7;
""")
opt1_eligible
Voici la sortie.
// Étape 2: Finition en pandas
Après avoir filtré l’ensemble de données à l’aide de SQL avec pandasqlnous passons aux pandas pour effectuer des calculs numériques et finalisons l’analyse. Cette technique hybride, qui combine SQL et Python, améliore à la fois la lisibilité et la flexibilité.
Ensuite, en utilisant le code Python suivant, nous calculons le paiement total en multipliant le nombre de pilotes qualifiés (en utilisant len()) par le bonus de 50 $ par conducteur. Découvrez le documentation pour voir comment vous pouvez utiliser le len() fonction.
payout_opt1 = 50 * len(opt1_eligible)
print(f"Option 1 payout: ${payout_opt1:,}")
Voici la sortie.
# Question 2: Calcul du paiement total pour l’option de bonus 2
Dans la deuxième question, on nous demande de trouver le paiement du bonus total en utilisant l’option 2:
4 $ / voyage pour tous les conducteurs qui effectuent 12 voyages et ont une note de 4,7 ou mieux.
// Étape 1: Filtrage des pilotes éligibles avec SQL (Pandasql)
Tout d’abord, nous utilisons SQL pour filtrer pour les conducteurs qui répondent aux critères de l’option 2: terminer au moins 12 voyages et maintenir une note de 4,7 ou plus.
# Grab only the rows that satisfy the Option-2 thresholds
opt2_drivers = run("""
SELECT Name,
`Trips Completed`
FROM df
WHERE `Trips Completed` >= 12
AND Rating >= 4.7;
""")
opt2_drivers.head()
Voici ce que nous obtenons.
// Étape 2: terminer le calcul dans les pandas purs
Effectuons maintenant le calcul à l’aide de pandas. Le code calcule le bonus total en additionnant le Trips Completed colonne avec sum() puis multiplier le résultat par le bonus de 4 $ par voyage.
total_trips = opt2_drivers("Trips Completed").sum()
option2_bonus = 4 * total_trips
print(f"Total trips: {total_trips}, Option-2 payout: ${option2_bonus}")
Voici le résultat.
# Question 3: Identification des conducteurs qui se qualifient pour l’option 1 mais pas l’option 2
Dans la troisième question, on nous demande de compter le nombre de conducteurs qui se qualifient pour l’option 1 mais pas pour l’option 2.
// Étape 1: Construire deux tables d’éligibilité avec SQL (Pandasql)
Dans le code SQL suivant, nous créons deux ensembles de données: un pour les pilotes qui répondent aux critères de l’option 1 et un autre pour ceux qui répondent aux critères de l’option 2.
# All Option-1 drivers
opt1_drivers = run("""
SELECT Name
FROM df
WHERE `Supply Hours` >= 8
AND `Trips Completed` >= 10
AND `Accept Rate` >= 90
AND Rating >= 4.7;
""")
# All Option-2 drivers
opt2_drivers = run("""
SELECT Name
FROM df
WHERE `Trips Completed` >= 12
AND Rating >= 4.7;
""")
// Étape 2: Utilisation de Python Set Logic pour repérer la différence
Ensuite, nous utiliserons Python pour identifier les pilotes qui apparaissent dans l’option 1 mais pas dans l’option 2, et nous utiliserons l’ensemble opérations pour ça.
Voici le code:
only_opt1 = set(opt1_drivers("Name")) - set(opt2_drivers("Name"))
count_only_opt1 = len(only_opt1)
print(f"Drivers qualifying for Option 1 but not Option 2: {count_only_opt1}")
Voici la sortie.
En combinant ces méthodes, nous tirons partis de SQL pour le filtrage et la logique définie de Python pour comparer les ensembles de données résultants.
# Question 4: Trouver des conducteurs à faible performance avec des notes élevées
Dans la question 4, on nous demande de déterminer le pourcentage de conducteurs qui ont terminé moins de 10 voyages, avaient un taux d’acceptation inférieur à 90% et maintenaient toujours une note de 4,7 ou plus.
// Étape 1: Tirer le sous-ensemble avec SQL (Pandasql)
Dans le code suivant, nous sélectionnons tous les pilotes qui ont terminé moins de 10 voyages, avons un taux d’acceptation inférieur à 90% et détiennent une note d’au moins 4,7.
low_kpi_df = run("""
SELECT *
FROM df
WHERE `Trips Completed` < 10
AND `Accept Rate` < 90
AND Rating >= 4.7;
""")
low_kpi_df
Voici la sortie.
// Étape 2: Calcul du pourcentage en pandas simples
Dans cette étape, nous utiliserons Python pour calculer le pourcentage de ces conducteurs.
Nous divisons simplement le nombre de conducteurs filtrés par le nombre total de conducteurs, puis multiplions par 100 pour obtenir le pourcentage.
Voici le code:
num_low_kpi = len(low_kpi_df)
total_drivers = len(df)
percentage = round(100 * num_low_kpi / total_drivers, 2)
print(f"{num_low_kpi} out of {total_drivers} drivers ⇒ {percentage}%")
Voici la sortie.
# Question 5: Calcul du bénéfice annuel sans s’associer à Uber
Dans la cinquième question, nous devons calculer le revenu annuel d’un chauffeur de taxi sans s’associer à Uber, sur la base des paramètres de coût et de revenus donnés.
// Étape 1: Tirer les revenus annuels et les dépenses avec SQL (Pandasql)
En utilisant SQL, nous calculons d’abord les revenus annuels des tarifs quotidiens et soustrayons les dépenses pour le gaz, le loyer et l’assurance.
taxi_stats = run("""
SELECT
200*6*(52-3) AS annual_revenue,
((200+500)*(52-3) + 400*12) AS annual_expenses
""")
taxi_stats
Voici la sortie.
// Étape 2: dériver le profit et la marge avec les pandas
À l’étape suivante, nous utiliserons Python pour calculer le profit et la marge que les conducteurs obtiennent lorsqu’ils ne s’associent pas à Uber.
rev = taxi_stats.loc(0, "annual_revenue")
cost = taxi_stats.loc(0, "annual_expenses")
profit = rev - cost
margin = round(100 * profit / rev, 2)
print(f"Revenue : ${rev:,}")
print(f"Expenses : ${cost:,}")
print(f"Profit : ${profit:,} (margin: {margin}%)")
Voici ce que nous obtenons.
# Question 6: Calcul de l’augmentation des tarifs requis pour maintenir la rentabilité
Dans la sixième question, nous supposons que le même conducteur décide d’acheter une voiture de ville et de s’associer à Uber.
Les dépenses de gaz augmentent de 5%, l’assurance diminue de 20% et les coûts de location sont éliminés, mais le conducteur doit couvrir le coût de 40 000 $ de la voiture. On nous demande de calculer combien les tarifs bruts hebdomadaires de ce conducteur doivent augmenter au cours de la première année pour rembourser la voiture et maintenir la même marge bénéficiaire annuelle.
// Étape 1: Construire la nouvelle pile de dépenses d’un an avec SQL
Dans cette étape, nous utiliserons SQL pour calculer les nouvelles dépenses d’un an avec du gaz et de l’assurance ajustés et sans frais de location, plus le coût de la voiture.
new_exp = run("""
SELECT
40000 AS car,
200*1.05*(52-3) AS gas, -- +5 %
400*0.80*12 AS insurance -- –20 %
""")
new_cost = new_exp.sum(axis=1).iloc(0)
new_cost
Voici la sortie.
// Étape 2: Calcul de l’augmentation hebdomadaire des tarifs avec les pandas
Ensuite, nous utilisons Python pour calculer combien le conducteur doit gagner par semaine pour préserver cette marge après avoir acheté la voiture.
# Existing values from Question 5
old_rev = 58800
old_profit = 19700
old_margin = old_profit / old_rev
weeks = 49
# new_cost was calculated in the previous step (54130.0)
# We need to find the new revenue (new_rev) such that the profit margin remains the same:
# (new_rev - new_cost) / new_rev = old_margin
# Solving for new_rev gives: new_rev = new_cost / (1 - old_margin)
new_rev_required = new_cost / (1 - old_margin)
# The total increase in annual revenue needed is the difference
total_increase = new_rev_required - old_rev
# Divide by the number of working weeks to get the required weekly increase
weekly_bump = round(total_increase / weeks, 2)
print(f"Required weekly gross-fare increase = ${weekly_bump}")
Voici ce que nous obtenons.
# Conclusion
Rassembler les forces de SQL et Python, principalement à travers pandasqlnous avons résolu six problèmes différents.
SQL aide à filtrer rapidement et à résumer les ensembles de données structurés, tandis que Python est bon dans le calcul avancé et la manipulation dynamique.
Tout au long de cette analyse, nous avons exploité les deux outils pour simplifier le flux de travail et rendre chaque étape plus interprétable.
Nate Rosidi est un scientifique des données et en stratégie de produit. Il est également professeur auxiliaire qui enseigne l’analyse et est le fondateur de Stratascratch, une plate-forme aidant les scientifiques des données à se préparer à leurs entretiens avec de véritables questions d’entrevue de grandes entreprises. Nate écrit sur les dernières tendances du marché de la carrière, donne des conseils d’entrevue, partage des projets de science des données et couvre tout SQL.
Source link



